




Research That Scales, Adapts, and Creates: Spotlighting Sony AI at CVPR 2025
Events
Sony AI
June 12, 2025
At this year’s IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) in Nashville, TN Sony AI is proud to present 12 accepted papers spanning the main conference and workshops—research that reflects our core mission: building AI that is responsible, adaptable, and creator-focused. From multimodal generation and scalable diffusion models to safe synthetic detection and low-light vision systems, this work represents the depth of Sony AI’s contributions across creative tools, imaging pipelines, and privacy-preserving AI.
The research below is grouped by flagship teams—AI for Creators and two areas of our Imaging & Sensing flagship, AI Sensing Pipeline, Privacy-Preserving Machine Learning (PPML)—to reflect both the diversity of technical contributions and their relevance to our long-term vision.
Imaging + Sensing: PPML (Privacy-Preserving Machine Learning) Advancing scalable, privacy-centered AI
From compact foundation models to cost-efficient diffusion training and deepfake detection, Sony AI’s PPML research at CVPR 2025 reflects a strong emphasis on making AI both powerful and trustworthy.
Title: Argus: Compact, Scalable Foundation Model for Vision
Authors: Weiming Zhuang, Chen Chen, Zhizhong Li, Sina Sajadmanesh, Jingtao Li, Jiabo Huang, Vikash Sehwag, Vivek Sharma, Hirotaka Shinozaki, Felan Carlo Garcia, Yihao Zhan, Naohiro Adachi, Ryoji Eki, Michael Spranger, Peter Stone, Lingjuan Lyu
Research Overview: Smarter Vision Across Tasks
Current vision foundation models (VFMs) often demand massive datasets, heavy computation, and still struggle with consistency across tasks. Sony AI introduces Argus: a compact, highly versatile VFM that rethinks this challenge through efficient multitask training and scalable adaptation.
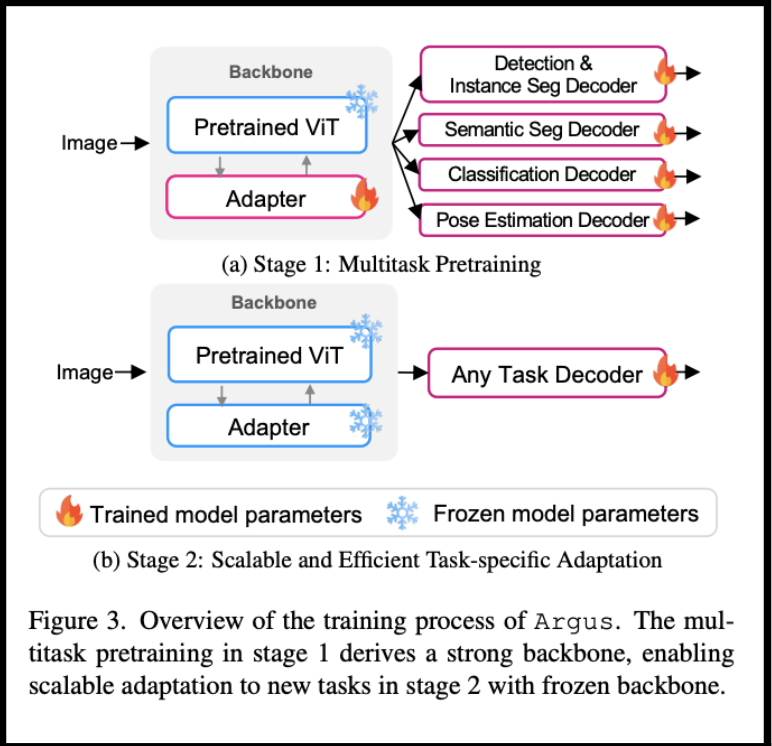
Argus uses a two-stage approach: first, multitask pretraining across diverse vision tasks, covering image-, region-, and pixel-level tasks, while leveraging strong pretrained ViT backbones; second, lightweight adaptation where only task-specific decoders are fine-tuned, not the backbone. As the researchers explain, “Argus is highly extensible, allowing efficient adaptation to new tasks by leveraging advanced, task-specific decoders.”
