




Unleashing the Potential of Federated Learning with COALA
PPML
July 26, 2024
We are thrilled to announce that the latest research from our Privacy Preserving Machine Learning (PPML) Flagship, COALA, has been accepted at the prestigious International Conference on Machine Learning (ICML) this month. This recognition underscores the innovative strides we are making in the realm of federated learning, particularly within the context of computer vision. Federated Learning (FL) revolutionizes computer vision tasks by enabling collaborative model training on decentralized data, empowering AI development with privacy, scalability and accuracy while showcasing the immense value of distributed learning. COALA adds to the power and effectiveness of FL. Let’s delve into what makes COALA unique, the groundbreaking methodology behind it, the challenges we face, and its potential applications.

Introducing COALA
Despite the COALA name resembling those adorable Australian mammals, our COALA is the first vision-centric FL platform that supports various computer vision tasks. FL solves several pressing problems in AI and machine learning, including the need to protect sensitive data, the challenge of managing data spread across multiple locations, and the difficulty of maintaining data quality and consistency. These issues are particularly relevant in fields such as healthcare, finance, and smart cities, where data is both highly valuable and sensitive. By keeping data localized, FL minimizes the risk of data breaches and enhances compliance with data protection regulations like GDPR and HIPAA.
Unlike other FL platforms — COALA leverages Sony’s extensive expertise in imaging and sensing to deliver unparalleled performance and flexibility. COALA enhances the impact of FL by integrating new paradigms such as Federated Parameter-Efficient Fine-Tuning (FedPEFT) and supporting multiple customization levels, which are crucial for real-world deployments.
COALA has the potential to redefine FL and its applications. The platform can be accessed directly from the source code, allowing developers and researchers to run FL applications and experiments with out-of-the-box datasets and algorithms, as well as customize their usage at three levels:
- Configuration Customization: Users can customize the datasets, models, and algorithms by simply changing the configuration of the FL platform.
- Component Customization: Users can develop new applications by writing their own training logic and algorithms for the client and server components as plugins to the platform while reusing the rest of the platform.
- Workflow Customization: Users can customize the entire FL training workflow.
Our research describes COALA as a platform that "offers extensive benchmarks for diverse vision tasks and various new learning paradigms in FL," highlighting its comprehensive and up-to-date support for current FL studies. By tackling the core challenges of federated learning in computer vision, COALA offers a future where AI can learn and grow smarter while safeguarding privacy. For more details and access to the source code, visit the COALA GitHub repository.
Why COALA is Groundbreaking
COALA stands out for several reasons. First and foremost, it supports 15 different computer vision tasks, including classification, object detection, segmentation, pose estimation, and more — making it the most comprehensive vision-centric FL platform available. Additionally, COALA handles various data levels — including supervised, semi-supervised, and unsupervised data — adapting to feature and label distribution shifts. This flexibility is crucial for real-world applications where data evolves over time.
COALA advances the impact of FL by providing extensive benchmarks and supporting a wide range of practical FL scenarios. At the task level, COALA extends support from simple classification to 15 diverse computer vision tasks, facilitating federated multiple-task learning. This enables clients to tackle multiple tasks simultaneously, significantly enhancing efficiency and performance.
COALA supports federated continual learning, enabling the platform to remain effective even as data patterns change dynamically. Our research elaborates on this capability, noting that COALA "expands upon supervised FL and label distribution shift in data heterogeneity: it can support semi-supervised FL, unsupervised FL, and multi-domain FL with feature distribution shifts among local training data."
