




Protecting Creator’s Rights in the Age of AI
Sony AI
December 15, 2025
The rise of artificial intelligence technologies that can generate songs and mimic musical styles and artists has led to a surge in AI music content with unclear origins, prompting concerns about authenticity, fairness and ownership. Much of this output is being created with tools trained on unlicensed datasets that provide no credit or compensation to the rightsholders whose work unpins these models.
Sony AI’s researchers are working to develop the blueprints for AI technologies that can use the unique power of artificial intelligence to help artists and rights holders understand when and how their work appears in generated music, and enable the creation of tools that support attribution and protection at scale.
Three new research papers accepted to NeurIPS, ICML, and INTERSPEECH 2025, led by Joan Serrà and his collaborators at Sony AI, are focused on musical integrity in the age of machine learning, exploring attribution, recognition, and protection.
This research is part of a growing body of work exploring how AI can unlearn what doesn’t belong to it, how connections between musical segments can be identified, and how effective current audio authentication methods are in verifying a track’s integrity after typical alterations, like compression or file conversion.
Learning to Unlearn: Tracing AI’s Musical DNA
The first challenge is attribution—understanding which training data influenced what an AI system creates. When an unlicensed generative model composes a new song from a text prompt, it doesn't include any record of attribution. But Sony AI’s researchers believe it can still be determined.
In “Large-Scale Training Data Attribution for Music Generative Models via Unlearning,” accepted at the NeurIPS 2025 Creative AI Track, Yuki Mitsufuji, Woosung Choi, Junghyun Koo, Kin Wai Cheuk, WeiHsiang Liao, and Joan Serrà propose a way to make attribution traceable in generative music models. Their approach, leveraging unlearning techniques, identifies which specific audio files in a model’s training data most influenced a generated piece of music.
To test this, the researchers trained a latent diffusion model or Diffusion Transformer(DiT)-based text-to-music generation model on an internal dataset of 115,000 high-quality music tracks spanning a diverse range of genres and styles. They then used unlearning algorithms to measure how much each training example contributed to the generated music—comparing changes in the model’s behavior when specific samples were selectively “forgotten.”
According to the authors, “to our knowledge, this is the first work that explores attribution on a text-to-music DiT trained on a large dataset of diverse musical styles.” Their findings show that unlearning-based attribution can be scaled effectively to large music models and data sets, creating what they describe as “a framework for applying unlearning-based attribution to music generation models at scale.”
In practice, this means unlearning could help music platforms and AI developers trace the creative DNA of AI-generated songs—revealing which human works shaped a machine’s composition. It’s a step toward accountability in a landscape where influence is often invisible. By showing what happens when models forget, Sony AI’s researchers hope to help recognize the works of the original artists.
Sony AI’s research also explores proactive, technical solutions (like music matching and watermarking) that have the potential to protect creators’ rights without limiting innovation.
Listening for Connections: Mapping Musical Relationships
Attribution identifies the source of influence in generated music and sound; recognition maps the relationships between works. Two songs may not be identical, but they might still share a melody, rhythm, or phrasing that links them across eras or items in a given catalog.
That’s the focus of “Supervised Contrastive Learning from Weakly-Labeled Audio Segments for Musical Version Matching,” presented at ICML 2025 by Joan Serrà, R. Oguz Araz, Dmitry Bogdanov, and Yuki Mitsufuji.
As the authors explain, “When two audio tracks contain different renditions of the same musical piece, they are considered musical versions.” Yet detecting those versions is difficult. Traditional approaches compare entire tracks, missing the subtler connections that occur at the segment level, such as small moments of similarity in harmony, phrasing, or instrumentation.
The method developed by the Sony AI team called CLEWS (Contrastive Learning from Weakly-Labeled Segments) solves this by learning from short snippets—about 20 seconds each—instead of whole songs. By comparing small fragments across large datasets, CLEWS learns to recognize when two pieces feel like versions of each other, even if they sound different.
The researchers write: “We not only achieve state-of-the-art results in the standard track-level evaluation, but we also obtain a breakthrough performance in a segment-level evaluation.”
