
As AI continues to advance, researchers are developing new methods to improve language translation and speech synthesis with greater accuracy and cultural awareness. At the upcoming 2025 AAAI Conference, Sony AI is presenting two research papers that push the boundaries of AI for localization and voice synthesis.
The first, CASAT (Context And Style Aware Translation), redefines neural machine translation (NMT) for Indian languages, ensuring that cultural nuances and emotional depth are preserved in content localization. The second, EmoReg, introduces a novel diffusion-based emotional voice conversion framework that gives AI-generated speech the ability to convey precise emotional intensity—making AI-driven dubbing, audiobooks, and voice assistants more lifelike than ever.
These advancements represent a leap toward context-aware, culturally adaptive, and emotionally expressive AI. Let’s dive into the details.
CASAT: Enhancing Translation for Indian Languages
Introduction: Why This Research Matters
Localization is critical for making content accessible to diverse audiences worldwide. In India, where linguistic diversity thrives, translating content presents unique challenges. As the research team notes, “Traditional NMT systems typically translate individual sentences in isolation, without facilitating knowledge transfer of crucial elements such as the context and style from previously encountered sentences.”
The research, led by Pratik Rakesh Singh, Mohammadi Zaki, and Pankaj Wasnik from Sony AI, proposes innovative solutions for translating dialogue while preserving context, style, and cultural nuances. This research and the forthcoming novel framework is the first of its kind, enhancing audience engagement but also paving the way for more inclusive experiences.
The Problem: Challenges in Retaining Context and Culture
Despite advances in neural machine translation (NMT), traditional models in the media and entertainment domain fall short. Common issues include:
- Lack of context-awareness: Dialogues often lose meaning when translated in isolation.
- Inability to handle cultural nuances: Idioms, jokes, and dialects are often mistranslated.
- Creativity deficit: Translations fail to reflect the tone, emotion, and artistic intent of the source material.
Such shortcomings result in phrases that lose their cultural punch. Take, for example, the Hindi-to-English mistranslation, “I will badmouth you by knocking door to door,” which not only misses the idiomatic expression but also produces a comical output, to say the least.

The Solution: How CASAT Overcomes These Challenges
The researchers introduced CASAT (Context And Style Aware Translation) a framework that enriches translations through:
1. Context Retrieval Module: A system that segments dialogues into sessions and retrieves context from relevant scenes.
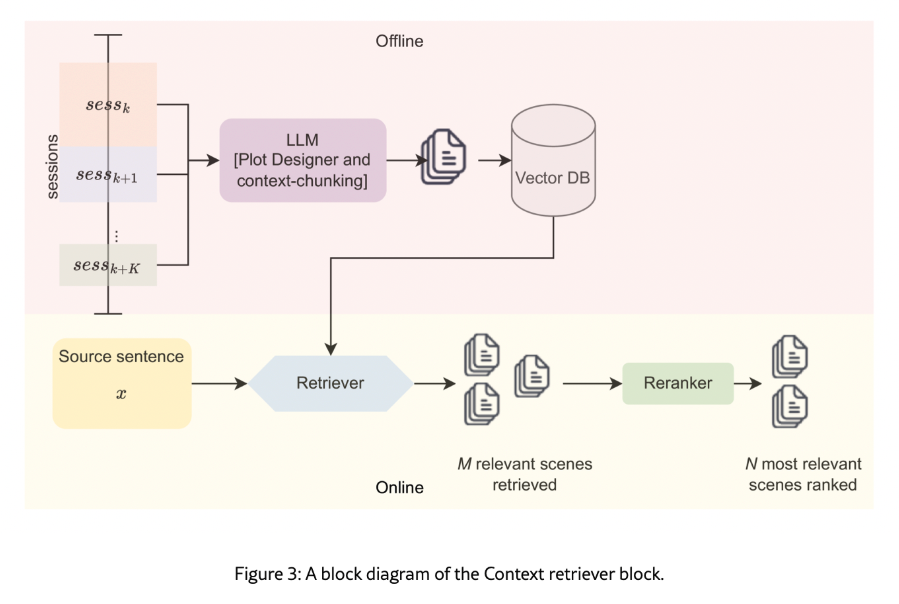
2. Domain Adaptation Module (DAM): This analyzes linguistic styles, idioms, and emotional tones to guide large language models (LLMs).
