
At NeurIPS 2024, Sony AI is set to showcase two new research explorations into methods for image generation: GenWarp and PaGoDA. These two research papers highlight advancements in creating realistic images and novel viewpoints from existing data, promising to make 3D visual experiences and high-resolution content more accessible and efficient. Accepted into one of the world's most prestigious AI conferences, these methods represent a step forward in generative modeling, offering fresh solutions to long-standing scientific challenges in the field.
GenWarp allows for the creation of new perspectives from a single image. Meanwhile, PaGoDA tackles the challenge of generating high-resolution images by progressively growing the resolution of a low-resolution model. Both approaches explore ways to make high-quality visual content generation faster, more computationally efficient, and more adaptable across potential applications, such as gaming and virtual reality to AI-assisted design and film production.
By addressing the limitations of traditional methods—such as noisy depth maps, high computational costs, and the need for extensive retraining—these papers present scalable and versatile new solutions that could advance the way we think about computer vision and image synthesis.
Exploring GenWarp: A New Approach to Generating 3D Views from a Single Image
Imagine taking a photograph and being able to magically rotate the ensuing image around to see the scene from different angles. Traditional methods for achieving this struggle because they rely heavily on depth maps—like using a 3D blueprint of a scene. These depth maps can often be inaccurate, leading to distorted images when the view is changed. Think of it like trying to stretch a single snapshot into a three-dimensional experience: if the blueprint is flawed, the result can look jarring or unrealistic, and oftentimes humorous, too.
Enter GenWarp, a new research framework that approaches the problem differently. Instead of depending solely on these imperfect blueprints, GenWarp is like an artist who knows intuitively how to fill in the gaps and produce a believable view from various angles. It preserves the important details of the original scene while generating new perspectives, seamlessly.
GenWarp introduces a novel method for generating different viewpoints from a single image by combining generative warping with semantic-preserving techniques.

“Our approach eliminates the dependency on unreliable warped images and integrates semantic features from the source view, preserving the semantic details of the source view during generation,” the researchers explain.
It integrates the geometric warping process with generative capabilities in a unified framework, overcoming limitations seen in existing methods, such as noisy depth maps and loss of detail.
The Problem
Generating novel views from a single image is a complex task. Existing approaches have struggled with issues like:
- Noisy depth maps: These create artifacts in the warped images.
- Loss of details: When changing viewpoints, semantic details often get lost.
- In-the-wild images: Traditional warping-and-inpainting methods perform poorly on diverse, real-world images and complex scenes.
Challenges in the Field
- Handling Noisy Depth Maps:
When existing models use monocular depth estimation (MDE) to predict the 3D structure of an image, they often produce noisy depth maps. This leads to distortions in the final output that are hard to correct, the researchers explain. - Preserving Semantic Information:
Traditional methods struggle to maintain the details of the original image when warping to a new viewpoint, especially for significant changes in camera angles. - Dealing with Diverse Image Types:
Many approaches are only effective in controlled environments and fail to generalize to more challenging, real-world scenes.
The GenWarp Solution
GenWarp addresses these challenges through a unified framework that combines depth information with advanced generative techniques. The approach essentially decides which parts of the image can be warped based on existing information and which parts need to be generated from scratch.
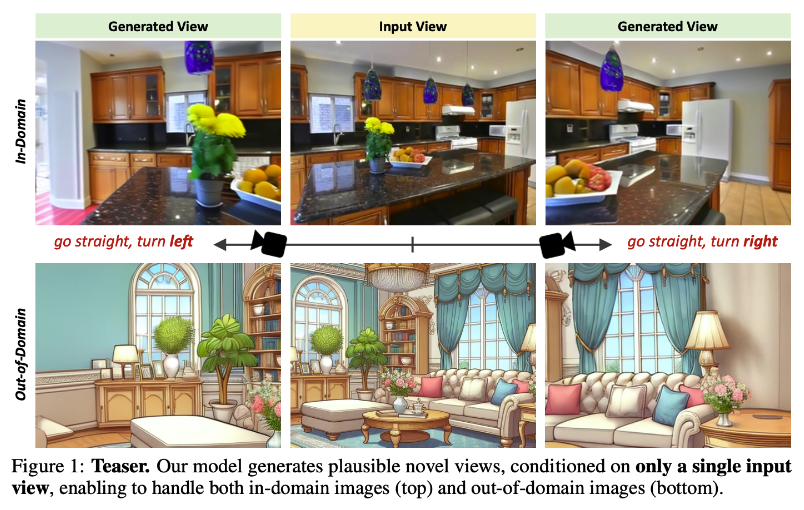
The researchers explain, that… “[b]y augmenting self-attention with cross-view attention, our method learns to balance between generating novel content and warping existing content, depending on the quality of the source image.”
By integrating geometric warping signals with self-attention mechanisms, GenWarp preserves the important features and details of the source image during the generation process.
Results
GenWarp has been tested across various scenarios, producing high-quality novel views even with difficult viewpoint changes.
“The results suggest that combining geometric warping signals with generative capabilities not only improves visual quality but also ensures better semantic consistency across views,” the researchers note.
It has outperformed traditional methods in both controlled (in-domain) and unpredictable (out-of-domain) environments.
Key findings:
- Superior Image Quality: Quantitative metrics like Fréchet Inception Distance (FID) and Peak Signal-to-Noise Ratio (PSNR) showed better scores for GenWarp compared to competing methods.
- Consistent Performance: The model remained robust across different image types, including AI-generated, cartoon-like, and real-world photos.
- Adaptability: GenWarp excelled in generating realistic perspectives even when there was little overlap between the original and desired views.
GenWarp represents a step forward in the field of computer vision and image generation, offering a promising approach to creating realistic and consistent novel views from a single image. Its ability to handle noisy depth maps, preserve semantic details, and perform well on diverse datasets opens up new possibilities for various applications.
