


The Challenge to Create a Pandemic Simulator



Life at Sony AI
March 3, 2021
The thing I like most about working at Sony AI is the quality of the projects we're working on, both for their scientific challenges and for their potential for improving the world. What could be more exciting than magnifying human imagination and creativity? Or than developing new AI technologies for social good?
Motivated by the devastating COVID-19 pandemic, much of the scientific community, across numerous disciplines, is currently focused on developing safe, quick, and effective methods to prevent the spread of biological viruses, or to otherwise mitigate the harm they cause. These methods include vaccines, treatments, public policy measures, economic stimuli, and hygiene education campaigns. Governments around the world are now faced with high-stakes decisions regarding which measures to enact at which times, often involving trade-offs between public health and economic resiliency. When making these decisions, governments often rely on epidemiological models that predict and project the course of the pandemic.
Due to the pressing need to develop more reliable models, as well as the opportunity to apply reinforcement learning to optimize government policies, my team at Sony AI decided very early on in the pandemic to explore the extent to which our AI expertise could be of use. And we believe this project aligns squarely with our core values of diversity, transparency, and especially social good.
The opportunity
During the Spring of 2020, I regularly attended the group meetings of The UT Austin COVID-19 Modeling Consortium, led by world-renowned epidemiologist Prof. Lauren Meyers, who is a colleague of mine at The University of Texas at Austin. At these meetings, I learned a lot about the state-of-the-art in epidemiology, including both the strengths and weaknesses of current models.
I quickly realized that the challenge of mitigating the spread of a pandemic while maximizing personal freedom and economic activity is fundamentally a sequential decision-making problem. When should schools be closed and for how long? When should capacity limits and social distancing restrictions be imposed at grocery stores, restaurants, salons, office buildings, etc., and under what conditions should these restrictions be relaxed? The measures enacted on one day affect the challenges to be addressed on future days. As such, Markov Decision Processes (MDPs), which maintain a current state that captures all relevant historical observations, are appropriate as a basis for policy optimization. Since MDPs are also the formalism typically used to model Reinforcement Learning (RL) problems, it was natural to consider possible connections between the two - especially since our team at Sony AI is built around some of the top worldwide experts on RL.
As conducting machine learning experiments requires data, and, experimenting with pandemic interventions on human subjects in the real world isn't feasible for obvious reasons, an epidemiological model that accurately captures the spread of the pandemic as well as the effects of government measures was a critical requirement. But it seemed that no existing epidemiological simulator had the resolution to support learning of RL-based policies to optimize the decisions on what regulations to impose that governments are currently struggling with.
In more detail, epidemiological models differ based on the level of granularity at which they track individuals and their disease states. "Compartmental" models group individuals of similar disease states together, assume all individuals within a specific compartment to be homogeneous, and only track the flow of individuals between compartments. While relatively simplistic, these models have been used for decades and continue to be useful for both retrospective studies and forecasts.
However, the commonly used macroscopic (or mass-action) compartmental models are less predictive when outcomes depend on the characteristics of heterogeneous individuals. In such cases, network models and agent-based models may be more useful predictors. Network models encode the relationships between individuals as static connections in a contact graph along which the disease can propagate. Conversely, agent-based simulations explicitly track individuals, their current disease states, and their interactions with other agents over time. Agent-based models allow one to model as much complexity as desired---even to the level of simulating individual people and locations---and thus enable one to model people's interactions at offices, stores, schools, etc. Because of their increased detail, they enable one to study the hyper-local interventions that governments consider when setting policy.
I therefore saw the opportunity to develop a novel, open-source, agent-based simulator that has the level of details needed to allow us to apply RL to optimize dynamic government intervention policies, and to use it to increase our understanding of how best to mitigate the spread of pandemics.
What we did
When I pitched this opportunity to the team, two of our team members, Varun Kompella and Roberto Capobianco, stepped up enthusiastically to lead the charge.
-

