




Sony AI’s Contributions at AAAI 2026
Sony AI
January 30, 2026
Sony AI’s Contributions at AAAI 2026
AAAI 2026 is a reminder that progress in AI isn’t one straight line. This year’s Sony AI contributions span improving and enhancing continual learning and interpretability, robust decision-making in dynamic environments, and creator-facing tools for editing audio and video with intent intact. The common thread is practical trust: not just better outputs, but clearer reasoning, steadier behavior, and more predictable control.
AAAI 2026: RESEARCH ROUNDUP
AAAI Invited Talk:
From How to Learn to What to Learn in Multiagent Systems and Robotics with Sony AI Chief Scientist, Peter Stone
There has been a lot of exciting recent progress on new and powerful machine learning algorithms and architectures: how to learn. But for autonomous agents acting in the dynamic, uncertain world, it is at least as important to be able to identify which concepts and subproblems to focus on: what to learn. This talk presented methods for identifying what to learn within the framework of reinforcement learning, focusing especially on applications in multiagent systems and robotics.
To watch the full talk, visit: AAAI Invited Talk, “From How to Learn to What to Learn in Multiagent Systems and Robotics.”
RESEARCH HIGHLIGHTS
Research Paper
Out-of-Distribution Generalization with a SPARC: Racing 100 Unseen Vehicles with a Single Policy
Researchers
Bram Grooten; Patrick MacAlpine; Kaushik Subramanian; Peter Stone; Peter R. Wurman (TU Eindhoven; Sony AI; University of Texas at Austin)
Introduction to SPARC