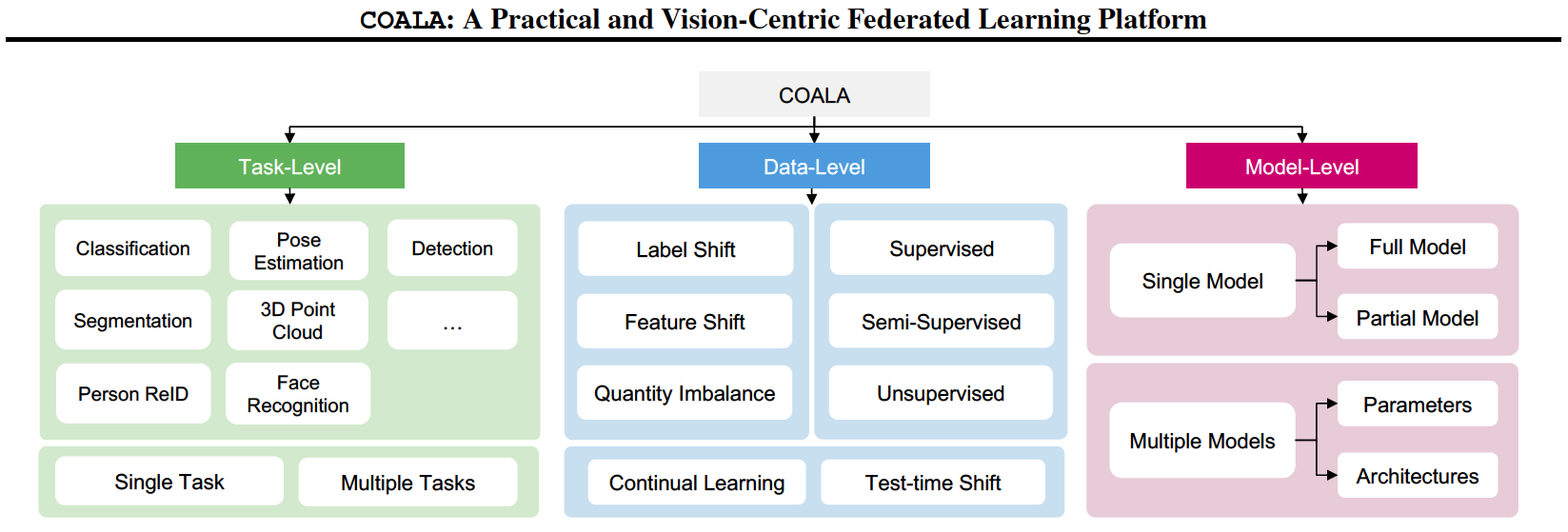
Figure 1. Illustration of three levels of practical FL scenarios supported by COALA. At the task level, we support diverse CV tasks and training of multiple tasks in FL. At the data level, we offer out-of-the-box benchmarks for different types of data heterogeneity, various degrees of data annotation availability, and dynamic changes in data. At the model level, we extend beyond single and full model FL training to split model training and multiple model training with different architectures or parameters on clients.
At the data level, COALA goes beyond traditional supervised FL by benchmarking semi-supervised and unsupervised FL, as well as handling various types of data distribution shifts such as feature shift, label shift, and test-time shift. This comprehensive approach allows COALA to adapt to continuously changing data in real-world or potential scenarios, ensuring models remain robust and effective.
At the model level, COALA introduces federated split learning and personalized federated learning. It is the first platform to use Federated Parameter-Efficient Fine-Tuning (FedPEFT) for developing foundation models, pushing the boundaries of what is achievable with FL. This innovation is crucial for enhancing model efficiency and performance across diverse tasks. Our research paper emphasizes that COALA "seamlessly supports new FL scenarios with three degrees of customization: configuration customization, components customization, and workflow customization," ensuring it can be tailored to meet specific needs and scenarios.
COALA also addresses the challenges of data heterogeneity by supporting federated multiple-model training, where clients can train multiple models with varying parameters and architectures. This is essential for accommodating the diverse computational resources and data distributions found in real-world applications. Furthermore, COALA's ability to benchmark FL with split models and different models in different clients demonstrates its robustness and flexibility.
By integrating these advanced capabilities, COALA not only enhances the power and effectiveness of FL but also ensures that data privacy is maintained without sacrificing performance. This is particularly important in industries where data sensitivity is a major concern, such as healthcare and finance. COALA's innovative approach to FL enables the development of high-performing AI models while keeping data decentralized, thus preserving privacy and meeting regulatory requirements.