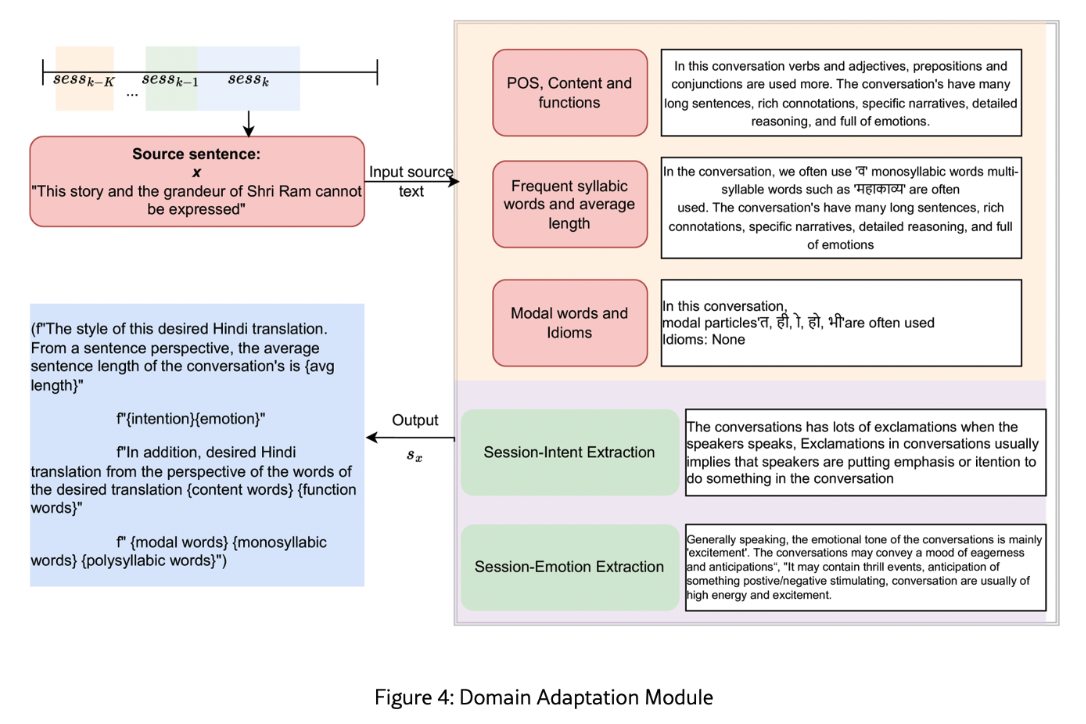
The CASAT framework employs LLMs for creative translations while ensuring cultural and stylistic accuracy. This methodology is both language- and model-agnostic, allowing adaptation to various Indian languages such as Hindi, Bengali, and Telugu.