This research examines a core challenge in autonomous systems: how to perform well when conditions change. The researchers introduce SPARC, a learning framework that enables an autonomous racing agent to compete across more than 100 previously unseen vehicles using a single policy.
Rather than tailoring behavior to one specific car, SPARC learns driving strategies that transfer across vehicles with different physical properties. As the researchers note, a single learned policy can achieve competitive racing performance without vehicle-specific tuning.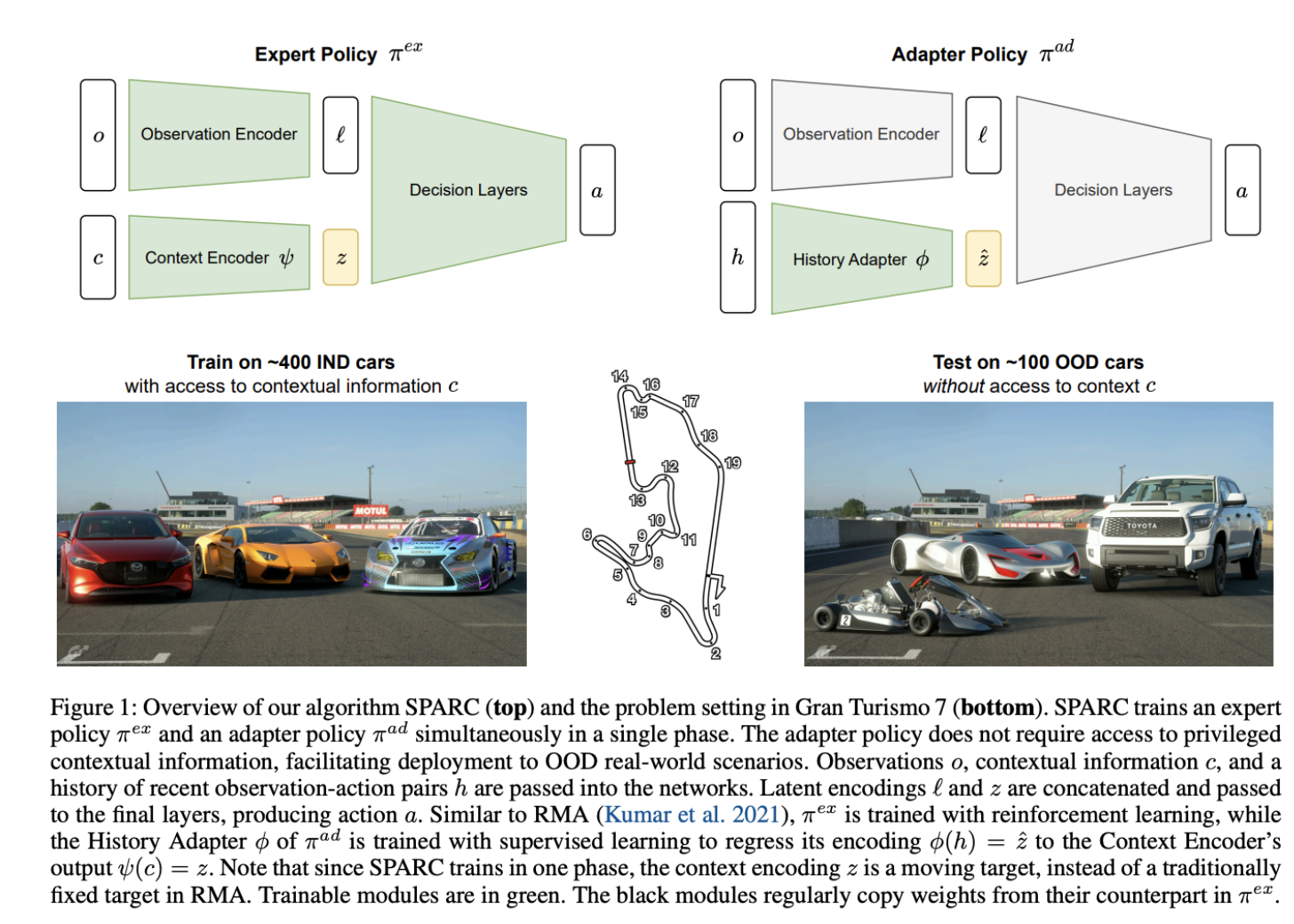
Instead, the policy remains fixed, even as acceleration, grip, mass, and steering dynamics vary. The agent learns how to race, not how to race one particular vehicle.
Why SPARC Matters
Many autonomous driving and racing systems perform well only within narrow bounds. When vehicle dynamics differ from training conditions, performance often drops sharply. This brittleness limits real-world usefulness, where variation is unavoidable.
SPARC addresses this by decoupling policy learning from vehicle identity. Rather than encoding behaviors tied to a specific vehicle, “the policy learns a representation that captures shared racing-relevant structure across a wide range of vehicle dynamics.”
This allows a single policy to adapt across vehicles without retraining. Like an experienced human driver switching cars, the system adjusts to differences in handling without relearning the fundamentals. The result is a more scalable and robust approach to generalization.
Key Challenges Addressed
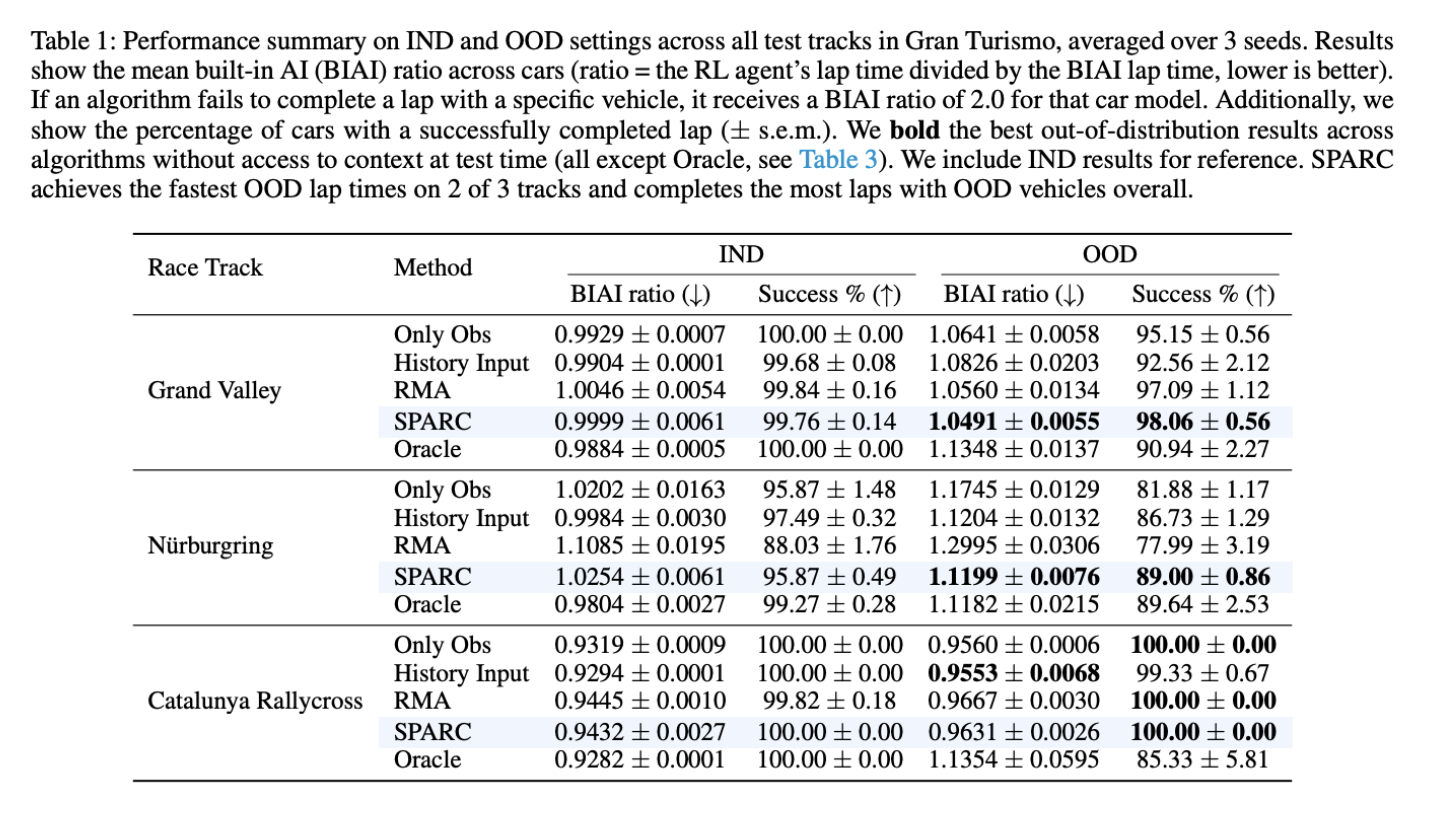
- Vehicles differ widely in how they accelerate, brake, and turn. SPARC is evaluated on vehicles whose dynamics fall outside the training distribution, testing true generalization rather than small variations on familiar cases.
- Maintaining separate policies does not scale. SPARC demonstrates that one policy can handle wide variation without growing in size or complexity.
- Even small modeling differences can destabilize learned controllers. Racing 100 unseen vehicles provides a stress test for stability and adaptability.
Conclusion
The results show that SPARC’s single policy achieves competitive racing performance across a large and diverse set of unseen vehicles. Compared to baselines that rely on vehicle-specific policies, SPARC maintains stronger consistency and avoids sharp drops in performance as dynamics change.
Crucially, performance does not collapse when conditions move beyond the training regime. As the evaluation shows, “performance remains stable even when evaluated on vehicle dynamics that fall well outside the training distribution, indicating that the learned policy does not rely on narrow assumptions about the environment.”
This indicates that the learned behavior captures transferable driving structure rather than brittle, model-specific patterns.
The researchers conclude that strong out-of-distribution performance does not require a growing collection of specialized models. It can emerge from learning the right abstractions. SPARC shows that a single policy can scale across diverse vehicles while remaining stable. In addition to autonomous driving, SPARC is a general algorithm capable of learning robust adaptive control policies for a variety of different dynamic environments and tasks. This is a meaningful step toward autonomous systems that operate reliably beyond their training envelope.
