




New Research at ICCV 2025: Expanding the Boundaries of Vision and Generative AI
Imaging & Sensing
Sony AI
October 20, 2025
At ICCV 2025, Sony AI is presenting six new research contributions that advance both generative modeling and computer vision. From parameter-efficient fine-tuning, to rethinking how image sensors feed object detection models, to improving Vision Transformer efficiency at the edge, these works highlight our focus on making AI systems more efficient, and robust.
AI FOR CREATORS:
TITAN-Guide: Taming Inference-Time AligNment for Guided Text-to-Video Diffusion Models
Authors: Christian Simon, Masato Ishii, Akio Hayakawa, Zhi Zhong, Shusuke Takahashi, Takashi Shibuya, Yuki Mitsufuji
Diffusion models already excel at generating images and videos, but aligning them with specific prompts, such as, a style, an audio track, or an aesthetic, often requires heavy fine-tuning or memory-intensive steps. TITAN-Guide introduces a new way to guide text-to-video diffusion models efficiently.
Instead of relying on backpropagation, TITAN-Guide uses forward gradients: “a technique that allows models to follow guidance signals… without the burden of large memory overhead,” the researchers note. This could potentially enable creators and researchers to steer video generation toward desired outcomes, like synchronizing visuals with sound or applying a specific artistic style, without sacrificing quality or requiring extensive retraining.

Why It Matters
Guidance in T2V models often required a whopping 60–90 GB of GPU memory, making real-world use difficult. TITAN-Guide reduces memory use by nearly half while improving alignment quality. In the authors’ words, it “consistently outperformed existing methods in video quality and alignment.”
One could imagine that these efficiency gains suggest practical uses in media and entertainment, where stylized or audio-synced video could be produced at lower computational cost.

Results
Benchmarks such as VGG-Sound and TFG-1000 showed TITAN-Guide “consistently outperformed existing methods in video quality and alignment,” while reducing GPU memory usage by more than half, the authors explain.
Conclusion
By rethinking how guidance is applied during inference, TITAN-Guide makes controllable video generation more scalable and accessible.
Transformed Low-Rank Adaptation via Tensor Decomposition and Its Applications to Text-to-Image Models
Authors: Zerui Tao, Yuhta Takida, Naoki Murata, Qibin Zhao, Yuki Mitsufuji
Fine-tuning large text-to-image models often comes with massive computational costs. While Low-Rank Adaptation (LoRA) reduced this burden, it “may yield a high recovery gap compared to the full fine-tuning adaptations, especially for difficult tasks.”
Transformed Low-Rank Adaptation (TLoRA) introduces additional learnable modules on top of the original models, consisting of a full-rank transformation and a residual adaptation. This approach enables more flexible adaptation compared to conventional methods, including LoRA. Furthermore, the authors incorporate efficient tensor decompositions into the parameterization of these additional modules.