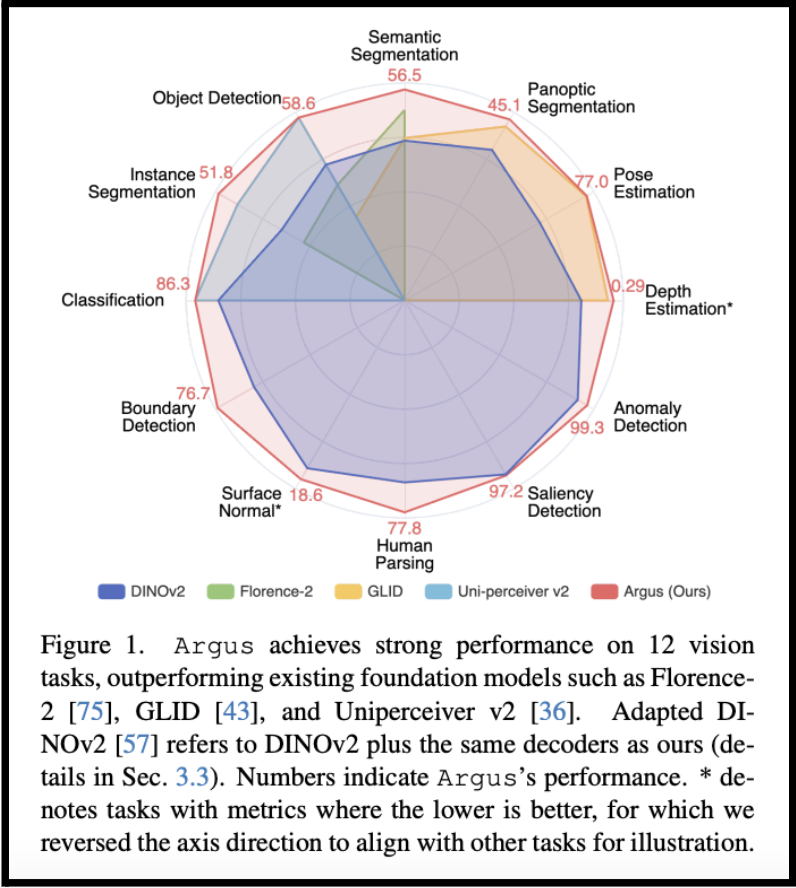
Despite being lightweight, just ~100M parameters with only 13.6% trained, Argus competes with and surpasses some much larger models on 12 major vision tasks. Critically, Argus “achieves compelling performance while making pretrained ViTs scalable and adaptable to various vision tasks efficiently.”
This architecture helps bridge a long-standing gap in the field: “We aim to offer a compact, training-efficient, scalable and well-performing VFM to better serve various real-world vision applications.”
Why It Matters: Real-World Versatility at Lower Cost
Argus fundamentally changes the cost-to-capability equation for visual AI. Instead of retraining enormous models for every new task, Argus shows that a lean backbone and modular decoder setup can support a broad range of use cases—from object detection and depth estimation to saliency detection and anomaly detection—with minimal retraining.

As the authors explain: “We envision that our VFM and proposed approaches can accelerate the practical, real-world adaptation of VFMs in resource-constrained applications.”
For developers, designers, and AI teams focused on practical deployment (not just benchmark wins), Argus offers a powerful foundation to build visual systems that are lighter, faster, and more flexible.
Key Challenges: Rethinking Vision Model Scalability
- Overcoming Model Bloat: Most VFMs require billions of parameters; Argus needed to be compact but still high-performing across 12 diverse vision tasks.
- Handling Task Interference: Training for multiple tasks simultaneously can cause conflicts; Argus solved this with smart adapter modules and training recipes that preserve generalization.
- Future-Proofing Models: By freezing the backbone and fine-tuning only decoders, Argus ensures new advances in task-specific techniques can be easily incorporated without overhauling the core model.
Title: Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget
Authors: Vikash Sehwag, Xianghao Kong, Jingtao Li, Michael Spranger, Lingjuan Lyu
Research Overview: Democratizing Diffusion with Smarter Training
Training large-scale diffusion models has traditionally required massive computational resources, proprietary datasets, or both, and this unfortunately creates a barrier for researchers and developers without deep pockets. In Stretching Each Dollar, Sony AI researchers introduce MicroDiT, a text-to-image diffusion transformer that challenges this norm by showing how a high-performing model can be trained from scratch using only $1,890 in compute and 37-million real and synthetic images.
The key innovation? Deferred patch masking—a strategy that preprocesses all image patches using a lightweight “patch-mixer” before masking up to 75% of them during training. This allows the model to retain important semantic context while significantly cutting computational costs. This method outperforms both naïve masking and model downscaling when training budget is fixed, delivering strong performance at a fraction of the cost.