Research Title
SteerMusic: Enhanced Musical Consistency for Zero-shot Text-guided and Personalized Music Editing
Researchers
Xinlei Niu; Kin Wai Cheuk; Jing Zhang; Naoki Murata; Chieh-Hsin Lai; Michele Mancusi; Woosung Choi; Giorgio Fabbro; Wei-Hsiang Liao; Charles Patrick Martin; Yuki Mitsufuji
(Australian National University; Sony AI; Sony Europe B.V.)
Introduction to SteerMusic and SteerMusic+
Music editing is often like changing one ingredient without ruining the whole recipe. This research introduces two methods—SteerMusic and SteerMusic+—that aim to edit music while keeping the original musical content intact.
The starting point is a practical gap in today’s diffusion-based zero-shot text-guided editing. Many approaches can make changes, but they often damage the underlying music. As the researchers put it, “these methods often struggle to preserve the musical content.”

SteerMusic targets text-guided edits (like,“change the instrument” or “change the mood”) using a score-distillation-based approach. While SteerMusic+ extends this to personalized editing, where text alone can’t capture the exact target style.
Why SteerMusic Matters and What Problems it Solves
The research frames music editing as a two-part objective. In the researchers’ wording, the goals of music editing are, “preserving original musical content and ensuring alignment between the edited music and the desired target.”
The problem is that text instructions can be too blunt for music. They don’t always specify the precise style a creator has in mind. The research states this directly: “text instructions alone usually fail to accurately describe the desired music.” To solve this, SteerMusic+ enables edits into user-defined styles that text prompts can’t reliably express.
Key Challenges
- Content preservation during editing: Even strong diffusion-based editing methods can distort melody or structure. The research shows an example of reconstructed melody distortion after limited inversion steps (see Figure 1 below).
- Text can describe “jazzier” or “more upbeat,” but not a very specific, user-defined musical identity. SteerMusic+ addresses this by representing a user-defined style through a manipulable concept token.
- Measuring success in a meaningful way: The research uses both objective metrics (for consistency and fidelity) and subjective human studies (MOS and user preference) to validate whether edits sound right and stay faithful to the source.
Results and Conclusions
In experiments, the research reports that SteerMusic improves source consistency (i.e., better preservation of melody/structure) while maintaining edit fidelity across multiple tasks, such as instrument, genre, mood, background, on ZoME-Bench, and it also evaluates longer-form clips on MusicDelta.
A key result is that SteerMusic is positioned as a practical middle path between “faithful but weak edits” and “strong edits that break the music.” The research summarizes that balance explicitly: “SteerMusic effectively balances source consistency and edit fidelity, fulfilling the core objective of music editing.”
SteerMusic+ is framed as the step that makes personalization viable when text falls short. This research brings score distillation more fully into music editing, across both coarse-grained (SteerMusic) and fine-grained personalized editing (SteerMusic+).
Research Title
Vid-CamEdit: Video Camera Trajectory Editing with Generative Rendering from Estimated Geometry
Researchers
Junyoung Seo*; Jisang Han*; Jaewoo Jung*; Siyoon Jin; JoungBin Lee; Takuya Narihira; Kazumi Fukuda; Takashi Shibuya; Donghoon Ahn; Shoukang Hu; Seungryong Kim†; Yuki Mitsufuji† KAIST AI; Sony AI; Sony Group Corporation
Introduction to Vid-CamEdit
Vid-CamEdit starts from a simple frustration: camera motion is often locked in the moment you hit record. Yes, you can trim, stabilize, or crop a video later, but you usually cannot re-shoot the camera path after the fact.

This research introduces Vid-CamEdit, a method for editing a video’s camera trajectory post-capture. The goal is to generate a new version of the same scene as if the camera had moved differently, using only a single input video.
Why Vid-CamEdit Matters
Changing camera motion after capture is hard because a new viewpoint reveals content the original video never saw. That creates missing regions, occlusions, and geometry that is only partially observable. Traditional reconstruction-heavy approaches can struggle when the requested camera move is large. Purely generative approaches can produce plausible frames, but they may drift from the scene’s underlying structure, especially over time.