Methodology and Past Advancements
COALA’s development builds upon years of advancements in federated learning and computer vision. The platform's support for multi-task learning sets it apart from traditional FL platforms that focus on single-task learning. COALA enables simultaneous training of multiple tasks, significantly enhancing efficiency and performance. This is particularly important as federated learning scales to more complex and varied applications. Our research highlights, "COALA facilitates federated multiple-task learning, enabling clients to simultaneously train on more than one task," which enhances performance and resource utilization.
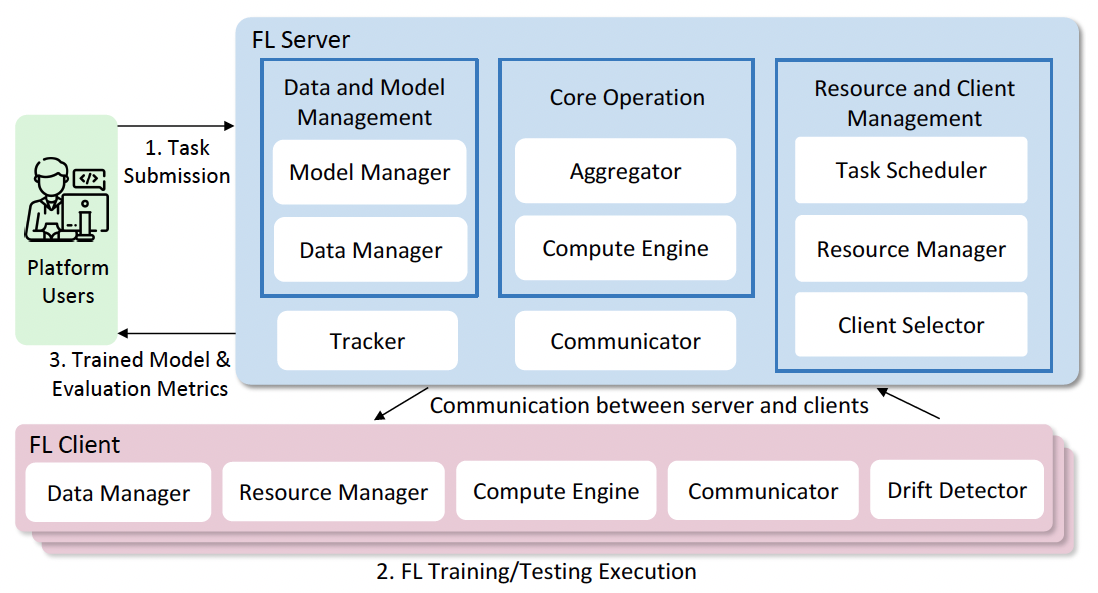
Figure 2. Illustration of COALA platform that enables automated benchmarking for practical FL scenarios.
Moreover, COALA’s ability to handle continual learning scenarios allows it to adapt to changing data patterns, ensuring models remain up-to-date without compromising privacy. "COALA provides flexible support for different data patterns arising in FL, including the distribution shift (label shift, feature shift, test-time shift), quantity imbalance, continual learning, and different availability of data annotations," the authors note. This adaptability is crucial for real-world deployments where data is continuously generated and updated. The customizable workflows further enhance the platform's flexibility, allowing users to tailor it to specific needs and scenarios.
Challenges and Approach
The journey to COALA’s development was not without its challenges. Addressing the complexity of diverse FL applications and algorithms integrated effectively into a cohesive system was a primary hurdle, as real-world scenarios and applications are varied. COALA tackles this through a modular and plugin-based system design. This approach allows for seamless incorporation of different algorithms and applications, ensuring that the system remains flexible and robust in diverse real-world environments. Providing a customizable framework that supports different degrees of customization while maintaining good utility was another challenge. COALA addresses this by offering a highly flexible design that allows users to tailor the system to their specific requirements. This includes customization at various levels, such as configuration, components, and workflow, enhancing the platform’s utility across different use cases.
Additionally, handling large-scale federated learning tasks efficiently required optimizing communication protocols and computational loads, ensuring COALA can scale across various devices and networks. Our research underscores this with efficient remote communication protocol, noting that COALA aims "...to support the simulation or real-world deployment of FL at scale," which is essential for broad adoption and practical use.