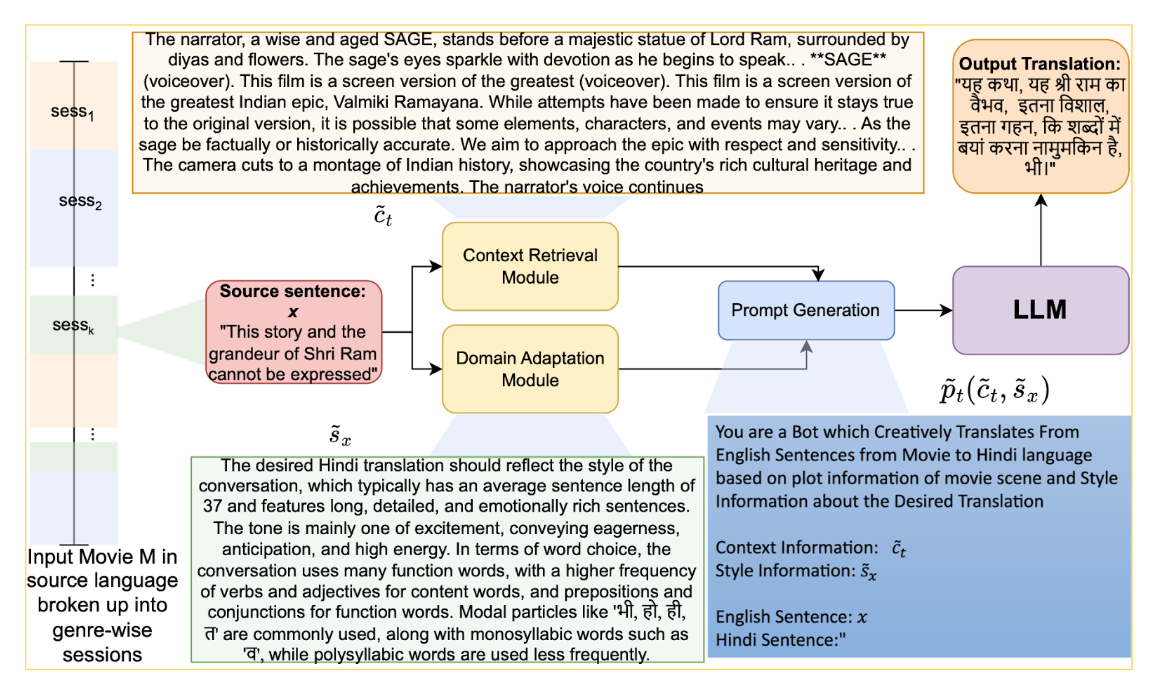
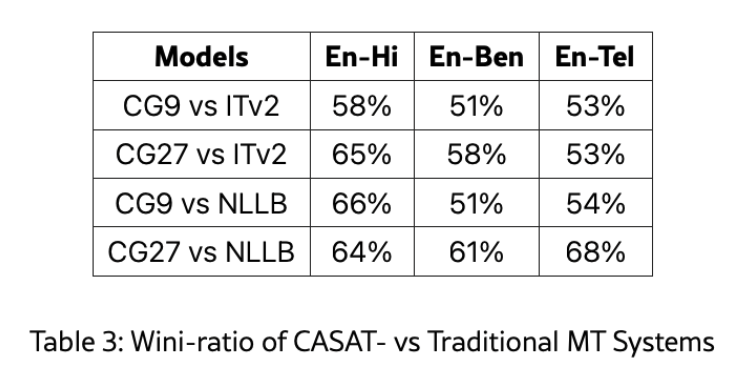
Results: Achieving Superior Translations
CASAT demonstrated significant improvements over baseline LLMs:
- COMET Scores: CASAT-enhanced models consistently scored higher across English-to-Hindi, English-to-Bengali, and English-to-Telugu translations, surpassing traditional systems like IndicTrans2.