Vid-CamEdit’s approach is to use geometry as a scaffold and generation as the paintbrush. Geometry provides a consistent spatial backbone. Generative rendering handles the parts the scaffold can’t fully specify, such as newly exposed surfaces.
Key Challenges
- -Large viewpoint changes: Big camera moves increase occlusions and unseen regions. That’s where methods tend to break.
- -Temporal consistency: Even strong per-frame rendering can flicker or wobble across time. The edited video still needs to feel like a continuous shot.
- -Data practicality: Dynamic, multi-view supervision at scale is limited. The method aims to reduce dependence on large amounts of real 4D multi-view video.
- -Balancing structure and realism: Rely too much on geometry and outputs can look rigid or incomplete. Rely too much on generation and the scene can lose spatial coherence.
Results
Vid-CamEdit frames camera trajectory editing as a two-stage pipeline. First, it estimates temporally consistent geometry from a monocular video. Then it uses generative rendering guided by that geometry to synthesize the video along a user-defined camera path. The intent is practical: keep the scene grounded, while still allowing edits that require extrapolating beyond what the camera originally saw.
The research also emphasizes a more data-efficient training setup than approaches that depend heavily on real multi-view 4D video. In evaluation, the method is reported to perform best where the problem is hardest: extreme trajectory edits on real-world footage.
The bigger takeaway is what this unlocks for creators and downstream applications.

If camera motion becomes editable after capture, video can be treated more like a flexible scene than a fixed recording. As the researchers put it:
“This ability will not only revolutionize how we experience our own videos but also impact fields like video editing, 4D content creation, virtual reality, and robotics.”
In that light, Vid-CamEdit is a step toward post-capture camera control that remains believable over time: not just a new viewpoint, but a coherent new shot.
Researchers
Kumud Tripathi*; Aditya Srinivas Menon*; Aman Gaurav; Raj Prakash Gohil; Pankaj Wasnik, Sony Research India
Introduction to “Listen Like a Teacher”
An ASR (automatic speech recognition) system converts spoken audio into written text. In the real world, ASR powers things like live captions, meeting transcripts, call-center analytics, voice typing, and accessibility features. When it works, it feels invisible. When it fails, it can quietly change meaning.
This research focuses on Whisper, an open-source ASR model that performs well across languages, but can produce hallucinations, i.e. text that sounds plausible but is not what was said, especially in noisy conditions. The researchers describe this failure mode as “hallucinations: fluent yet semantically incorrect transcriptions.”.
Why it Matters and What Problem it Solves
A big reason hallucinations are risky is that they can look confident. The research notes they can “seriously undermine trust” and may “escape detection” by word error rate alone. That matters for any workflow where transcripts are treated as records, such as customer support logs, compliance notes, or medical dictation drafts.
Most prior fixes focus on audio pre-processing or transcript post-processing. This work goes after the model itself. The researchers propose “a two-stage architecture” that first strengthens the encoder under noise and then further suppresses hallucinations during decoding.
Key Challenges
Hallucinations start before the final text appears
The research points to misalignment in internal representations under noisy input. So filtering the output alone can miss the root cause.
Important signal lives in the middle of the model
Whisper’s encoder layers capture different levels of information. Relying only on the final layer can discard useful intermediate features.
Noise can push the model toward the wrong attention habits
Even with better encoding, a decoder can still misinterpret noisy segments. The second stage addresses this by aligning the student model’s representations and attention maps to a clean-audio teacher.
Results and Conclusion
The two-stage design is meant to tackle hallucinations from both ends: improve what the model hears, then improve how it decides what to write. In practice, the first stage strengthens Whisper’s encoder so it can hold onto meaning under noise, and the second stage trains the model to stay aligned with a more reliable “teacher” when conditions are messy.