Potential Applications Open Source Access
COALA’s potential applications are vast and varied, encompassing multiple industries. In enterprise settings, COALA can help break down data silos, enabling the combination of knowledge without sharing sensitive personal data. For instance, in the finance sector, federated learning can enhance fraud detection and risk management by training models on distributed financial data while maintaining client confidentiality. Also, COALA can power intelligent systems in smart retail environments and smart city infrastructures, using data from distributed sensors and cameras to improve services and security. Our research also highlights the platform's potential, stating, that we hope to "..[e]mpower collaboration among various business units within Sony by utilizing FL for various industrial applications across regions and even borders."
Advancing Federated Learning: Breakthroughs in Personalization, Efficiency, and Domain Adaptability
While COALA represents a monumental step forward, Sony AI has also made other significant breakthroughs in federated learning this year. At the International Conference on Learning Representations (ICLR) 2024 and Conference on Computer Vision and Pattern Recognition (CVPR) 2024, Sony AI presented groundbreaking research in FL, showcasing advancements that could reshape various sectors. Three pivotal papers—FedWon, FedP3, and FedMef—illustrate novel techniques to enhance FL's efficiency, personalization, and scalability. This section delves into each research piece, exploring their methodologies, real-world implications, challenges, and opportunities.
FedP3: Federated Personalized and Privacy-Friendly Network Pruning under Model Heterogeneity
Why This Research Matters
The FedP3 framework addresses the critical challenge of model heterogeneity in FL. Traditional FL methods often struggle with diverse client capabilities and data distributions, leading to inefficient training and poor model performance. FedP3 proposes a solution by introducing a dual-pruning approach that enhances both communication efficiency and personalization.
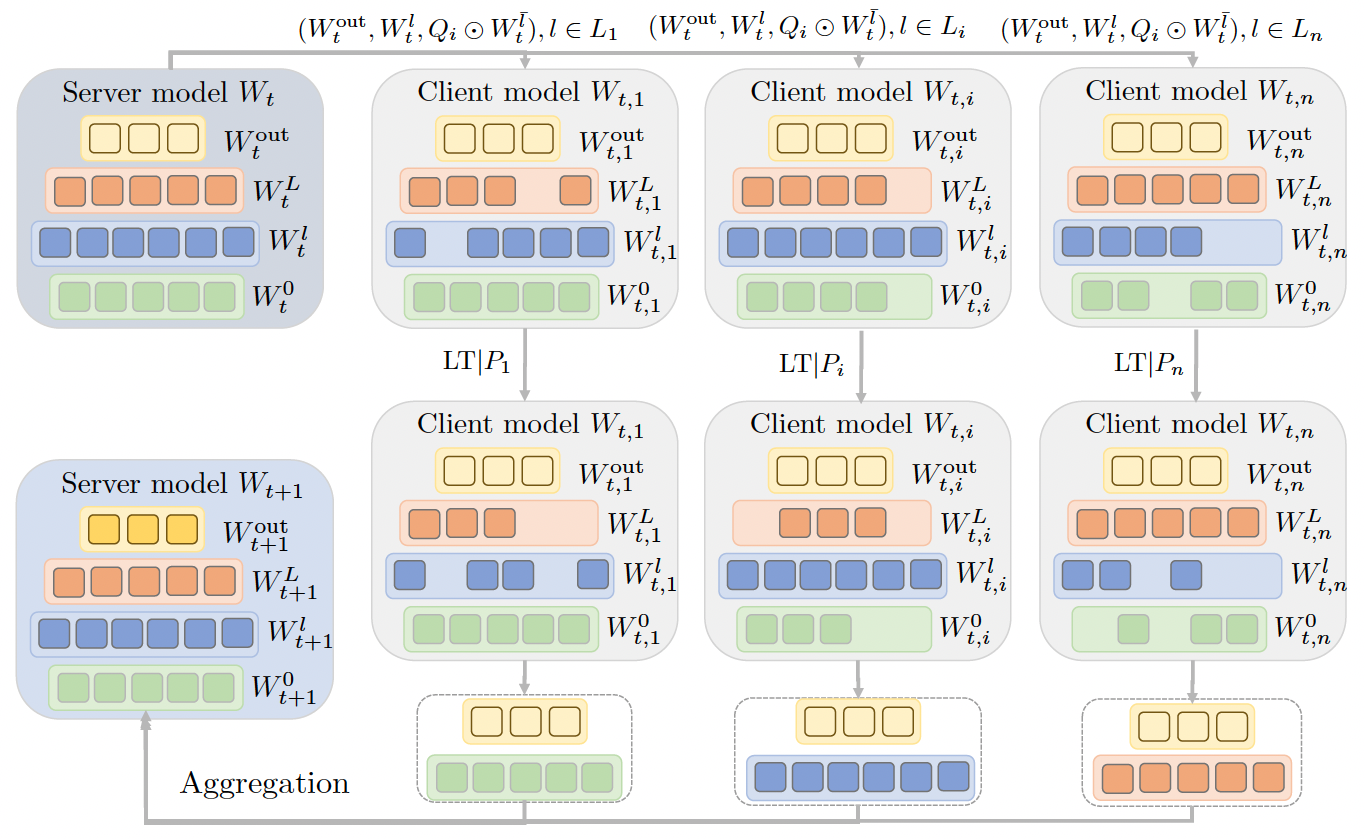
Figure 1: Pipeline illustration of our proposed framework FedP3.