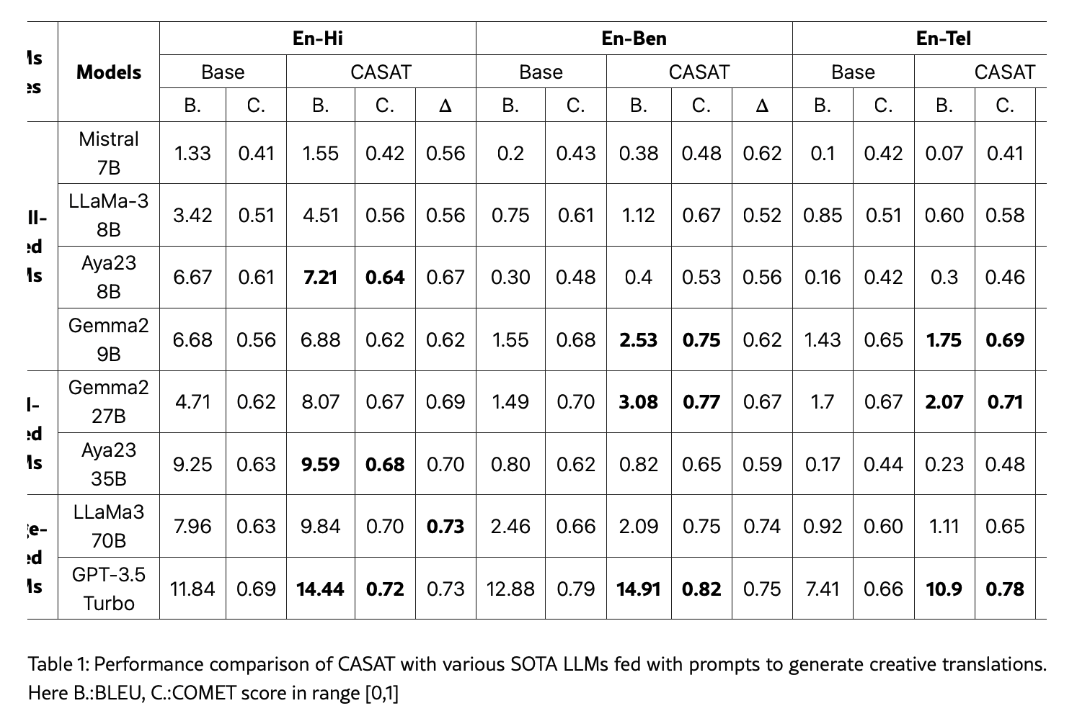
- Win-Ratio: Human evaluators preferred CASAT translations due to their emotional richness and cultural relevance.
For instance, CASAT’s translation of "I am aware that history will perhaps remember me as a traitor" retained its idiomatic and contextual meaning in Hindi: "शायद इतिहास मुझे घर का भेदी कहे।"
Why These Results Matter
This research is transformative for the media, entertainment and content industry:
- Enhanced Viewer Experience: Translations that capture context and culture foster greater audience connection.
- Broader Accessibility: The framework empowers content creators to reach multilingual audiences effectively.
- Innovation in Translation Technology: CASAT sets a precedent for context-aware, culturally adaptive translation systems.
Conclusion
The CASAT framework revolutionizes translation by bridging the gap between linguistic accuracy and cultural resonance. This research not only addresses existing limitations but also opens doors to more inclusive and engaging global storytelling.
EmoReg: A New Frontier in Emotional Voice Conversion
Introduction: Why This Research Matters
Despite significant progress in AI-driven voice synthesis, emotional voice conversion (EVC) remains a complex challenge. While current text-to-speech (TTS) and dubbing systems can generate high-quality speech, they often lack fine-grained control over emotional intensity, leading to unnatural or exaggerated emotional expressions. This gap in technology necessitated the research behind EmoReg: Directional Latent Vector Modeling for Emotional Intensity Regularization in Diffusion-based Voice Conversion.
As the researchers state: “AI-based dubbing involves replicating input speech emotion and controlling its intensity depending on the context and emotion of the scene.” However, existing models struggle to manipulate emotional intensity in a controlled and scalable manner. EmoReg, developed by Sony AI in collaboration with IIIT Delhi, introduces a novel Directional Latent Vector Modeling (DVM) technique within a diffusion-based framework to achieve precise emotional intensity control while maintaining natural speech quality.
The Problem: Challenges in Emotional Voice Conversion
EVC faces multiple roadblocks that hinder its effectiveness:
- Data Limitations: High-quality, annotated emotional speech datasets are scarce, and manually labeling intensity levels is expensive and time-consuming.
- Inconsistent Emotional Mapping: Many existing systems rely on categorical labels (e.g., happy, sad, angry) or predefined intensity scales, which often fail to capture the subtle variations of human emotions.
- Lack of Fine Control Over Emotional Intensity: Traditional methods rely on simple scaling or interpolation, which do not effectively model the gradual shift in emotions. “Manipulating learned emotion representations via scaling or interpolations does not work well since emotional embedding space does not align well with the assumption of linear interpolation,” the researchers further explained.