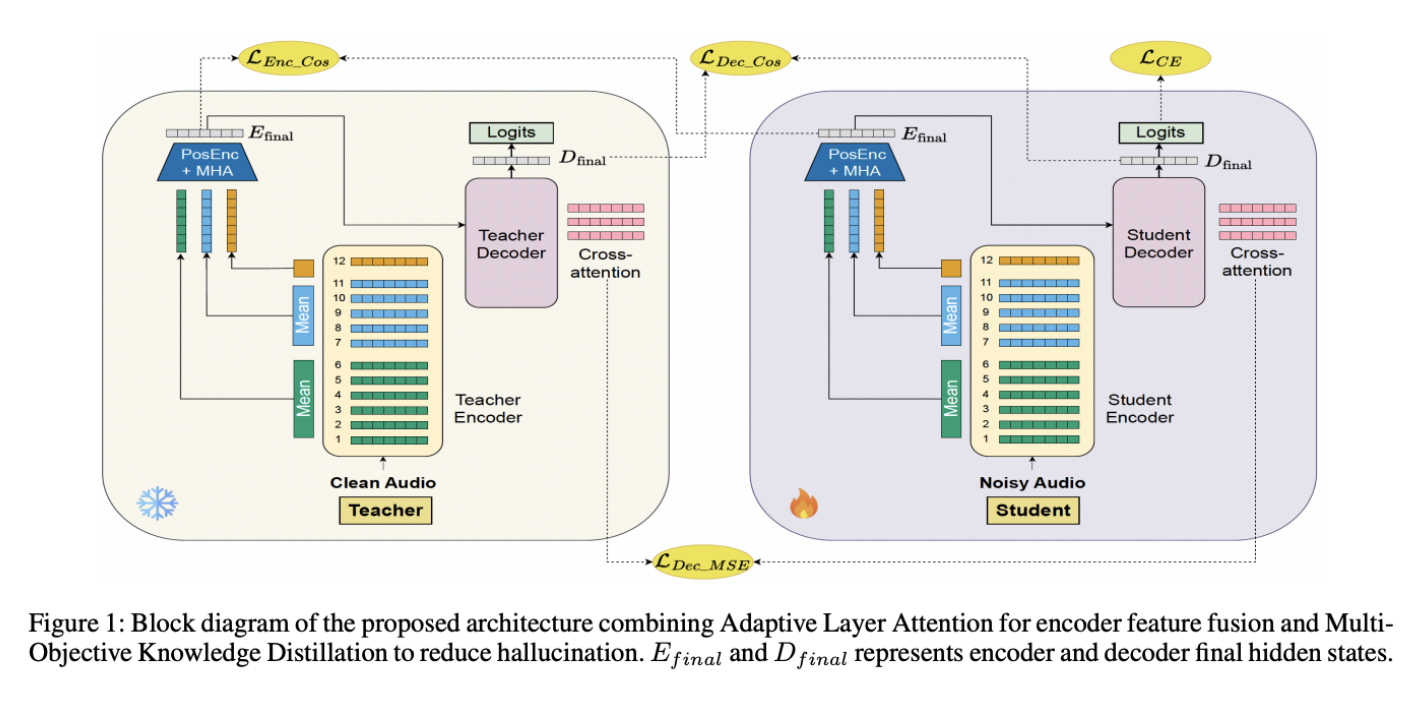
Stage 1 introduces Adaptive Layer Attention (ALA). The method groups encoder layers into semantically coherent blocks using inter-layer correlation analysis, then fuses block representations with multi-head attention. The research’s analysis shows layers naturally clustering into blocks (low-level acoustic layers vs higher-level semantic layers), and notes the final layer can diverge under noise.
Empirically, the ALA-augmented model (W-ALA) improves both transcription accuracy and semantic preservation on noisy benchmarks across Arabic, French, Hindi, and English. The research also reports the added runtime cost is modest, with small increases in latency and real-time factor, while remaining practical for modern hardware.
Stage 2 adds a multi-objective knowledge distillation framework (MOKD) that trains a noisy-audio student to align with a clean-audio teacher at multiple levels, including encoder/decoder representation similarity and decoder cross-attention alignment. In the conclusion, the researchers summarize the outcome as “substantial improvements” in word error rate and SeMaScore across languages and noise levels, improving Whisper reliability in real-world noisy environments.