Methodology and Approach
FedP3 employs a two-tier pruning strategy—global pruning from server to client and local pruning at the client level. This method optimizes the model size and complexity based on each client's computational capacity and network bandwidth. The global pruning step reduces the model's overall size before it is sent to the clients, while local pruning further refines the model based on local data and resources.
A key innovation in FedP3 is the integration of differential privacy mechanisms, ensuring that individual client data remains secure during the training process. The framework utilizes Gaussian perturbation to achieve local differential privacy, adding noise to the gradient updates to protect sensitive information.
Real-World Implications
FedP3's approach has significant implications for sectors where data privacy and resource constraints are paramount. In healthcare, for instance, personalized models can be trained on local hospital data without compromising patient confidentiality. Similarly, in mobile applications, FedP3 enables the deployment of personalized services that adapt to user preferences and device capabilities without extensive data transfers.
Challenges and Opportunities
While FedP3 offers substantial improvements in communication efficiency and privacy, it also faces challenges. The dual-pruning mechanism requires careful tuning to balance model accuracy and resource consumption. Additionally, ensuring consistent performance across highly heterogeneous client environments remains a complex task. Future research could explore adaptive pruning strategies and more robust privacy guarantees to enhance FedP3's applicability.
FedWon: Triumphing Multi-Domain Federated Learning Without Normalization
Why This Research Matters
FedWon introduces a novel approach to FL that eliminates the need for normalization layers, which are traditionally used to handle non-i.i.d data across clients. This is crucial for applications where data from different domains can significantly vary, such as autonomous driving and healthcare.
Methodology and Approach
The core innovation of FedWon lies in its reparameterization of convolutional layers using Scaled Weight Standardization. This technique allows the model to handle domain discrepancies among clients without relying on normalization, thereby simplifying the FL process and reducing computational overhead.