Existing solutions often lead to artifacts and quality degradation, making them unsuitable for professional applications like movie dubbing, audiobooks, and virtual assistants.
The Solution: How EmoReg Overcomes These Challenges
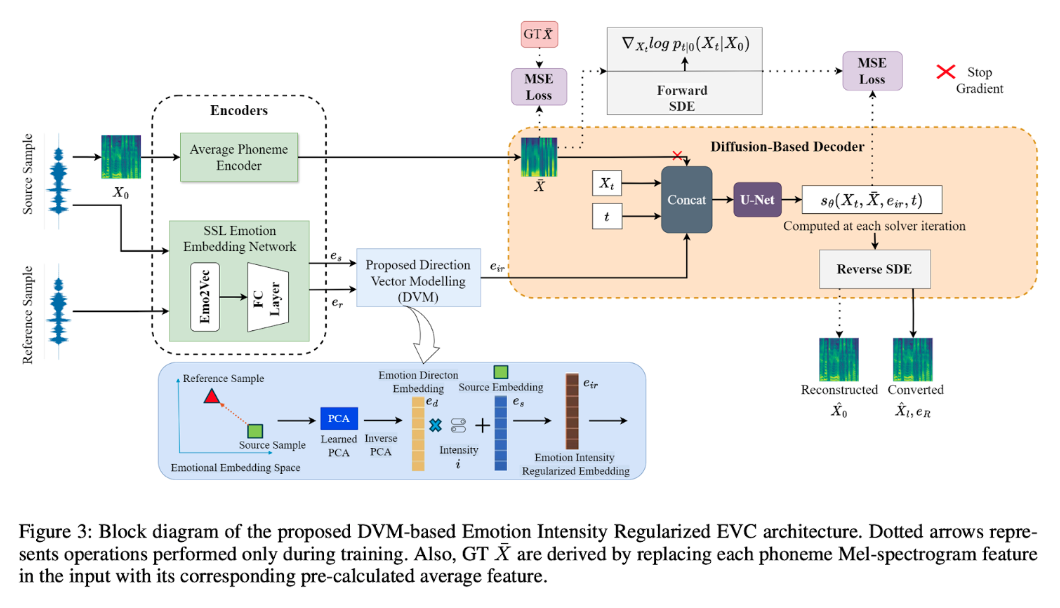
To address these issues, the researchers introduce a diffusion-based approach powered by self-supervised learning (SSL) and directional latent vector modeling (DVM).
- Self-Supervised Learning for Emotion Representation
Rather than relying on expensive labeled datasets, “[W]e fine-tune the pre-trained SSL emotion2vec embedding network using English and Hindi emotional speech databases to learn emotional embedding representations.” This model extracts 768-dimensional emotion embeddings, which are then fine-tuned for emotion classification.
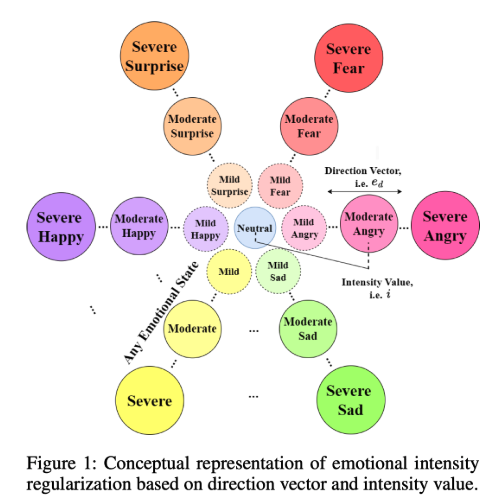
- Directional Latent Vector Modeling (DVM) for Emotional Intensity Control
Unlike traditional methods that apply static emotion intensity scaling, DVM dynamically modifies emotion embeddings based on direction vectors derived from real emotional speech. “We modeled the emotion embedding space using a 64-component Gaussian Mixture Model (GMM) to derive the local mean vector for each emotion.” By computing the difference vector between neutral speech and target emotions (e.g., Happy, Angry, Sad), DVM allows fine-grained control over intensity in a way that closely mimics natural emotional expression.