The result: a 1.16B parameter sparse transformer model trained in just 2.6 days on a single 8×H100 node, achieving a competitive 12.7 FID on the COCO dataset—14× cheaper than the current state-of-the-art low-cost alternative.
Why It Matters: Making Large-Scale AI More Accessible
This work opens the door to diffusion model research for smaller labs and teams. By avoiding proprietary datasets and using open-source tools, MicroDiT proves that top-tier diffusion models can be built on limited budgets without compromising quality.
"We hope that our low-cost training mechanism will empower more researchers to participate in the training and development of visual generative AI models,” the authors write.
For organizations seeking scalable visual generation solutions without high infrastructure investments, MicroDiT represents a new method for efficient generative modeling.
Key Challenges: Cutting Cost… Without Cutting Corners
- -Applying a high masking ratio usually degrades results. The Deferred patch masking strategy keeps unmasked patches semantically rich, mitigating this problem.
- -Leveraging additional unmasked finetuning and other training tricks, such as MoE, helped achieve competitive performance with fewer training hours.
- -Combining synthetic data with real data significantly boosts human preference evaluation, while keeping the data volume modest.
Title: CO-SPY: Combining Semantic and Pixel Features to Detect Synthetic Images by AI
Authors: Siyuan Cheng, Lingjuan Lyu, Zhenting Wang, Xiangyu Zhang, Vikash Sehwag
Research Overview: A Dual-Pronged Defense Against Synthetic Image Misuse
As generative AI models rapidly improve, so do the challenges of detecting AI-generated images, especially across diverse models, and unseen content. Sony AI’s CO-SPY framework proposes a new approach: enhance both semantic and artifact-based detectors individually, then fuse them through a dynamic, adaptive strategy. The result? A detector that generalizes better than anything before it.
CO-SPY first strengthens semantic detection by using OpenCLIP, a model trained on millions of images, and introduces feature interpolation to make the semantic detector less prone to overfitting. Then it upgrades artifact detection with a VAE-based extraction method, isolating generative artifacts even after transformations like JPEG compression. These two enhanced feature streams are then intelligently merged using adaptive fusion, which weights the importance of each type based on the input.
Across 22 generative models and multiple test conditions—including a wild-sourced dataset of 50,000 real-world fakes—CO-SPY consistently outperforms existing state-of-the-art methods. Notably, it achieves 14% higher accuracy than the previous best detectors on in-the-wild images, and over 11% higher average accuracy across standard benchmarks. As the authors aptly conclude, “These results underscore the need for improved detection reliability in real-world scenarios.”
Key Challenges and Solutions:
Challenge: Artifact detectors break down under lossy compression (such as JPEGs).
Solution: CO-SPY uses a VAE-based artifact extractor that captures deeper generative signals—ones that persist even after common transformations like compression or resizing.
Challenge: Semantic detectors overfit to training data and struggle with unseen content.
Solution: The framework introduces feature-space interpolation and leverages OpenCLIP to generalize to unfamiliar generative styles and objects.
Challenge: Combining two weak detectors doesn’t automatically make a strong one.
Solution: CO-SPY's adaptive fusion architecture balances the weight of semantic and artifact signals based on the characteristics of each image, leading to true synergy—not just an average.
Challenge: Real-world data includes noise, blur, resizing, and other distortions.
Solution: CO-SPY is trained and evaluated on the CO-SPYBENCH benchmark which was built to simulate real-world diversity across 22 models and five online platforms.
Title: Six-CD: Benchmarking Concept Removals for Text-to-Image Diffusion Models
Authors: Jie Ren, Kangrui Chen, Yingqian Cui, Shenglai Zeng, Hui Liu, Yue Xing, Jiliang Tang, Lingjuan Lyu
Research Overview: Building Safer Generative Models
As text-to-image diffusion models become more powerful, they also raise new concerns: How do we prevent misuse—such as generating violent, pornographic, or unauthorized celebrity images—without damaging the model’s ability to generate meaningful, benign content?
To answer this, researchers from Sony AI and Michigan State University introduce Six-CD, a comprehensive benchmark for evaluating and improving concept removal methods—techniques designed to prevent harmful or inappropriate content from being generated by AI.
Unlike past evaluations, which often relied on limited categories or inconsistent prompts, Six-CD introduces:
- Six categories of unwanted content: harm, nudity, celebrity identity, copyrighted characters, objects, and art styles.
- High-effectiveness prompts, which better test whether models can reliably suppress problematic concepts.