Why It Matters
This combination allows richer adaptations while keeping parameter counts low. “Our model is able to achieve desirable performances and ultra-parameter-efficiency simultaneously, e.g., fine-tuning SDXL with only 0.4M parameters,” the authors write.
These results point to potential broader accessibility. For example, enabling creative tools that adapt to sketches, outlines, or poses without requiring costly infrastructure.
Results
Across subject-driven and controllable generation tasks, TLoRA consistently improved prompt alignment, subject fidelity, and sample diversity while using fewer parameters.
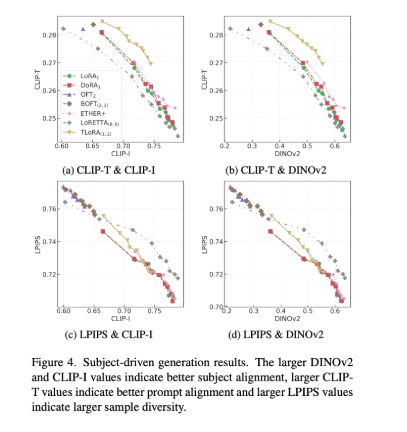
Conclusion
As the authors note, “This combination of transforms and residuals shows advantages in approximation and fine-tuning T2I models for different tasks.” TLoRA strengthens the toolkit for efficient personalization and controllability in generative AI.
AI SAAS:
Image Intrinsic Scale Assessment (IISA)
Authors: Vlad Hosu, Lorenzo Agnolucci, Daisuke Iso, Dietmar Saupe
Image quality assessment (IQA) methods typically measure how visual distortions affect perceived quality, but they often ignore how changes in image scale influence perception. At ICCV 2025, Sony AI researchers introduce Image Intrinsic Scale Assessment (IISA), a new framework for quantifying the scale at which an image reaches its highest perceived quality.
The authors define the Image Intrinsic Scale (IIS) as the largest downscaling ratio where an image appears at its best quality. Unlike resolution, which reflects the number of pixels, the intrinsic scale expresses the optimal balance between visible detail and the suppression of artifacts such as noise or blur. By predicting this value, IISA enables more precise measurement of perceptual quality across scales.
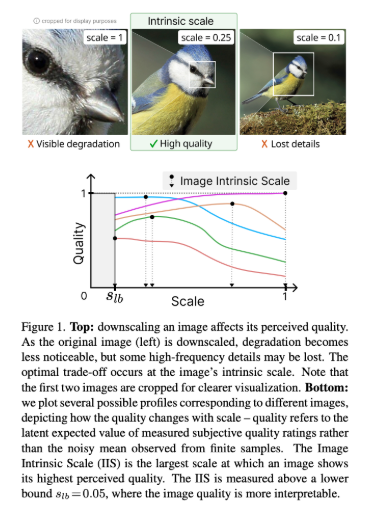
Why It Matters
Many existing Image Quality Assessment (IQA) methods aim to predict perceived image characteristics such as sharpness or distortion levels at a fixed image size, without considering how perceived quality changes with scale. IISA instead identifies the perceptual sweet spot — the scale at which an image appears its sharpest and most natural — offering a new foundation for evaluating image quality across different viewing conditions..
Results
Experiments on the IISA-DB dataset show that models trained with IISA achieve higher correlation with human quality judgments than existing no-reference image quality methods. The authors note that IISA captures subtle perceptual differences more effectively, offering finer-grained quality assessment across scales.
Conclusion
By quantifying the scale at which an image looks its best, IISA offers a new way to measure perceptual quality that moves beyond resolution or sharpness alone.
Beyond RGB: Adaptive Parallel Processing for RAW Object Detection
Authors: Shani Gamrian, Hila Barel, Feiran Li, Masakazu Yoshimura, Daisuke Iso
Most object detection models today use sRGB images (the processed pictures our eyes are meant to see) instead of the RAW data captured by sensors. But as the authors note, “while these operations improve aesthetics, they also introduce irreversible information loss.”
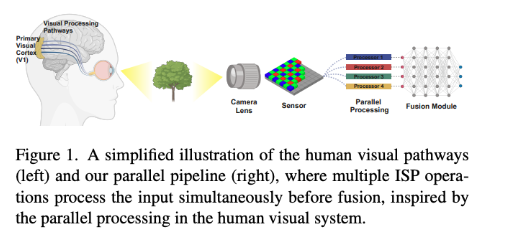
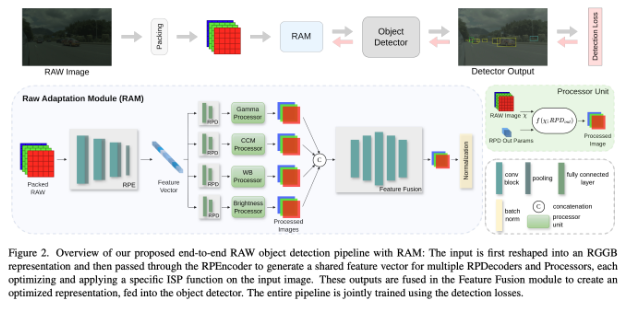
Beyond RGB proposes using RAW sensor data directly. The team introduces the Raw Adaptation Module (RAM), a pre-processing module inspired by the human visual system. “Instead of applying ISP operations sequentially, RAM processes multiple attributes in parallel and fuses them into a unified representation,” the authors explain.