Research Paper
CIP-Net: Continual Interpretable Prototype-based Network
Authors
Federico Di Valerio; Michela Proietti; Alessio Ragno; Roberto Capobianco
(Sapienza University of Rome; INSA Lyon / EPITA Research Laboratory; Sony AI)
Introduction to CIP-Net
In this research, we introduce CIP-Net, a continual learning model designed to learn new tasks over time without losing what it already knows. The work brings together two goals that are often at odds in machine learning: strong performance and clear interpretability.
What makes CIP-Net different is that it is built on prototype-based neural networks, which make predictions by comparing parts of an image to learned visual “building blocks” called prototypes. Extending PIP-Net, an interpretable prototype-based network, CIP-Net brings those same strengths to continual learning. These prototypes act like reference points; similar to recognizing a bird by its beak or wing pattern versus memorizing the entire image. Unlike post-hoc explanations, these cues are part of the model’s reasoning itself.
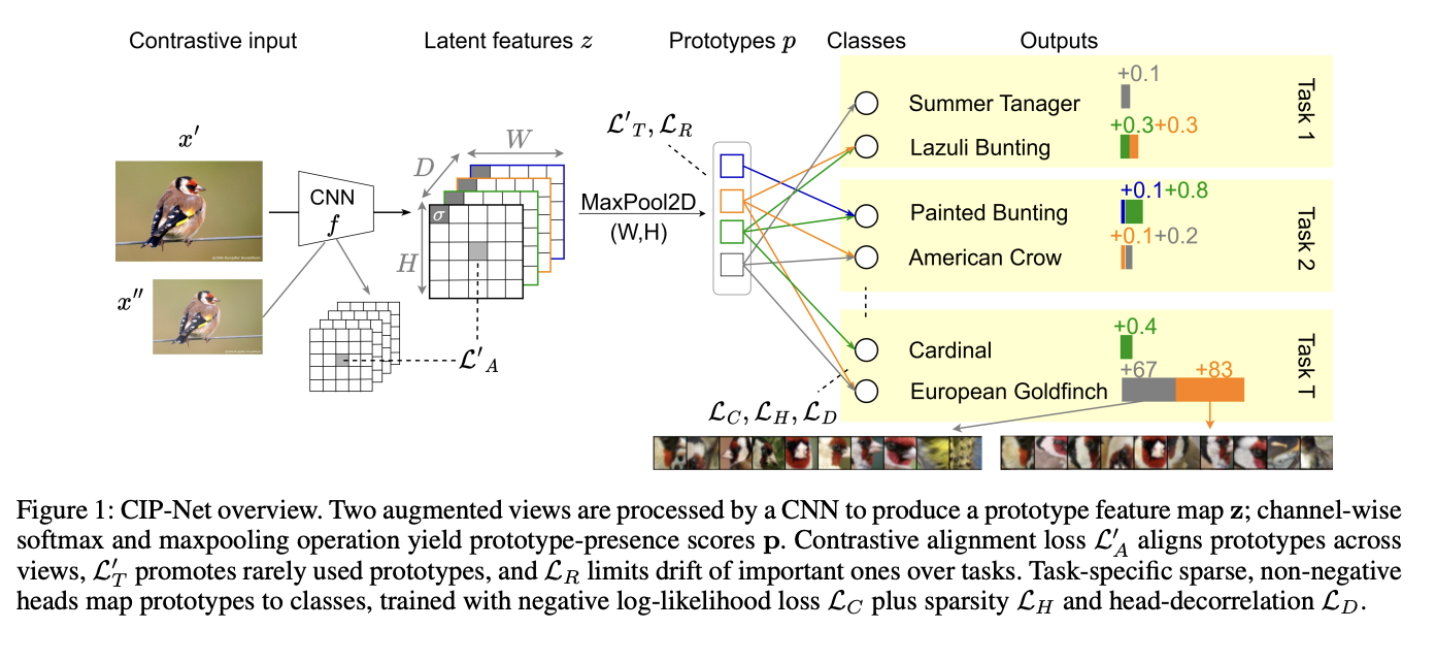
As the researchers note, CIP-Net relies on “a single fixed-size pool of shared patch-level prototypes,” which “eliminat[es] the need for exemplar storage or multiple task-specific prototype layers.” This design removes a key limitation of earlier prototype-based systems, keeping the model’s structure fixed as new tasks arrive.