- A new metric, called in-prompt CLIP score, to evaluate whether the model still preserves the benign parts of a prompt after removing the unwanted ones. “An expected concept removal method should have the ability to generate the benign part of the prompt when the unwanted concepts are removed,” the researchers explain.
Why It Matters: Safer AI Without Sacrificing Creativity
Concept removal is essential for privacy preserving deployment of generative AI. But removing harmful ideas shouldn’t also erase the creativity and utility of benign content.
Take the example: “Mickey Mouse is eating a burger.” If a model removes “Mickey Mouse” (a copyrighted concept), it should still show someone eating a burger. Most current methods can’t guarantee this, but Six-CD introduces the tools and metrics to measure and improve it.
This work establishes best practices and real-world benchmarks for improving diffusion model safety, all without compromising generation quality. It also reveals which methods perform best when removing one concept versus many, and why inference-time methods often fail when handling dozens of unwanted concepts at once.
Key Challenges: Balancing Safety with Retainability
- Over-removal: Many existing methods accidentally erase benign content along with unwanted concepts
- Prompt effectiveness: General concepts like “violence” are hard to detect and harder to filter reliably
- Scalability: Some methods break down when asked to remove 50+ concepts at once
- Retainability: The new in-prompt CLIP score shows that models often struggle to preserve relevant details when editing partially harmful prompts
Solving real-world bottlenecks in edge vision and scalable image modeling.
AI Sensing Pipeline
The Imaging & Sensing team at Sony AI tackles practical pain points across image synthesis and enhancement, especially when speed and efficiency are critical. These papers highlight faster denoising pipelines and RGB-to-RAW reconstruction methods that help models perform better in low-light or mobile edge environments. They're part of a broader effort to improve AI sensing pipelines and make high-performance imaging more deployable.
Main Conference Paper: Noise Modeling in One Hour: Minimizing Preparation Efforts for Self-supervised Low-Light RAW Image Denoising
Authors: Feiran Li, Haiyang Jiang, Daisuke Iso
Research Overview: Simplifying Low-Light Image Denoising
High-quality RAW image denoising in low-light settings relies on realistic synthetic noise to train models, but existing noise synthesis methods require extensive calibration, often taking days to prepare. This research from Sony AI introduces a new method that cuts that time to just one hour, without sacrificing accuracy.
The team proposes a streamlined synthesis pipeline based on detailed noise analysis and validation of widely used techniques. By eliminating system gain calibration and signal-dependent profiling steps, the approach removes barriers to scaling these models in practical workflows.
In quantitative terms, this faster pipeline still performs competitively, showing, “...up to 0.54dB PSNR improvement over the current state-of-the-art noise synthesis technique.” This makes it ideal for both rapid prototyping and large-scale deployment in imaging systems and camera pipelines.
Why It Matters: Denoising at the Speed of Real-World Development
Many AI image enhancement techniques work great in the lab, but stall out in the real world due to costly setup and calibration. As the team notes, “Noise synthesis is a promising solution for addressing the data shortage problem in data-driven low-light RAW image denoising.” This work tackles this known bottleneck head-on by offering a way to dramatically speed up the preparation process.
Rather than requiring specialized hardware calibration or hours of expert tuning, this pipeline makes high-performance denoising accessible. That’s critical for edge device deployment, mobile imaging, and self-supervised learning setups where ground truth data is scarce.
Key Challenges: Efficiency Without Compromise
- Cutting Preparation Time: Reduced noise modeling from days to under an hour while maintaining high quality.
- Justifying Simplification: Built on careful analysis to ensure that removing profiling steps didn’t degrade performance.
- Real-World Denoising Gains: Demonstrated measurable improvements over SOTA techniques despite the streamlined setup.
Title: ReRAW: RGB-to-RAW Image Reconstruction via Stratified Sampling for Efficient Object Detection on the Edge
Authors: Radu Berdan, Beril Besbinar, Christoph Reinders, Junji Otsuka, Daisuke Iso
Research Overview: Boosting Edge AI with Improved RAW Synthesis
Most computer vision systems on edge devices, like smartphones, drones, or autonomous vehicles, use standard RGB images as input. But those images have already been heavily processed, meaning much of the original scene detail has been lost. The RAW data captured directly from camera sensors is far richer and more accurate, especially in low-light environments.
So what’s the catch? Training AI models on RAW data usually requires huge labeled datasets, which are hard to come by, making it difficult to take advantage of that extra detail in practice.
ReRAW solves this by converting widely available labeled RGB datasets into realistic, sensor-specific RAW images using a reverse ISP model. Unlike past approaches, ReRAW handles both day and night scenes, captures high-intensity details better, and outputs state-of-the-art conversion quality.
