
Privacy-Preserving Machine Learning Blog Series
At Sony AI, the Privacy-Preserving Machine Learning (PPML) team focuses on fundamental and applied research in computer vision privacy. Their innovative research aims to apply these novel ideas to real-world AI applications. In this blog series, members of the PPLM team share their latest work.
Privacy Preservation in the Age of AI
Artificial intelligence (AI) systems are becoming increasingly prevalent in our daily lives. These systems, from Large Language Models, personalized recommendations, and computer vision-based recognition systems to personal assistants, are designed to make our lives easier and more efficient. However, as AI systems continue to evolve and become more sophisticated, there are growing concerns about privacy risks associated with their life cycle.
In this post, we will explore some of the most significant privacy risks in the life cycle of AI systems and discuss the approach the Sony AI Privacy-Preserving Machine Learning (PPML) team takes to protect sensitive information while leveraging the power of modern algorithms.
Privacy Risks at Each Stage of the AI Life Cycle and Regulations
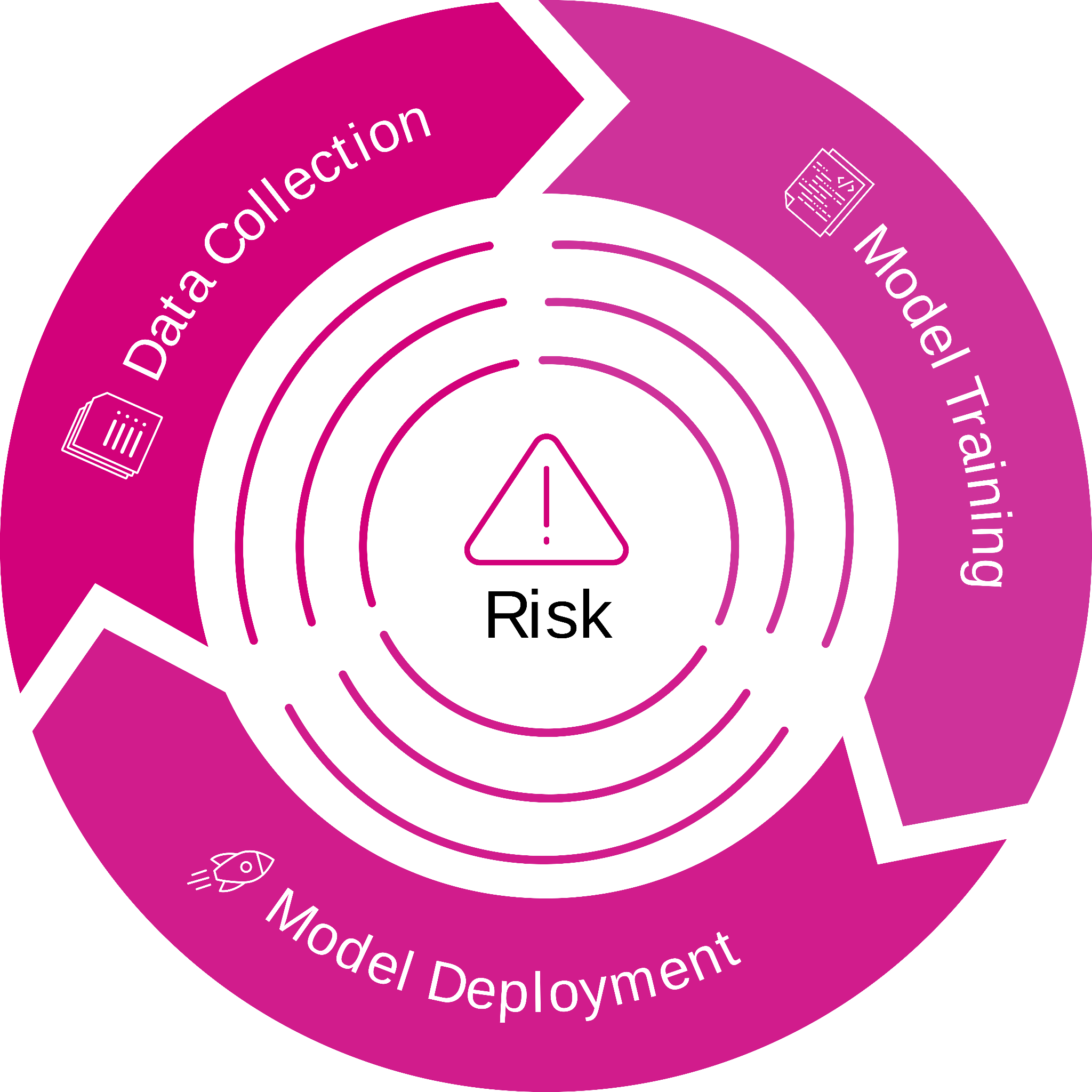
Figure 1: Risks within the life cycle of a Machine Learning (ML) model
Data Collection Risk
One of the most significant privacy risks associated with AI systems occurs during the data collection phase. Many AI systems rely on vast amounts of data to function properly, and this data often includes sensitive personal information such as biometric data, location data, and behavioral data. If data is intercepted during its collection or curation, it could be harmful to concerned individuals.