Varun Kompella -

Roberto Capobianco
In collaboration with Prof. Meyers' team and student at UT Austin, as well as with Prof. Guni Sharon's group at Texas A&M, over the course of several months we:
- Introduced PandemicSimulator, a novel
open-source agent-based simulator that models the interactions
between individuals at specific locations within a community. PandemicSimulator models realistic effects such
as testing with false positive/negative rates, imperfect public adherence to social distancing measures, contact
tracing, and variable spread rates among infected individuals. Crucially, PandemicSimulator models community
interactions at a level of detail that allows the spread of the disease to be an emergent property of people's
behaviors and the government's policies. An interface with OpenAI Gym is provided to enable support for standard RL
libraries.
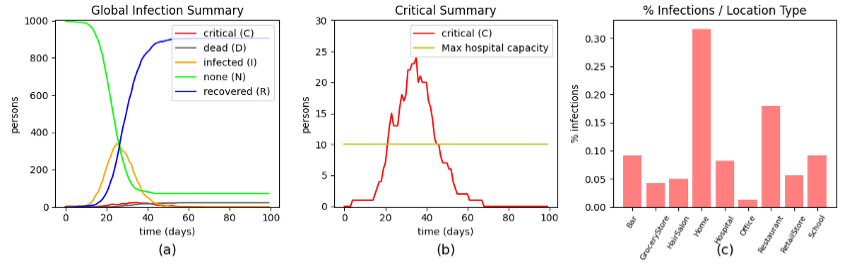
Figure: A single run of the simulator with no government restrictions, showing (a) the global infection summary over time (b) the number of people in critical condition, and (c) the percentage of infection spread at each location type in the simulator.
A video illustrating the emerging infection spread over a 180-day time period in the simulator is shown here:
- Demonstrated that a reinforcement learning algorithm can indeed identify a policy that outperforms a range of
reasonable baselines within this simulator
- Analyzed the resulting learned policy, which may provide insights regarding the relative efficacy of past and
potential future pandemic mitigation policies
- Used PandemicSimulator to evaluate and test a novel Hidden Markov Model that uses tests and contact tracing data to learn and update the people in a community who are currently most likely to be infected.
Our contributions are fully documented in two papers:
Reinforcement Learning for Optimization of COVID-19 Mitigation Policies
Varun
Kompella, Roberto Capobianco, Stacy Jong, Jonathan Browne, Spencer Fox, Lauren Meyers, Peter Wurman, and Peter Stone.
Reinforcement Learning for Optimization of COVID-19 Mitigation Policies. In AAAI Fall Symposium on AI for Social Good,
November 2020.
Multiagent Epidemiologic Inference through Realtime Contact Tracing
Guni Sharon,
James Ault, Peter Stone, Varun Kompella, and Roberto Capobianco. Multiagent Epidemiologic Inference through Realtime
Contact Tracing. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems
(AAMAS 2021), May 2021.
While the true measure of any resulting policies would be how well they perform in the real world (which for obvious reasons is not something we are able to experiment with at this stage of the research), our research has demonstrated the potential power of RL in an agent-based simulator, and may serve as an important first step towards real-world adoption.
What's next?
At Sony AI, we continue to maintain PandemicSimulator, and to look for opportunities to use it to increase our understanding of epidemiological modeling and response. Students at UT Austin and Texas A&M are contributing to its ongoing development, and we welcome contributions from the research community at large.
Of course we hope that there will not be another pandemic similar to COVID-19 anytime soon. But if there is, we hope that our research at Sony AI will play a role in ensuring that the world is much better prepared to respond quickly and effectively!
If you're interested in further details, you can see a 10-minute presentation I gave on this PandemicSimulator at NeurIPS 2020.
Dr. Peter Stone
Executive Director, Sony AI America
Dr. Peter Stone is the Executive Director of Sony AI America. He is also the founder and director of the Learning Agents Research Group (LARG) within the Artificial Intelligence Laboratory in the Department of Computer Science at The University of Texas at Austin, as well as associate department chair and Director of Texas Robotics and a co-founder of Cogitai. His main research interest in AI is understanding how it can best create complete intelligent agents. He considers adaptation, interaction, and embodiment to be essential capabilities of such agents. Thus, his research focuses mainly on machine learning, multiagent systems, and robotics. To him, the most exciting research topics are those inspired by challenging real-world problems. He believes that complete successful research includes both precise, novel algorithms and fully implemented and rigorously evaluated applications. His application domains have included robot soccer, autonomous bidding agents, autonomous vehicles, and human-interactive agents.
Dr. Roberto Capobianco
Research Scientist
Dr. Roberto Capobianco is a Research Scientist at Sony AI and Assistant Professor at Sapienza University of Rome, with both academic and industrial expertise in artificial intelligence and robotics. His main research interests lie at the edge between reinforcement learning, robotics and explainability in AI. He obtained his PhD from Sapienza University of Rome working on the generation and learning of semantic driven robot behaviors, and he has been a Research Scholar at the Robotics Institute of the Carnegie Mellon University (Pittsburgh, USA).
Dr. Varun Kompella
Research Scientist
Dr. Varun Kompella is currently a research scientist at SonyAI. He earned his Masters of Science in informatics with specialization in graphics, vision and robotics from Institut Nationale Polytechnique de Grenoble (INRIA Grenoble), and a PhD degree from Università della Svizzera Italiana (IDSIA Lugano), Switzerland, working with Prof. Juergen Schmidhuber. In his thesis work he developed algorithms that use the slowness principle for driving exploration in reinforcement learning agents. After completing his PhD, he worked as a postdoctoral researcher at the Institute for Neural Computation (INI), Germany. His research contributions led to several publications in peer-reviewed journals and conference proceedings.
Latest Blog

April 3, 2024 | Events
That’s A Wrap: Sony AI Ends Fiscal Year 2023 with SXSW, Two New Published Articl…
The past year marked a period of remarkable creativity, innovation, and excitement for Sony AI as it advanced its mission to research and develop AI that augments, and works in har…

March 29, 2024 | Life at Sony AI
Celebrating the Women of Sony AI: Sharing Insights, Inspiration, and Advice
In March, the world commemorates the accomplishments of women throughout history and celebrates those of today. The United States observes March as Women’s History Month, while man…

March 26, 2024 | AI Ethics
When Privacy and Fairness Collide: Reconciling the Tensions Between Privacy and …
Invisibility is sometimes thought of as a superpower. People often equate online privacy with selective invisibility, which sounds desirable because it potentially puts them in con…