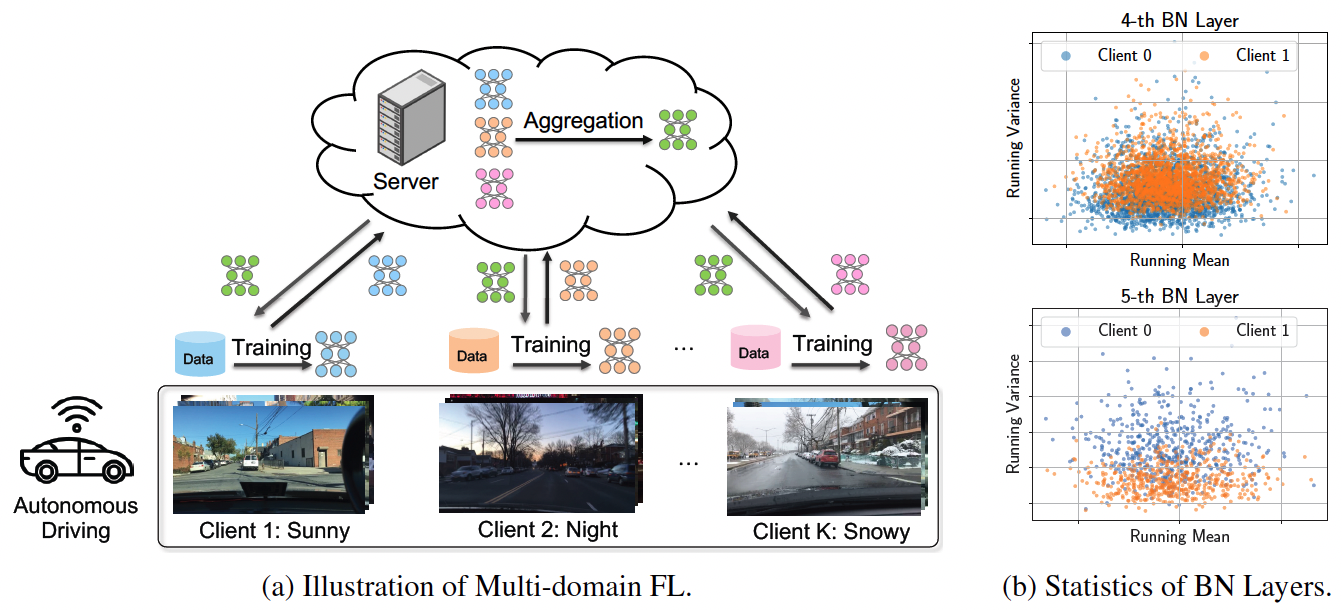
Figure 1: (a) We consider multi-domain federated learning, where each client contains data of one domain. This setting is highly practical and applicable in real-world scenarios. For example, autonomous cars in distinct locations capture images in varying weather conditions. (b) Visualization of batch normalization (BN) channel-wise statistics from two clients, each with data from a single domain. The upper and lower figures are results from the 4-th and 5-th BN layers of a 6-layer CNN, respectively. It highlights different feature statistics of BN layers trained on different domains.
By removing normalization layers, FedWon enhances the model's adaptability to varied data distributions, making it particularly suited for multi-domain scenarios. The method has been tested in environments with diverse data sources, demonstrating robust performance across different domains.
Real-World Implications
The implications of FedWonare far-reaching, particularly in fields requiring high reliability across different data environments. In autonomous driving, for instance, the ability to robustly perform across varied sensor data can significantly enhance vehicle safety and performance. In healthcare, FedWon can improve diagnostic models by effectively integrating data from different medical facilities and devices.
Challenges and Opportunities
FedWon’s normalization-free approach, while innovative, introduces challenges in maintaining model stability and accuracy. Ensuring that the reparameterized layers consistently outperform traditional methods requires further validation. Future research could focus on refining normalization-free techniques and exploring hybrid approaches that combine normalization and reparameterization for optimal performance.
FedMef: Towards Memory-Efficient Federated Learning
Why This Research Matters
FedMef addresses the critical issue of memory efficiency in FL, particularly relevant for devices with limited computational resources. This research aims to optimize memory usage without compromising model performance, facilitating the deployment of FL in resource-constrained environments.
Methodology and Approach
FedMef introduces a memory-efficient framework that leverages model pruning and quantization techniques. The framework dynamically adjusts the model's memory footprint based on the available resources, ensuring efficient training and inference processes. By combining these techniques, FedMef achieves significant memory savings while maintaining high model accuracy.