Why CIP-Net Matters
Continual learning systems often struggle with “catastrophic forgetting.” Meaning, as new tasks are learned, older knowledge fades away. Many existing solutions slow this process by storing old data, replaying examples, or adding new model components over time.
CIP-Net takes a different approach. Instead, important prototypes are gently anchored so they do not drift, while less-used ones remain flexible. This allows the model to adapt without erasing earlier knowledge while keeping stable explanations.
The result is a system that stays compact and better suited for long-term learning scenarios where memory and transparency matter.
Key Challenges
The research focuses on four core challenges:
- -Catastrophic forgetting
Learning new tasks can distort earlier representations. CIP-Net selectively stabilizes prototypes that matter most to past tasks, preventing key concepts from being overwritten. - -Explanation drift
Even when predictions remain correct, explanations can quietly change over time. CIP-Net explicitly limits this drift, keeping its reasoning consistent as new tasks are introduced. - -Scalability
Prior prototype-based continual learning models grow larger with each task. CIP-Net uses a single, fixed, shared prototype pool, keeping memory and computation associated prototype-based reasoning constant, no matter how many tasks are added. - -Task interference
To prevent new tasks from reusing old reasoning paths, the model encourages sparse and decorrelated classifier heads. This helps each task develop its own “route” through the shared prototypes.
Conclusion
Across standard fine-grained continual learning benchmarks (CUB-200-2011 and Stanford Cars) CIP-Net consistently outperforms prior exemplar-free and interpretable methods in both task-incremental and class-incremental settings.
Beyond accuracy, the model’s explanations remain stable. Prototype activations change little over time, confirming that CIP-Net preserves not just performance, but also how decisions are made. Importantly, this is achieved without increasing prototype-related parameters.
In short, CIP-Net shows that continual learning does not have to trade clarity for scale. By treating prototypes as shared, well-maintained landmarks rather than disposable task-specific parts, the model learns continuously. All while keeping its reasoning intact and accessible. As the researchers explain, “By grounding every decision in a combination of shared prototypes, CIP-Net offers explanations that remain useful and stable across tasks, effectively mitigates catastrophic forgetting, and avoids the increasing memory-related overhead commonly associated with prototype-based reasoning.”
Conclusion
If you zoom out, the story across these papers is less about “bigger models” and more about better behavior. Learning new things without quietly rewriting old knowledge. Generalizing when the setting changes. Editing media in ways that preserve the core signal. Reducing confident-sounding errors in speech. For creators, that means fewer broken workflows and more intentional control. Beyond creators, it points to AI that can be deployed with clearer expectations and fewer hidden failure modes. The work Sony AI is bringing to AAAI 2026 covers both ends of that spectrum with a shared priority: make AI more usable in the real world.
If you’d like to learn more about our past presence at AAAI, please visit:
Sony AI’s Contributions at AAAI 2025
Latest Blog

March 5, 2026 | Imaging & Sensing, Sony AI
On Writing The Principles of Diffusion Models, A Q&A With Sony AI Researcher, Je…
IntroductionDiffusion models have become a go-to approach for high-quality generation; however, the field can be challenging to navigate once the paper titles and acronyms begin to…

March 2, 2026 | Sony AI
Advancing AI: Highlights from February
February at Sony AI was defined by momentum across global stages, research publications, and conversations about how AI moves from theory into practice.This month spanned responsib…

February 2, 2026 | Sony AI
Advancing AI: Highlights from January
January set the tone for the year ahead at Sony AI, with work that spans foundational research, scientific discovery, and global engagement with the research community.This month’s…