This matters because musical similarity isn’t binary. Two pieces may share motifs, chord progressions, or harmonic contours that reflect influence rather than imitation. CLEWS helps quantify those nuances, offering a more sophisticated way to trace creative lineage, one that could support music discovery, cultural preservation, and fair attribution alike. Beyond creative discovery, this kind of fine-grained similarity detection could also support copyright protection and content monitoring systems—helping identify near-duplicates or unauthorized versions that might slip past traditional matching tools.
The authors also note that because their approach addresses “the generality of the challenges… it may find utility in domains beyond audio or musical version matching.” That versatility points to a broader insight: contrastive learning (teaching models to notice what’s shared and what’s distinct) isn’t just about matching versions; it’s about learning to listen contextually.
Keeping the Signal Intact: Testing Music’s Resilience
If unlearning helps us trace origins and contrastive learning helps us recognize relationships, the next step is protection. Protection means ensuring music can carry its identity intact through digital transformation.
In “A Comprehensive Real-World Assessment of Audio Watermarking Algorithms: Will They Survive Neural Codecs?”, presented at INTERSPEECH 2025, Yigitcan Özer, Woosung Choi, Joan Serrà, Mayank Kumar Singh, Wei-Hsiang Liao, and Yuki Mitsufuji ask a blunt but timely question: Can existing watermarking methods withstand real-world transformations?
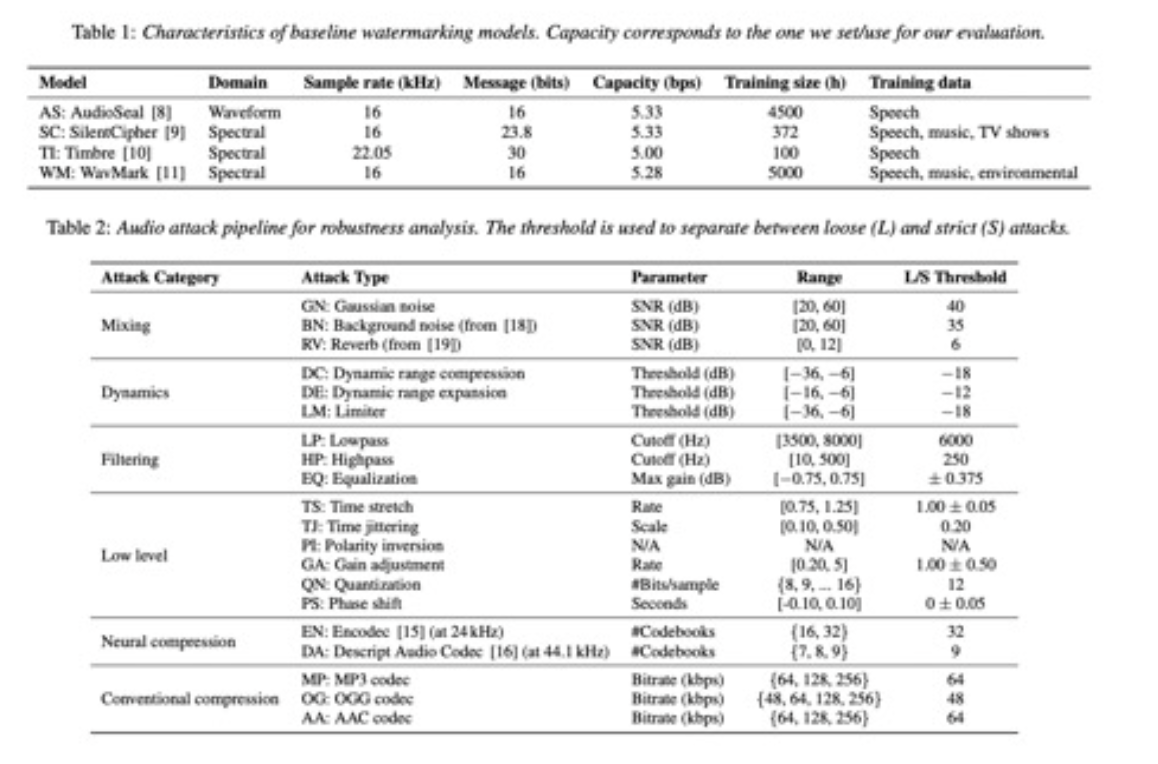
Their work introduces RAW-Bench, the Robust Audio Watermarking Benchmark, and as the authors describe, the benchmark “introduce[s] a comprehensive audio attack pipeline featuring various distortions such as compression, background noise, and reverberation.”
Through this framework, the researchers found that “neural compression techniques pose the most significant challenge, even when algorithms are trained with such compressions.” In plain terms: as audio compression becomes increasingly powered by neural networks (tools like Encodec and Descript Audio Codec) the very signals that watermarking systems rely on to prove authenticity are being erased.
The paper’s title asks, Will they survive? and the answer, for now, is: not yet. Across tests on speech, music, and environmental sounds, the researchers observed that “none of the considered watermarking algorithms survives the [Descript Audio Codec] attack” and that “watermarking algorithms and neural codecs compete for the same space… we believe that neural codecs will end up removing imperceptible watermarks.”
This insight reshapes how the field thinks about protecting audio in the era of AI compression. It suggests that future watermarking systems may need to collaborate with codecs rather than fight against them—embedding identity in ways that persist through transformation rather than being filtered out by it.
RAW-Bench gives researchers a way to measure that fragility and, eventually, strengthen it. It’s not just a testbed; it’s a stress test for the integrity of digital sound.
Toward a Fairer Sonic Future
Taken together, these three studies sketch a vision of AI that can enable more effective monitoring of AI music.
Unlearning helps us see where creativity comes from.
Contrastive learning helps us understand how works relate.
Watermarking benchmarks help us ensure that what’s authentic stays intact.
Each represents a layer in Sony AI’s broader mission to use research innovation to create the pathways to systems that support—not supplant—human artistry.
In the Creative AI Track NeurIPS paper, Choi and colleagues remind us that attribution is, “crucial in the context of AI-generated music, where proper recognition and credit for original artists are generally overlooked.” In the ICML work, Serrà’s team shows that perhaps machines can be taught a fine-grained listening that can help protect what humans create. And in the INTERSPEECH study, Özer and collaborators reveal that even the most robust watermark can be fragile when technology outpaces its design.
Sony AI’s researchers are helping define how balancing innovation with responsibility can work in the future of generative music: with AI that remembers its sources, hears its connections, and safeguards its signals.
In doing so, they remind us that creativity, even when amplified by machines, still begins—and must remain—with people.
Latest Blog

March 5, 2026 | Imaging & Sensing, Sony AI
On Writing The Principles of Diffusion Models, A Q&A With Sony AI Researcher, Je…
IntroductionDiffusion models have become a go-to approach for high-quality generation; however, the field can be challenging to navigate once the paper titles and acronyms begin to…

March 2, 2026 | Sony AI
Advancing AI: Highlights from February
February at Sony AI was defined by momentum across global stages, research publications, and conversations about how AI moves from theory into practice.This month spanned responsib…

February 2, 2026 | Sony AI
Advancing AI: Highlights from January
January set the tone for the year ahead at Sony AI, with work that spans foundational research, scientific discovery, and global engagement with the research community.This month’s…