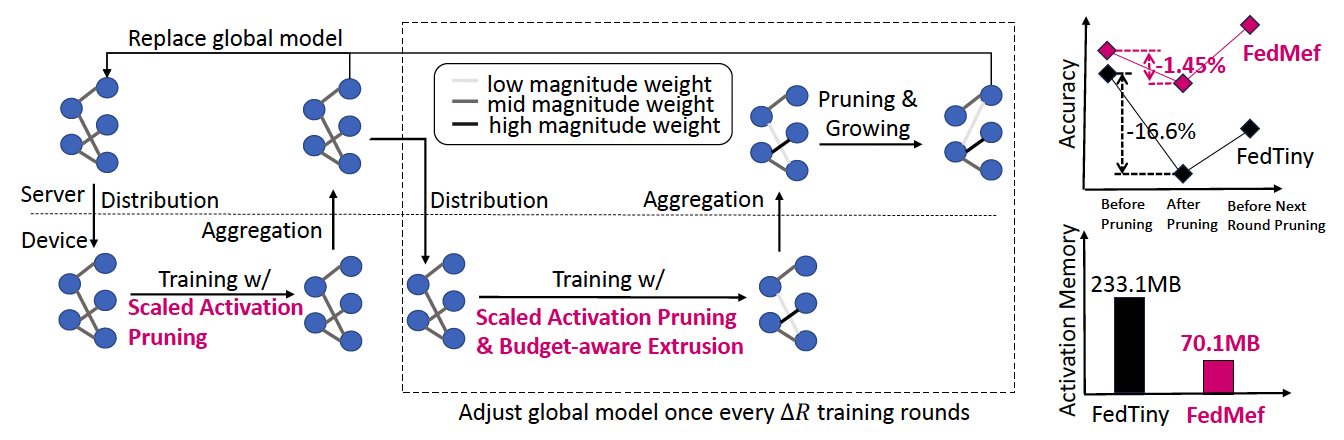
Figure 1: Left: Compared to baseline methods such as FedTiny (Huang et al., 2022), FedMef proposes budget-aware extrusion to preserve accuracy by transferring essential information from low-magnitude parameters to the others, and introduces scaled activation pruning to reduce memory usage. Top right: FedMef minimizes post-pruning accuracy loss and quickly recovers before the next round of pruning. Bottom right: FedMef significantly saves activation memory by more than 3 times through scaled activation pruning on the CIFAR-10 dataset with MobileNetV2.
The methodology includes iterative pruning of less significant model parameters and quantizing the remaining parameters to reduce their bit-width. This dual approach minimizes the memory requirements and computational load, making FL feasible on devices with limited resources such as smartphones and IoT devices.
Real-World Implications
FedMef’s advancements are particularly beneficial for expanding FL's reach to a broader range of devices and applications. In the context of mobile health applications, memory-efficient models can enable continuous monitoring and analysis without draining the device's battery or processing capabilities. Similarly, in smart home environments, FedMef can facilitate intelligent automation and monitoring without requiring high-end hardware.
Challenges and Opportunities
Implementing FedMef involves balancing the trade-offs between model accuracy and memory efficiency. Ensuring that the pruned and quantized models retain their performance across diverse tasks and data distributions is a significant challenge. Future directions could explore adaptive techniques that dynamically adjust the pruning and quantization levels based on real-time feedback and performance metrics.
Conclusion
COALA’s acceptance at ICML is a testament to the pioneering work of Lingjuan Lyu and her team. By addressing the challenges of federated learning in computer vision, COALA not only advances the field but also opens new avenues for privacy-preserving, efficient, and scalable AI applications. Alongside COALA, the breakthroughs presented in FedP3, FedWon, and FedMef demonstrate Sony AI’s commitment to pushing the boundaries of federated learning.
These advancements not only propose solutions to existing limitations but also open new avenues for future research, potentially leading to more adaptive, efficient, and personalized applications of FL across various domains. As the landscape of federated learning evolves, these studies will likely play a key role in shaping its future.
Follow us on Linkedin, Twitter, and Instagram for more details and news updates about our ongoing and up-and-coming research as well as event highlights.
Latest Blog

March 5, 2026 | Imaging & Sensing, Sony AI
On Writing The Principles of Diffusion Models, A Q&A With Sony AI Researcher, Je…
IntroductionDiffusion models have become a go-to approach for high-quality generation; however, the field can be challenging to navigate once the paper titles and acronyms begin to…

March 2, 2026 | Sony AI
Advancing AI: Highlights from February
February at Sony AI was defined by momentum across global stages, research publications, and conversations about how AI moves from theory into practice.This month spanned responsib…

February 2, 2026 | Sony AI
Advancing AI: Highlights from January
January set the tone for the year ahead at Sony AI, with work that spans foundational research, scientific discovery, and global engagement with the research community.This month’s…