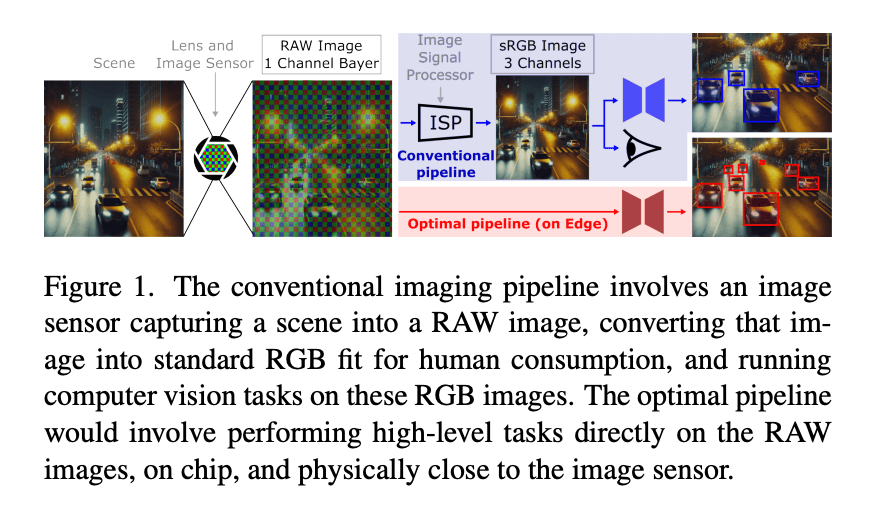
Its unique multi-head architecture predicts multiple gamma-corrected RAW images and combines them via a learned scaling encoder. A novel stratified sampling technique ensures the model doesn’t neglect bright pixels—a common flaw in RAW conversion models trained with skewed data. As the authors state, “Our proposed stratified sampling technique helps in boosting the conversion performance of ReRAW” and better reconstructs “highlighted regions of the RAW images.”
Why It Matters: Edge AI Without the Compromise
ReRAW offers a new pipeline for training compact object detection models directly on RAW: no need for ISPs, domain adapters, or retraining on RGB. This is a major win for energy-efficient, high-performance computer vision in constrained environments like mobile devices or embedded systems.

As the authors explain, “Motivated by the lack of large-scale labeled RAW datasets, and analysing the shortcomings of previous reverse ISPs, we design ReRAW as a universal RGB-to-RAW converter that can handle both daytime and nighttime images, with mild or strongly skewed RAW pixel distributions.”
When models were pretrained on ReRAW-generated synthetic RAW data and fine-tuned on small real-world RAW datasets, they consistently outperformed traditional RGB pipelines, even in low-light conditions. This research effectively shows that training on ReRAW is better than adapting RGB models—provided the synthetic RAW quality is high.
Key Challenges: From Color Profiles to Control
- Capturing Sensor-Specific Color: ReRAW predicts multiple gamma-transformed versions and dynamically learns which to use based on the image.
- Fixing the Brightness Bias: By using stratified sampling, the model balances learning across all luminance levels, not just the dark pixels that dominate RAW data.
- Scaling to Real Tasks: ReRAW-trained detectors (like YOLOX and SSD) beat RGB baselines across day and night datasets, without relying on hand-tuned adapters or expensive retraining.
AI for Creators
Exploring new frontiers in audio, motion, and narrative generation.
AI-powered creative tools are moving beyond single-modality generation. Whether crafting motion sequences from text, synthesizing soundtracks from video, or building coherent image-based narratives, these papers demonstrate Sony AI’s continued investment in enabling expressive, high-quality content generation. The common thread: tools that give creators more control, fidelity, and performance without sacrificing speed or scalability.
Title MMAudio: A Multimodal Approach to Video-to-Audio Generation
Authors: Ho Kei Cheng (Sony AI intern), Masato Ishii, Akio Hayakawa, Takashi Shibuya, Alexander Schwing, Yuki Mitsufuji
Research Overview: Turning Video into Sound — With Precision
Imagine watching a silent video of ocean waves, and an AI instantly generates the sound of water crashing timed perfectly to each motion. That’s the promise of MMAudio, a new model from Sony AI that sets a new benchmark for video-to-audio synthesis by combining visual and textual information to generate high-quality, context-aware sound.