- Diffusion-Based Voice Conversion for High-Quality Output
A diffusion probabilistic model ensures that speech generated through EmoReg retains clarity, naturalness, and expressiveness across varying intensity levels. “Diffusion models serve as samplers, producing new samples while actively guiding them toward task-desired features,” the researchers explain. This results in smoother emotion transitions compared to GAN-based or interpolation-based approaches.
Results: How EmoReg Outperforms Existing Methods
To evaluate EmoReg’s effectiveness, researchers conducted a series of objective and subjective tests comparing it against state-of-the-art (SOTA) EVC methods, including EmoVox, Mixed Emotion, CycleGAN-EVC, and StarGAN-EVC.
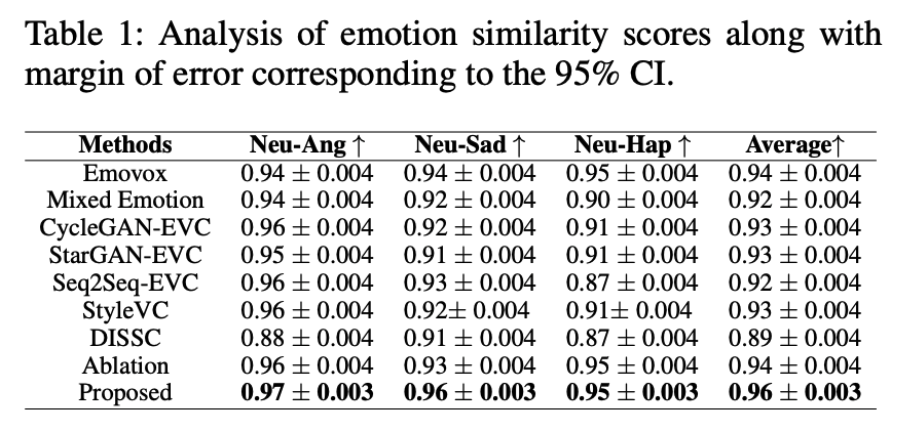
- Higher Emotion Similarity Scores
“The proposed EmoReg with DVM outperforms all SOTA approaches in emotion similarity scores, achieving a 2%–11% improvement,” the researchers note, meaning EmoReg consistently outperformed baseline models in maintaining emotional similarity to target speech.
- EmoVox: 0.94
- Mixed Emotion: 0.92
- Proposed EmoReg: 0.97
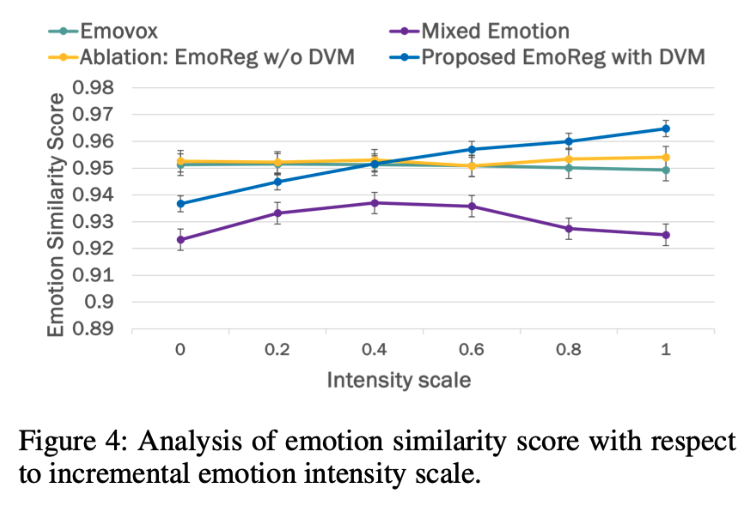