Because RAM is trained end-to-end with the detection network, “it dynamically selects and weighs the most relevant features for each image, discarding unnecessary or potentially harmful functions.”
Why It Matters
By leveraging RAW data, RAM improves detection under conditions where RGB pipelines often fail. This robustness could be transformative for autonomous driving, where vehicles must recognize objects reliably in a variety of weather conditions, such as fog, rain, or night-time conditions. “RAW data has the potential to improve object detection beyond sRGB… especially in low-light and noisy environments,” the authors note.
Results
On seven RAW datasets, RAM achieved state-of-the-art performance:
- - +3–4% mAP gains over sRGB-based methods in low light.
- - “RAM remains remarkably stable, with only a marginal performance drop of 2.5% to 3.5%” in adverse weather, compared to a 6.6% to 9.9% drop for sRGB.”
- - Comparable or better accuracy with fewer parameters and lower latency.
Analysis further showed that “gamma correction is particularly effective for the ROD datasets, reflecting its role in tone mapping for HDR images.”
Conclusion
As the authors conclude, “RAM consistently outperforms state-of-the-art methods by a wide margin,” demonstrating that sensor-level data, paired with adaptive processing, can unlock a new frontier in machine vision.
Learning Hierarchical Line Buffer for Image Processing
Jiacheng Li, Feiran Li, Daisuke Iso
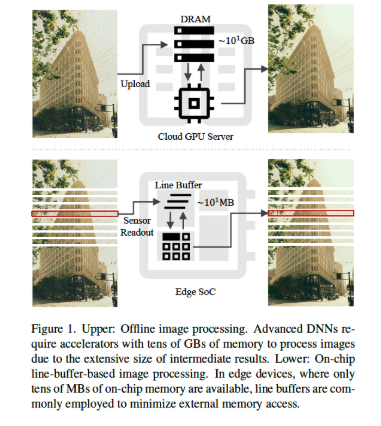
Many neural networks for image processing require large amounts of memory, making them difficult to deploy on resource-limited edge devices. On-chip processors often rely on line buffers, which only store a few rows of an image at a time, to minimize memory use. But most existing methods are not designed to take full advantage of this.
In Learning Hierarchical Line Buffer for Image Processing, the authors introduce a new neural network design that explicitly models both intra-line and inter-line correlations. As they explain: “to model intra-line correlations, we propose a progressive feature enhancement strategy… For inter-line correlation modeling, we introduce a hierarchical line buffer formulation.”
Why It Matters
This design allows networks to achieve strong performance while staying within the strict memory limits of edge hardware. “Our method achieves a superior trade-off between performance and memory efficiency… up to 1dB PSNR gain in RAW denoising at one-fifth of peak memory usage” (Abstract).
Inferred implication: This makes it especially promising for mobile photography and embedded vision systems, where both quality and efficiency are critical.
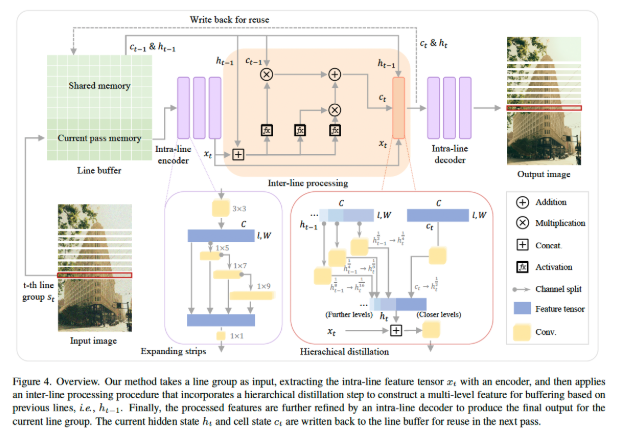
Results
On tasks like RAW denoising, Gaussian denoising, and super-resolution, the method consistently outperformed prior line-buffer approaches such as LineDL. For example, it achieved “a 1.04 dB gain… while using over six times fewer parameters” (p. 12).
Conclusion
By aligning neural architectures with the constraints of line-buffer processing, this work demonstrates a practical path toward high-quality, low-memory image processing on edge devices.
PPML:
MixA: A Mixed Attention Approach with Stable Lightweight Linear Attention to Enhance Efficiency of Vision Transformers at the Edge
Authors: Sabbir Ahmed, Jingtao Li, Weiming Zhuang, Chen Chen, Lingjuan Lyu