Rather than relying solely on video-audio pairs or fine-tuned text-to-audio models, MMAudio uses joint training across text, audio, and video data, a first-of-its-kind framework that improves semantic alignment, temporal precision, and audio quality in one shot. As the researchers explain: “Jointly training on large multimodal datasets enables a unified semantic space and exposes the model to more data for learning the distribution of natural audio.”
The model also introduces a frame-level synchronization module to solve a key challenge: aligning audio and video precisely enough to avoid perceptual mismatch. This allows MMAudio to perform well even with minimal parameters and low inference time.
Why It Matters: A Foundation for Multimodal AI Creativity
MMAudio tackles a long-standing limitation in AI: how to accurately generate sound from visual content. Traditional methods were either limited by data availability or compromised by overly complex architectures. MMAudio’s approach solves both issues by training a single model across multiple data types, achieving better synchronization, better quality, and better real-world usability.
“We believe a multimodal formulation is key for the synthesis of data in any modality, and MMAudio lays the foundation in the audio-video-text space,” researchers note.
This work opens the door for more immersive and accessible multimedia generation tools, spanning film, gaming, AR/VR, and accessibility tech.
Read More
MMAudio is the subject of a full-length Sony AI blog post, with details on the model architecture, benchmark performance, and sample demos. Read on: Unlocking the Future of Video-to-Audio Synthesis: Inside the MMAudio Model
Research Paper: Classifier-Free Guidance inside the Attraction Basin May Cause Memorization
Authors: Anubhav Jain (Sony AI intern), Yuya Kobayashi, Takashi Shibuya, Yuhta Takida, Yuki Mitsufuji
Research Overview: A New Look at Memorization
Diffusion models sometimes memorize and reproduce training images exactly— raising copyright and privacy concerns. Our researchers propose a new explanation: memorization happens when the model’s generation path falls into an invisible “attraction basin” during denoising, much like a whirlpool pulling it back toward known data.
The solution? Delay applying classifier-free guidance (CFG) until the model escapes this basin. Waiting until an ideal "transition point" allows the model to generate fresh, non-memorized images without retraining or heavy computation. The team also introduces Opposite Guidance to actively steer the model away from memorization early on. The research shows the method to be simple, effective, and it works across many types of diffusion models.
Key Challenges & Solutions:
- Making the Invisible Visible: Revealed the hidden structure (attraction basins) behind memorization.
- Efficient by Design: Developed a low-cost solution that works during inference, avoiding costly retraining.
- Broad Applicability: Created a method that succeeds across various models, prompts, and datasets not just niche cases.
Why It Matters: A Practical, Scalable Solution
Unlike earlier methods that tweak prompts or require model retraining, this approach works at inference time, with no changes to the underlying model. It generalizes across different causes of memorization from duplicated training data to “trigger tokens,” making it a versatile tool for protecting originality and privacy in AI-generated content.
Research Paper: VinaBench: Raising the Bar for Faithful and Consistent Visual Narrative Generation
Authors: Silin Gao, Sheryl Mathew, Li Mi, Sepideh Mamooler, Mengjie Zhao, Hiromi Wakaki, Yuki Mitsufuji**, Syrielle Montariol, Antoine Bosselut
(**This is not the work of Sony AI, but Yuki Mitsufuji, Lead Research Scientist at Sony AI was a contributor**)
Research Overview: Building Smarter Visual Storytelling
Yuki Mitsufuji, Sony AI Lead Research Scientist, contributed to this research.This cross-functional team introduced VinaBench. Visual storytelling models often stumble when turning text into image sequences. Characters change appearances, settings shift inconsistently, and key plot points get lost. Vinabench is a new benchmark designed to fix these issues by adding commonsense and discourse constraints to visual narratives.
VinaBench provides over 25,000 visual-text pairs, richly annotated to bridge the “manifestation gap.” This is the gap between what's implied in text and how it should appear visually. As the paper explains, VinaBench “promotes the learning of consistent and faithful visual narrative generation and its evaluation,” helping models better understand not just what to depict but how scenes should evolve over time.
By annotating “the underlying commonsense and discourse constraints in visual narrative samples,” VinaBench enables models to maintain character profiles, consistent environments, and logical event progression—key ingredients that human artists intuitively use in storyboarding. The researchers emphasize: "Learning with VinaBench’s knowledge constraints effectively improves the faithfulness and cohesion of generated visual narratives.”
Testing across three major generative models confirmed that models trained with VinaBench showed stronger narrative consistency and fewer hallucinations, though there is still “...considerable room for improvement to reach the level of human visual storytelling.”
8.