For example, in the Neutral-to-Angry conversion task, the models scored the following:
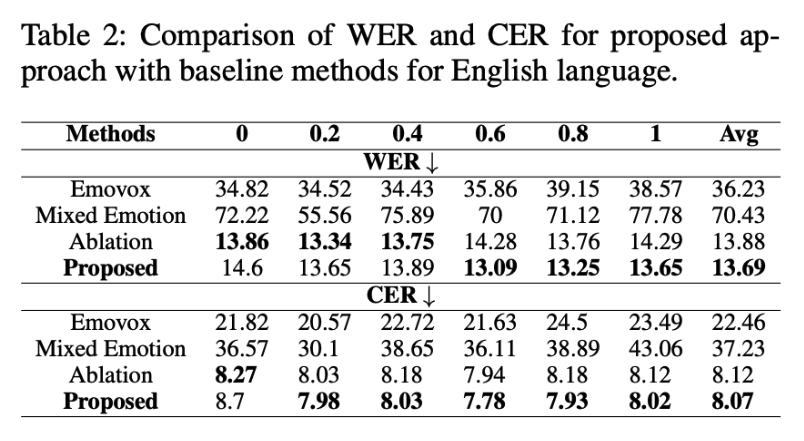
- Superior Speech Intelligibility (WER and CER)
Word Error Rate (WER) and Character Error Rate (CER) were used to measure how well the converted speech retained linguistic clarity. EmoReg achieved lower WER and CER scores than other models.
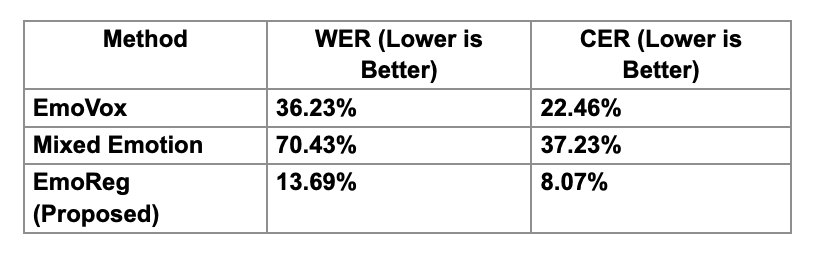
These results support the claim that EmoReg preserves linguistic integrity even when modifying emotional intensity.
- Higher Mean Opinion Scores (MOS)
A subjective listening test was conducted where participants rated speech quality from 0 to 100. EmoReg was rated 13.56% better than EmoVox and 43.13% better than Mixed Emotion. As the researchers explain, “Diffusion model-based architectures are one key reason for achieving high-quality output.”
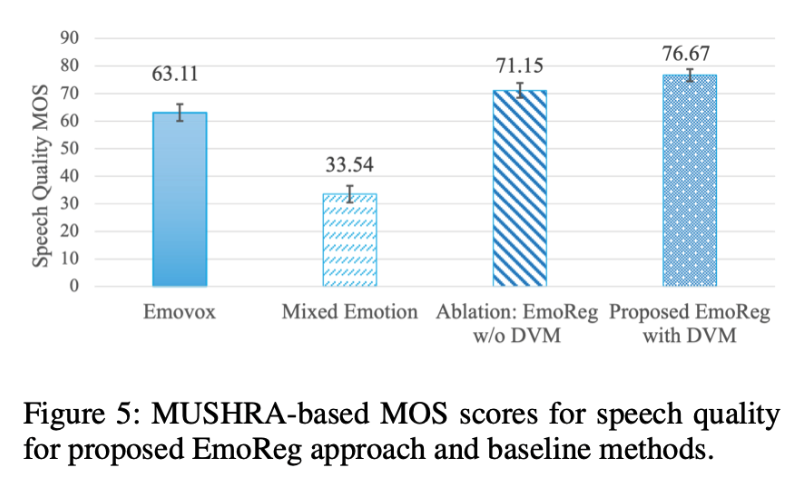
Why These Results Matter
The breakthroughs achieved by EmoReg have real-world implications for entertainment and AI-generated speech:
- Improved AI Dubbing for Movies & TV
- AI-generated voices can now accurately replicate the emotional depth of human actors.