Vision Transformers (ViTs) have set state-of-the-art performance across classification, detection, and segmentation, but they remain difficult to deploy on edge devices due to heavy compute requirements. As the paper notes, “the attention layer consumes the majority of the inference time in ViT models, making it a critical bottleneck for efficient edge inference.”.
MixA addresses this bottleneck by strategically combining quadratic and linear attention. “MixA takes a pretrained ViT model and analyzes the significance of each attention layer, and selectively applies ReLU-based quadratic attention in the critical layers… To enhance efficiency, MixA selects the less critical layers and replaces them with our novel ReLU-based linear attention module called Stable Lightweight Linear Attention (SteLLA),” the researchers explain.
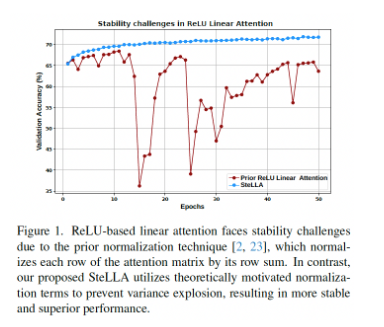
Why It Matters
By carefully balancing expressiveness and efficiency, MixA significantly accelerates ViTs while keeping accuracy nearly unchanged. As the researchers note, “MixA can improve the inference speed of the DeiT-T model by 22% on the Apple M1 chip with only ∼0.1% accuracy loss,” and this makes MixA especially promising in environments where models need to run efficiently on mobile or embedded devices without compromising quality.
Results
Experiments on ImageNet-1K, COCO, and ADE20K show consistent improvements:
- For classification, MixA-DeiT-T achieved a 22% speedup on Apple M1 with just 0.1% accuracy drop (Table 2).
- For segmentation, MixA-Swin-T improved execution speed by over 28% on Apple M1 while maintaining or improving mIoU (Table 3).
- For detection, MixA achieved 12–30% speedups across edge devices with comparable mAP (Table 4).
The authors highlight that “SteLLA outperforms the prior linear attention approaches,” delivering a 4.66% gain over comparable methods like CosFormer (Table 5).
Conclusion
MixA enhances the efficiency of Vision Transformer models while achieving performance comparable to traditional, resource-intensive Softmax-based quadratic attention. By mixing quadratic and lightweight linear attention in a targeted way, MixA offers a practical path to bringing ViTs onto edge devices at scale.
In Closing…
From controllable video generation, to efficient fine-tuning of diffusion models, to RAW-level object detection, edge-ready Transformers, perceptual image quality metrics, and memory-efficient line-buffer design—Sony AI’s contributions at ICCV 2025 showcase the breadth of innovation across vision research. Together, these works reflect our commitment to building AI systems that are not only state-of-the-art but also practical, efficient, and aligned with human perception.
Latest Blog

March 5, 2026 | Imaging & Sensing, Sony AI
On Writing The Principles of Diffusion Models, A Q&A With Sony AI Researcher, Je…
IntroductionDiffusion models have become a go-to approach for high-quality generation; however, the field can be challenging to navigate once the paper titles and acronyms begin to…

March 2, 2026 | Sony AI
Advancing AI: Highlights from February
February at Sony AI was defined by momentum across global stages, research publications, and conversations about how AI moves from theory into practice.This month spanned responsib…

February 2, 2026 | Sony AI
Advancing AI: Highlights from January
January set the tone for the year ahead at Sony AI, with work that spans foundational research, scientific discovery, and global engagement with the research community.This month’s…