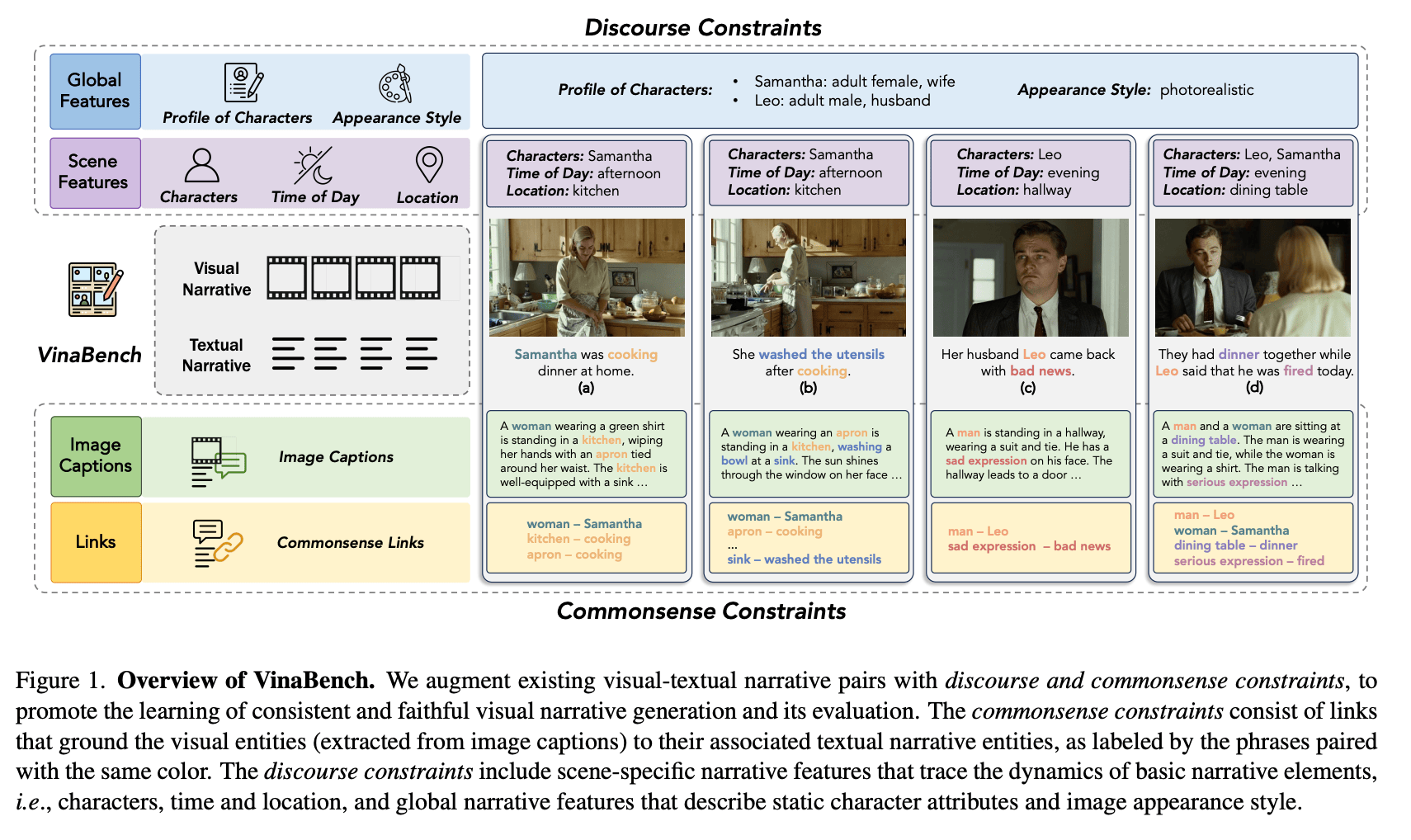
Why It Matters: A Blueprint for Better AI Storytelling
VinaBench moves beyond basic text-to-image matching by embedding structured narrative logic, commonsense reasoning and scene continuity, directly into how models learn. It recognizes that visual storytelling is not about isolated frames. Instead it’s about connected, evolving scenes that mirror human understanding.
As the authors put it: “Creating visual narratives is a considerably open-ended task,”
meaning there are many valid ways to visually depict a story and models must learn to generate faithful, consistent interpretations rather than rigid copies.
VinaBench offers a practical path for building AI systems that tell visually coherent, emotionally believable stories, unlocking new possibilities in fields like film previsualization, or educational media.