As advances continue in this space, GenWarp could play a key role in making 3D experiences more accessible and visually stunning, setting a new standard for image synthesis in AI-driven applications.
PaGoDA: Revolutionizing High-Resolution Image Generation
Think of a skilled artist who starts with a rough sketch on a small canvas, gradually adding more detail as the canvas size expands. This is similar to how PaGoDA works for generating high-resolution images. Instead of retraining from scratch, it uses a pre-trained, low-resolution model as a starting point and progressively grows the image's resolution step by step. This approach avoids wasting time and resources, providing a smarter way to scale up while maintaining quality.
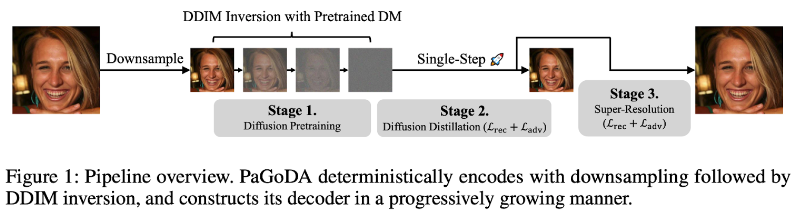
PaGoDA introduces a method for generating high-resolution images more efficiently by leveraging a low-resolution diffusion model as a base. By progressively increasing the resolution, it eliminates the need for retraining large models from scratch.
PaGoDA proposes a training pipeline to significantly reduce costs while achieving competitive quality with one-step generation:
Stage 1. (Pretraining) Train a Diffusion Model on downsampled data.
Stage 2. (Distillation) Distill the trained DM with DDIM inversion to a one-step generator.
Stage 3. (Super-Resolution) Progressively expand the generator for resolution upsampling.
The Problem: Enhancing Diffusion Model Efficiency
Diffusion models, renowned for generating realistic images, face limitations when scaling to higher resolutions while maintaining fast generation speeds. Traditional methods distill the diffusion model into a "student model" to accelerate generation; however, this ties the resolution of the student model to that of the teacher model, requiring extensive retraining to increase resolution. This process is resource-intensive and computationally demanding, limiting practical applications.
Challenges Faced and Solutions
Reducing Training Computational Costs Across Resolutions
Upscaling image resolution in diffusion models while maintaining fast generation typically requires high computational resources. PaGoDA addresses this by adopting a progressive approach to resolution growth.
The researchers explain, "PaGoDA efficiently downsamples high-resolution data, encodes the downsampled version into latent representations using pre-trained low-resolution diffusion models, and then trains a lightweight generator to decode it, overcoming the high-cost bottleneck of existing distillation models."
By gradually increasing resolution, PaGoDA enables one-step generation across resolutions with minimal training cost.
Ensuring Stability in Training
We utilize GANs to maintain high-generation quality across resolutions. "Our experiments indicate that PaGoDA preserves generation quality across resolutions without requiring extensive GAN stabilization techniques, supported by theoretical foundations," the researchers emphasize. PaGoDA maintains stability by freezing previously trained sections of the model while refining only the newest layers. This approach ensures stable and consistent performance across resolutions.
Parallel Yet Compatible Approach to Latent Diffusion Models
PaGoDA’s progressively growing decoder reduces training costs. It provides enhanced data compression, making it compatible with existing Latent Diffusion Models that use autoencoders for resolution compression. Furthermore, PaGoDA achieves generation speeds up to twice as fast as other single-step distilled latent diffusion models. The researchers note, “PaGoDA’s single-step generation bypasses the complexities of decoding latent representations back into pixel space, resulting in significantly faster image synthesis.”
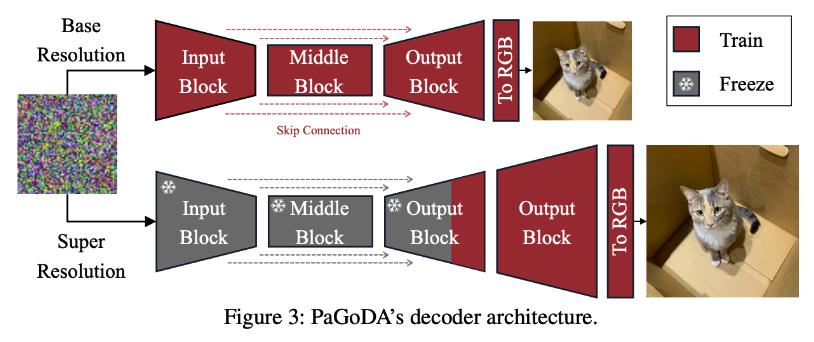
Why This Research Is Significant
PaGoDA offers a newly researched method that makes it easier to achieve high-resolution outputs without the usual computational costs. By using a low-resolution model as a base and expanding the image's resolution progressively, the process becomes more efficient and accessible. "Our method demonstrates that it is feasible to leverage a low-resolution diffusion model as a structured latent space encoder, extending the capabilities of existing distillation techniques," the researchers highlight, showcasing its potential to redefine image generation workflows.
Conclusion
The acceptance of papers introducing GenWarp and PaGoDA at NeurIPS 2024 marks new research advances in AI-driven image generation by addressing the limitations of traditional methods—such as high computational costs, and the need for extensive retraining—these approaches offer scalable, efficient, and high-quality solutions for generating realistic images in real-time and novel perspectives.
By setting new benchmarks in generative modeling, GenWarp and PaGoDA showcase Sony AI’s commitment to innovation and its mission to unleash human imagination with AI. As we look forward to further developments in this exciting field, these methods could open the doors for more research and discoveries into the quality and efficiency in AI-powered image synthesis.
Discover more additional research on the topic of AI for Creators:


