




Sony AI at ICML: Sharing New Approaches to Reinforcement Learning, Generative Modeling, and Defensible AI
Events
Sony AI
July 14, 2025
From powering creative tools to improving decision-making in robotics and reinforcement learning, machine learning continues to redefine how intelligent systems learn, adapt, and support human goals. Recent research has focused not only on improving model performance, but also on expanding the ways in which models can generalize, collaborate with creators, and operate responsibly in open-ended environments.
As one of the premier conferences in the field, the Forty-Second International Conference on Machine Learning, ICML 2025, brings together researchers tackling these questions from multiple angles. Sony AI is proud to contribute to this year’s conference with a series of accepted papers that explore new approaches to reinforcement learning, generative modeling, and defensible AI.
This post highlights several of these contributions, including work on the Proto Successor Measure—a method that enables agents to solve entirely new tasks without retraining—and new defensive strategies to help creators detect and prevent IP infringement in generative systems. Taken together, these papers reflect Sony AI’s ongoing focus on foundational research that supports creators, enhances efficiency, and builds pathways toward more adaptive, sustainable AI.
AI for Creators
Distillation of Discrete Diffusion through Dimensional Correlations
Authors: Satoshi Hayakawa, Yuhta Takida, Masaaki Imaizumi, Hiromi Wakaki, and Yuki Mitsufuji | Main Track – Poster Presentation, ICML 2025
A Scalable Approach to Discrete Diffusion
Imagine trying to reconstruct a jigsaw puzzle, piece by piece, but you're only allowed to look at one piece at a time. You might eventually recreate the full image, but it’s going to take a while. That’s how many discrete diffusion models work today: they build up complex outputs like images or text by treating each element (a pixel, a word, a note) as if it’s floating on its own. As the authors note, “most existing discrete diffusion models rely on independent modeling across dimensions,” which limits their ability to capture the kinds of rich dependencies that actually make generative models useful.
The problem is that these elements aren’t actually independent. A note in a melody depends on the notes around it. A word makes sense in the context of the sentence. These relationships, called dimensional correlations, are critical to getting high-quality results, but most existing models only learn them indirectly, through repetition over hundreds of steps.
This paper introduces Di4C, a clever new method that helps models learn those relationships directly—and much more efficiently. The authors use a technique called distillation, where a slower, more thorough model (the “teacher”) trains a faster, lightweight version (the “student”) to mimic its results. But Di4C adds a twist: it blends multiple simple distributions together like ingredients in a recipe, creating a tractable way to reflect the rich interdependencies between elements.
But there’s a bottleneck: Modeling those correlations explicitly is computationally expensive, especially at scale. You’d need a massive amount of resources to do it the brute-force way. This scalability problem is rooted in a simple truth, as the paper explains: “explicit modeling of joint distributions over discrete variables quickly becomes intractable as dimensionality increases.” Di4C sidesteps that by teaching the student model to learn just enough structure from the teacher, using consistency-based loss functions to ensure it captures what matters, without drowning in complexity.
Why it matters: Di4C doesn’t just make discrete diffusion models faster. It makes them smarter. As the researchers summarize, Di4C “enables fast and scalable sampling while retaining the quality benefits of multi-step generation”—a balance that’s rarely achieved in discrete diffusion. It dramatically cuts down the number of steps needed to generate high-quality outputs (up to 2x faster), while preserving the richness that makes generative models useful in fields like symbolic reasoning, music, and language.
By transforming how models learn structure, Di4C offers a promising step toward scalable, expressive generative AI, ones that don’t need to choose between speed and quality.
Supervised Contrastive Learning from Weakly-Labeled Audio Segments for Musical Version Matching
Authors: Joan Serrà, R. Oguz Araz, Dmitry Bogdanov, and Yuki Mitsufuji | Main Track – Poster Presentation, ICML 2025
Building Defensive Capabilities for Creators
As music-generative models become increasingly sophisticated, so do the challenges around artist recognition and attribution. While much attention has gone toward training better systems, comparatively little has focused on enabling musicians to track how their work might reappear—intentionally or not—within AI-generated content. This paper represents one of the team’s first published efforts aimed at building defensive capabilities for creators.
At its core, the paper tackles the problem of musical version matching: identifying when different renditions represent the same musical work. Traditional approaches rely on full-track comparisons, but this method struggles when only short segments are available. This is a common scenario in remix culture, sampling, or generative outputs. The authors introduce CLEWS, a method that learns from weakly labeled, 20-second audio segments instead of entire songs.
One of the most significant challenges in version matching is that two renditions can vary dramatically (different tempos, structures, or even melodies) while still retaining a shared essence. CLEWS addresses this by reformulating contrastive learning to operate at the segment level, pairing it with novel reduction techniques that align short chunks of audio even when track-level labels are sparse or noisy.
Why this matters: segment-level detection enables fine-grained retrieval, helping identify whether a small fragment of a song has been replicated or adapted elsewhere. For musicians and rights holders, this could be a powerful tool for attribution and transparency, especially as generative models blur the lines between influence and imitation.
CLEWS outperforms existing approaches on both full-track and segment-level benchmarks, including SHS and DVI datasets. More importantly, it shifts the focus toward scalable, artist-centered strategies that keep creators in the loop—without requiring the original data to be clean, long, or precisely labeled.
To dive deeper into CLEWS, visit: https://github.com/sony/clews.
This GitHub repository includes: Model checkpoints; code for training and evaluation; and instructions for reproducing results from the paper (including segment-level version matching).
VCT: Training Consistency Models with Variational Noise Coupling
Authors: Gianluigi Silvestri, Luca Ambrogioni, Chieh-Hsin Lai, Yuhta Takida, and Yuki Mitsufuji | Main Track – ICML 2025
Fast, Stable Generation with Learned Noise Coupling
Consistency Models (CMs) have emerged as a compelling alternative to diffusion models, offering the promise of fast, few-step generative sampling. But training these models from scratch without first distilling from a pretrained diffusion model remains difficult. The culprit? High variance and instability caused by how noise is injected into the training process. In this ICML 2025 paper, the team introduces a new approach to reduce this instability: variational noise coupling.
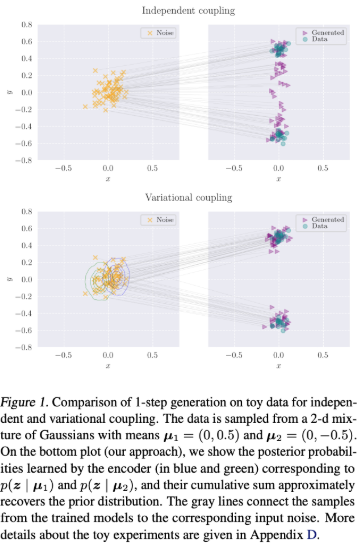
The core idea is simple but powerful. Rather than treating the noise added during training as fixed and independent of the data, the team proposes learning a data-dependent coupling between the input and the noise itself. Inspired by techniques from Variational Autoencoders (VAEs), they train a small encoder network to predict a custom noise distribution for each data point. This shifts the learning dynamics: instead of struggling with sharp, hard-to-learn transitions between noise and data, the model is guided along smoother, more learnable paths.
The main challenge lies in balancing this learned coupling with the need to preserve the overall structure of the sampling process. If the coupling diverges too far from standard Gaussian noise, the model’s ability to generalize suffers. To mitigate this, the method adds a KL divergence term (again borrowing from the VAE playbook) to regularize the learned noise distribution toward a Gaussian prior.
Why it matters: this approach stabilizes training without sacrificing speed or flexibility. On datasets like CIFAR-10, Fashion-MNIST, and ImageNet 64×64, the method consistently improves FID scores in both 1-step and 2-step generation, outperforming existing consistency models and optimal transport-based coupling strategies. Crucially, it scales well to high-dimensional data—where previous coupling methods often faltered.
Rather than reinventing consistency models, this work makes them easier to train, more stable in practice, and better aligned with the actual geometry of the data. It’s a step forward in making efficient generative models not just possible, but practical.
Game AI and Interactive Agents
Hyperspherical Normalization for Scalable Deep Reinforcement Learning
Authors: Hojoon Lee, Youngdo Lee, Takuma Seno, Donghu Kim, Peter Stone, and Jaegul Choo | Main Track – ICML 2025
Stabilizing Deep Reinforcement Learning with Geometric Constraints
As reinforcement learning (RL) agents are deployed in increasingly complex environments, scalability becomes a pressing concern. Yet training stability remains a major bottleneck.
Deep RL algorithms like Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC) are two of the most widely used methods for training agents in continuous control and they often struggle with erratic gradient magnitudes and unstable learning dynamics.
PPO is a policy-gradient method that helps an agent learn by slightly improving its decisions over time, while preventing large, destabilizing updates. SAC, on the other hand, is based on maximizing both rewards and exploration, using a stochastic policy that helps agents make diverse decisions and learn more efficiently. Despite their strengths, both approaches can become unstable as models grow larger and environments become more complex.
This paper isolates a critical factor in that instability: the magnitude of learned features. As the authors explain, “the magnitude of features can vary drastically across layers and training steps, and this issue becomes more problematic with large-scale neural networks.” This variability can undermine learning by destabilizing policy updates and value estimates.
To address this, the authors propose Hyperspherical Normalization (HSN), a method that “enforces the feature vectors to lie on a hypersphere, thereby eliminating the magnitude information and preserving only the directional information.” By standardizing feature norms throughout training, HSN reduces gradient variance and improves the consistency of learning dynamics.
Unlike batch normalization or spectral normalization alone, HSN introduces a new geometric constraint that operates directly on feature vectors. The result is a hybrid approach that “can be seamlessly applied to any existing DRL algorithm without extensive tuning or architectural changes.”
Why it matters: on tasks ranging from MuJoCo locomotion to robotic manipulation in MetaWorld, HSN improves both learning stability and performance. Perhaps more importantly, models trained with HSN “achieve significantly better generalization performance in unseen tasks,” offering a practical path toward scalable RL systems that aren’t tightly bound to narrow environments.
By refining how features are represented versus what they represent, this work takes a measured step toward more robust, general-purpose reinforcement learning.
PPML
Evaluating and Mitigating IP Infringement in Visual Generative AI
Authors: Zhenting Wang, Chen Chen, Vikash Sehwag, Minzhou Pan, and Lingjuan Lyu | Main Track – ICML 2025
Defending Creativity
Visual generative AI models are increasingly becoming integrated into creative workflows, while concerns over unauthorized reuse of protected content are growing at a similar pace. This paper presents one of the first large-scale efforts to systematically evaluate and mitigate intellectual property (IP) infringement risks in state-of-the-art visual generative AI systems.

The authors find that leading models like DALL-E 3, Midjourney, and Stable Diffusion routinely generate content that “bears a striking resemblance to characters protected by intellectual property rights,” even when names are not explicitly mentioned. Using carefully designed “lure prompts,” the team reveals that models can produce near-replicas of characters like Spider-Man, Iron Man, and Super Mario based on only descriptive cues.

To combat this, the team introduces TRIM (inTellectual pRoperty Infringement Mitigating)—a novel defense method that “detects the generated contents that potentially has the IP infringement issues and suppresses the IP infringement by exploiting the guidance technique for the diffusion process.” TRIM operates entirely in a black-box setting and requires no fine-tuning or retraining of the original model.
The biggest challenge is maintaining the balance between protecting creators’ rights and preserving model usability. TRIM achieves this by integrating LLMs and vision-language models (like GPT-4V) to identify and suppress infringing outputs while maintaining image quality and text alignment. As the authors note, “our mitigation method is highly effective… while only having a small influence on the overall quality of the generated content.”
Why it matters: In an era where AI models are trained on massive, often uncurated or scraped datasets, it’s becoming harder for artists and rights holders to maintain control over their creations. This work not only highlights how easily models can reproduce protected content, it also proposes a concrete framework for mitigating that harm to creators. By formalizing the problem and offering an actionable defense, this research helps lay the groundwork for creator-conscious generative AI.
Enhancing Foundation Models with Federated Domain Knowledge Infusion
Authors: Jiaqi Wang, Jingtao Li, Weiming Zhuang, Chen Chen, Lingjuan Lyu, Fenglong Ma | Main Track – ICML 2025
Improving Vision Foundation Model through Federated Learning
Vision foundation models (FMs) like CLIP have exhibited exceptional capabilities in visual and linguistic understanding, particularly in zero-shot inference tasks. However, these models struggle with data that significantly deviates from their training samples, resulting in a much worse zero-shot performance (CLIPZ) and standard Federated Learning (FL) performance (finetune one adapter, denoted as CLIPO) compared to performance upper bound (finetune multiple adapters, denoted as CLIPM).
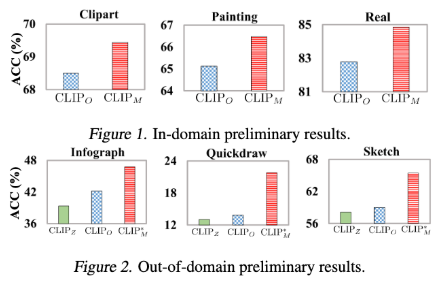
To address the problem, the team proposes a cross-silo Federated Adapter Generalization (FedAG), a novel federated fine-tuning approach that leverages multiple fine-grained adapters to capture domain-specific knowledge while enhancing out-of-domain generalization.
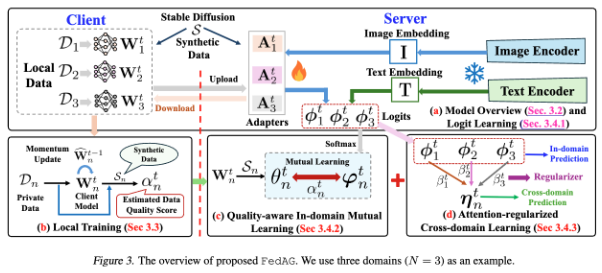
The proposed scheme is shown in Figure 3. Intuitively, the types of domains for a specific task are usually limited, and the data belonging to a domain is usually collected by a specific client. This motivates authors to design a new model under the cross-silo federated learning setting and allow all clients to be involved in the learning at each communication round. Besides, this setting also allows the team to employ multiple fine-grained adapters to inject domain-specific knowledge into corresponding adapters while enhancing the capability of out-of-domain knowledge generalization by jointly combining these adapters.
Proto Successor Measure: Representing the Space of All Possible Solutions of Reinforcement Learning
Authors: Siddhant Agarwal, Harshit Sikchi, Peter Stone, and Amy Zhang | Main Track – ICLR 2025
How to Solve Tasks Without Starting From Scratch
Most reinforcement learning (RL) systems are built like single-purpose tools. They’re trained to solve one task, and when the task changes, the agent needs to start all over. But what if we built agents like seasoned globetrotters instead? The types that are able to learn a city once and then find their way to any destination without a map?
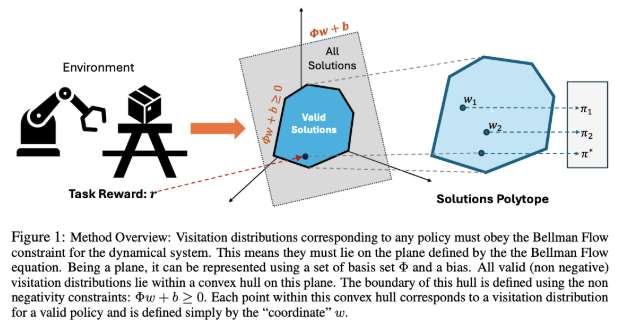
This paper introduces the Proto Successor Measure (PSM), a framework that aims to do just that. It treats reinforcement learning not as a series of separate tasks, but as a geometry problem: imagine every possible agent behavior as a point on a plane. The PSM learns the underlying shape of that space; essentially, the blueprint of how the environment works, without knowing what future tasks will be.
At the heart of the method is a clever simplification: instead of learning separate strategies for each reward, PSM learns a set of universal building blocks (called basis functions) that can be mixed and matched to express any valid behavior. As the authors explain, “any possible policy can be represented using an affine combination of these policy-independent basis functions.”
The result is an agent that doesn’t need to retrain for each new task. Once the basis is learned, the only thing left to do is pick the right combination to match the new reward: no additional environment interactions required. In practical terms, that means zero-shot policy generation with strong performance across navigation, manipulation, and continuous control domains.
Why it matters: This work reframes general-purpose RL as a representation learning problem. Rather than solving task after task independently, PSM compresses the environment into a reusable structure, a lot like learning the grammar of a language instead of memorizing every possible sentence. It’s a conceptual leap toward agents that adapt like some humans: explore once, remember forever.
Workshops
The Impact of Memorization on Trustworthy Foundation Models
West Meeting Room 223-224
Sat 19 Jul, 8:30 a.m. PDT
Researchers: Franziska Boenisch, Adam Dziedzic, Dominik Hintersdorf, Lingjuan Lyu, Niloofar Mireshghallah, Lukas Struppek
Foundation models have come to underpin many critical applications, such as healthcare, public safety, and education. Ensuring their trustworthiness is, therefore, more important than ever.
However, recent research has revealed that foundation models are prone to memorizing details or even entire samples from their training data. This issue can lead to privacy violations, intellectual property infringement, and societal harm when sensitive information is leaked. While unintended memorization risks the integrity of models, a certain degree of it is essential for solving novel and complex tasks, highlighting the importance of balancing performance with data leakage.
By bringing together researchers and practitioners from diverse fields, we seek to bridge the gap between research and real-world applications, fostering the development of trustworthy foundation models that benefit society without compromising sensitive data, intellectual property, or individual privacy.
Learn More: Workshop Details
Large-Scale Training Data Attribution for Music Generative Models via Unlearning Workshop on Machine Learning for Audio – Oral Presentation, ICML 2025
Researchers: *Woosuing Choi, *Junghyun Koo, *Kin Wai Cheuk, Joan Serrà, Marco A. Martínez-Ramírez, Yukara Ikemiya, Naoki Murata, Yuhta Takida, Wei-Hsiang Liao, and Yuki Mitsufuji
White-Box Attribution for AI-Generated Music
As AI-generated music becomes increasingly common on streaming platforms, it raises urgent questions around ownership, attribution, and compensation. Traditional licensing frameworks allow music companies to earn royalties when their songs are used, but generative models complicate this system. These models are trained on large music datasets and can produce new tracks that are stylistically influenced by existing songs, even without directly copying them.
To address this, our work explores training data attribution (TDA) for generative models: identifying which training tracks most influenced a generated output. We focus on a text-to-music diffusion model trained on 115,000 music tracks, and introduce a white-box TDA method using machine unlearning to estimate attribution. To our knowledge, this is the first large-scale study of TDA in music generation, offering a practical step toward transparency and fairness in the GenAI era.
Training Data Attribution
As generative models reshape music creation, it's increasingly important to understand which training tracks influenced a given generated output. Simple attribution approaches rely on corroborative or similarity-based methods, which compare the generated sample to training data using external encoders. While practical, these methods treat the generative model as a black box and may not reflect how it internally relates to its training data.
To address this, the paper explores a counterfactual-inspired approach using machine unlearning. Rather than retraining the model without each training point, which is computationally infeasible, this work explores unlearning just the generated sample and observe which training tracks are most influential to the generated sample. This enables white-box, model-aware attribution at scale, providing a more faithful view of how generative models draw from their training data.
This work demonstrates the feasibility of applying unlearning-based attribution methods to large-scale music generative models. Through controlled experiments on known training data, we verified that our approach reliably identifies influential examples. When extended to generated outputs, the attribution results showed distinct patterns compared to similarity-based methods: revealing sharper, more concentrated influence profiles that suggest deeper alignment with the model’s internal reasoning.
Why It Matters: While definitive ground-truth attribution remains elusive in generative modeling, our study takes a crucial step toward practical, scalable attribution for music models. In an era where AI-generated music is rapidly increasing, having transparent tools to trace generative content back to training data is essential for fair recognition and compensation of original artists.
By enabling white-box, model-aware attribution at scale, this work contributes to building the technical foundation for ethical and sustainable music ecosystems in the GenAI age. As the boundaries between creation and computation blur, training data attribution offers one path to ensure accountability, traceability, and respect for creative labor.
Conclusion
Across these contributions, a common thread emerges: how to build systems that understand the environment once and adapt infinitely. Whether it’s learning reusable building blocks for decision-making, designing models that defend creator rights, or reducing training time through more stable architectures, each paper contributes to a vision of machine learning that is less about iteration and more about transfer, reuse, and trust.
These advances deepen our understanding of how intelligent systems can learn from the world. They also demonstrate our broader commitment to supporting creativity and generalization through principled, scalable research.
Further Reading: Rediscover our ICML contributions from last year to learn how we are evolving our contributions.
Latest Blog

March 5, 2026 | Imaging & Sensing, Sony AI
On Writing The Principles of Diffusion Models, A Q&A With Sony AI Researcher, Je…
IntroductionDiffusion models have become a go-to approach for high-quality generation; however, the field can be challenging to navigate once the paper titles and acronyms begin to…

March 2, 2026 | Sony AI
Advancing AI: Highlights from February
February at Sony AI was defined by momentum across global stages, research publications, and conversations about how AI moves from theory into practice.This month spanned responsib…

February 2, 2026 | Sony AI
Advancing AI: Highlights from January
January set the tone for the year ahead at Sony AI, with work that spans foundational research, scientific discovery, and global engagement with the research community.This month’s…