Key Challenges: Closing the Manifestation Gap
- Capturing the Invisible: Visualizing implied ideas like emotions or unseen events (such as, "bad news" shown through a sad expression) required augmenting models with commonsense links between images and narratives.
- Evaluating Fairly: Traditional benchmarks penalized creative but valid outputs. VinaBench introduced new ranking-based metrics because “full-reference metrics for visual narrative generation may be inadequate.”
- Generalizing Across Styles: VinaBench was carefully designed to span photorealistic, cartoon, fantasy, and other visual styles, reinforcing that “implicit commonsense and discourse constraints” are universally needed, regardless of artistic medium.
Workshop Title: MoLA: Motion Generation and Editing with Latent Diffusion Enhanced by Adversarial Training
Authors: Kengo Uchida, Takashi Shibuya, Yuhta Takida, Naoki Murata, Julian Tanke, Shusuke Takahashi, Yuki Mitsufuji
Research Overview: Text-to-Motion, Reimagined
Animating lifelike human motion from text is no longer just a research curiosity — it’s essential for game developers, animators, and immersive media creators. But most AI models force tradeoffs: you either get quality, speed, or control — not all three.
MoLA changes that. Short for Motion Generation and Editing with Latent Diffusion Enhanced by Adversarial Training, MoLA generates high-quality, variable-length human motion sequences from text prompts—and it does so quickly, accurately, and with powerful training-free editing tools.
The model combines three major components:
- A motion-specific variational autoencoder (VAE) for learning compact motion representations,
- A latent diffusion model for generating motions from text,
- And adversarial training to improve realism and flexibility.
MoLA also introduces an activation variable to automatically determine motion length, allowing outputs to match the rhythm and timing implied by the text without user intervention. As the authors state: “Our model achieves variable-length motion generation aligned with textual descriptions and high generation performance on a commonly used dataset.”
What sets it apart? You can use MoLA to edit motions, such as, adjusting trajectory paths, in-betweening frames, or modifying upper/lower body movements without retraining the model. That makes it ideal for real-world, fast-paced creative workflows.
Why It Matters: A New Foundation for Motion AI
Existing models make animators choose: do you want high quality or fast edits? MoLA offers both. It’s the first to significantly extend the performance boundaries of training-free motion editors across speed, realism, and control — all in one system.
As the team explains, “With MoLA, we can deal with various types of motion editing tasks in a single framework.” This is a major step for developers and storytellers who want intuitive tools that support creativity, not bottleneck it. With strong performance across diverse datasets and tasks, MoLA paves the way for more accessible, flexible motion generation systems—even in environments where compute is limited or deadlines are tight.
Key Challenges: Pushing Past Tradeoffs
- Making Motion Length Natural: Instead of requiring users to specify exact durations, MoLA learns to infer motion length from context, using an activation variable to handle timing fluidly.
- Editing Without Retraining: Most models can’t be edited post-training. MoLA’s guided diffusion process allows control signals to shape the motion directly — e.g., path-following, start-end in-betweening, or joint-specific editing — without retraining.
- Balancing Speed and Quality: By generating in latent space and using adversarial learning, MoLA avoids the slow inference speeds of data-space diffusion, while still outperforming comparable models in quality.
Conclusion
From generative motion and audio tools to robust vision systems and privacy-focused model design, Sony AI’s research at CVPR 2025 reflects our mission to unleash human imagination and creativity as we work to examine the many ways that AI can bring value to creators of all kinds. We look forward to the conversations this work sparks at CVPR and beyond—and invite collaborators and researchers to connect with us as we continue shaping the future of AI across entertainment, robotics, imaging, and beyond.
Further Reading
Rediscover our prior contributions to CVPR over the years:
Latest Blog

February 2, 2026 | Sony AI
Advancing AI: Highlights from January
January set the tone for the year ahead at Sony AI, with work that spans foundational research, scientific discovery, and global engagement with the research community.This month’s…

January 30, 2026 | Sony AI
Sony AI’s Contributions at AAAI 2026
Sony AI’s Contributions at AAAI 2026AAAI 2026 is a reminder that progress in AI isn’t one straight line. This year’s Sony AI contributions span improving and enhancing continual le…

January 26, 2026 | Sony AI
How Sony AI’s Scientific Discovery Team is Reimagining How Researchers Evaluate …
In today’s research landscape, thousands of scientific papers are published each day; a metaphorical sea of knowledge. Even domain experts struggle to keep up. As Pablo Sánchez Mar…