- More Expressive Virtual Assistants
- Voice AI (e.g., Siri, Alexa, Google Assistant) can sound more human-like and emotionally aware.
- Personalized Audiobooks & Podcasts
- Audiobooks can now be emotionally adapted to match the tone of the story.
- Cross-Lingual Applications
- EmoReg has been tested in both English and Hindi, proving its adaptability to multiple languages.
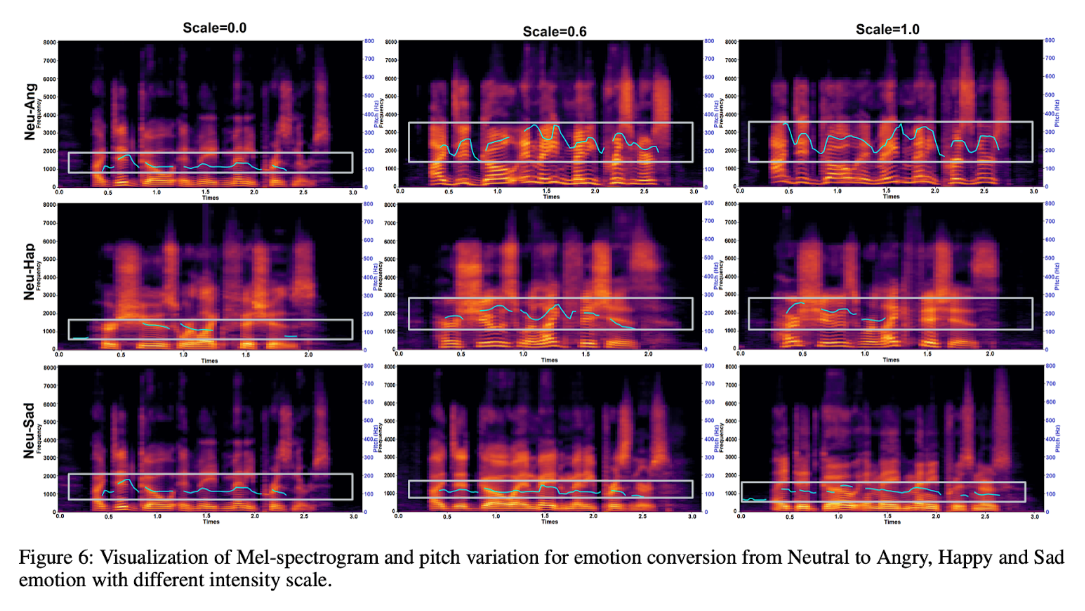
Conclusion
EmoReg represents a paradigm shift in AI-driven voice conversion by introducing directional vector modeling for precise emotion control. Unlike traditional methods, it allows for smooth, natural, and high-quality emotional speech transformation without sacrificing clarity.
Key takeaways from this research:
✔ First-ever diffusion-based EVC model with intensity regularization
✔ Outperforms SOTA models in emotion similarity, WER, and MOS
✔ Scalable for real-world applications in dubbing, voice assistants, and audiobooks
“Future work will focus on extending this framework to handle complex environments, such as background music or noise,” making it even more robust for real-world speech synthesis applications.
Conclusion: Pioneering the Future of AI for Localization and Voice Synthesis.
Our contributions to AAAI 2025 mark a significant step forward in AI-driven voice, translation, and speech technologies. CASAT brings a new level of contextual and stylistic awareness to machine translation, ensuring that Indian-language entertainment retains its cultural authenticity and emotional depth. Meanwhile, EmoReg sets a new benchmark in emotional voice conversion, enabling AI-generated speech to capture the subtle nuances of human expression with unprecedented clarity and control.
Together, these innovations bridge critical gaps, making localized content more engaging, immersive, and inclusive for diverse audiences. As these technologies evolve, they have the potential to reshape storytelling, voice synthesis, and media accessibility—bringing us closer to AI that understands and communicates as humans do.