Let us consider a video surveillance CCTV system. If this CCTV system is not properly secured, it can leak sensitive data. For instance, if someone is recognized in an airport, near a particular subway station, a school, or a hospital, it could reveal sensitive information about their personal life. Ensuring that any data collected by AI systems is appropriately secured and protected is essential to mitigate this risk.
Model Training Risk
Another significant privacy risk associated with AI systems occurs at the model training step. AI models are known to learn features contained in the training data for the specific task they are designed for. Yet, due to the powerful learning capabilities of actual models, they might not restrict to capturing general features but also very specific and sensitive ones, even if they have been explicitly removed from the training data. This phenomenon is even more visible for larger models with billions of parameters.
Model Deployment Risk
After a model has been trained, it must be deployed for use. Unfortunately, there are significant privacy risks associated with model deployment as well. Recent research works showed that trained machine models can be vulnerable to a series of privacy attacks, such as membership inference attack (MIA), reconstruction attacks, etc.1 To mitigate such risks at deployment, it is essential to ensure that any deployed AI systems are initially trained securely and keep being protected from attacks.
Current Regulations
Due to growing concerns related to data privacy, increased attention has been paid to its protection and regulation. From a legal perspective, laws have been established from the state to the global level to provide mandatory regulations for data privacy.1 For instance, the California Consumer Privacy Act (CCPA) was signed into law in 2018 to enhance privacy rights and consumer protection in California by giving consumers more control over the personal information that businesses collect. Additionally, the Health Insurance Portability and Accountability Act (HIPAA) was created in 1996 to protect individual healthcare information by requiring authorization before disclosing personal healthcare information. In 2016, the European Union adopted the General Data Protection Regulation (GDPR) to protect data privacy by giving individuals control over their personal data collection and usage. It is important for public institutions and private companies to comply with current regulations and anticipate future ones related to AI systems.
Such regulations can have a profound impact on business practices. For example, GDPR requires that any images captured by cameras should not be kept in memory for more than a certain number of days. This helps ensure that any sensitive information that is captured is not retained for longer than necessary.2

Figure 2: Illustration of mentioned privacy laws
Approach to Privacy by Design
Overview of Privacy-Preserving Techniques
As explained above, private and sensitive information, especially personally identifiable information (PII), carried by data and models that could be potentially exposed throughout the AI system must be guaranteed. To this end, privacy-preserving techniques with strong guarantees are highly desired. The standard privacy-preserving practices in machine learning include anonymization (or pseudonymization), differential privacy, cryptography-based techniques, on-device AI and Federated Learning (FL). Yet, these techniques alone are meaningless without proper metrics that practitioners can rely on to measure the “amount” of privacy they guarantee.
Below is a summary of our work on anonymization and on-device AI that demonstrates its potential to enhance privacy and how we can achieve that goal.
Need for Privacy Assessments
It should be noted that different privacy-preserving techniques have varying degrees of effectiveness, and not all can resist the most advanced attacks. For instance, blurred faces can be easily recovered if the blurring ratio is small or if blurring parameters are known by the attacker. However, large blurring ratios will be harder to invert but will destroy data utility in the meantime. Similarly, FL alone cannot completely protect data privacy, as shared model parameters can still encode sensitive information. Therefore, conducting a rigorous and complete privacy assessment is crucial before choosing the right privacy-preserving techniques to balance privacy and utility. In our projects, we currently consider privacy assessments that include but are not limited to visual privacy, mathematical privacy guarantees, privacy resistances to different privacy attacks like MIA, model inversion attack, etc.
On-Device Privacy
The recent shift in how privacy is perceived and regulated globally has significant implications for vision systems implemented in public or semi-public settings, as well as in private areas, especially in light of high-profile data breaches involving online security cameras. Solutions involving on-device AI can address these risks. On smart cameras, the image data never leaves the device as it is: it is processed by an AI model to only output relevant metadata desired by the practitioner, or it gets anonymized (or pseudonymized) before leaving the camera. Our team believes that modern AI tools can be used to enhance the capacities of sensors and cameras in two ways: 1) by processing and analyzing images with computer vision models and 2) by redacting sensitive information from data to avoid privacy leakage. Smarter systems mean more efficient and privacy-aware systems.
In a smart city context, for example, one could use our future technology to automatically count the number of persons waiting at a bus stop to manage passenger traffic on the line or to spot free parking slots while redacting sensitive information such as people's faces, bodies, license plates or street names from images.
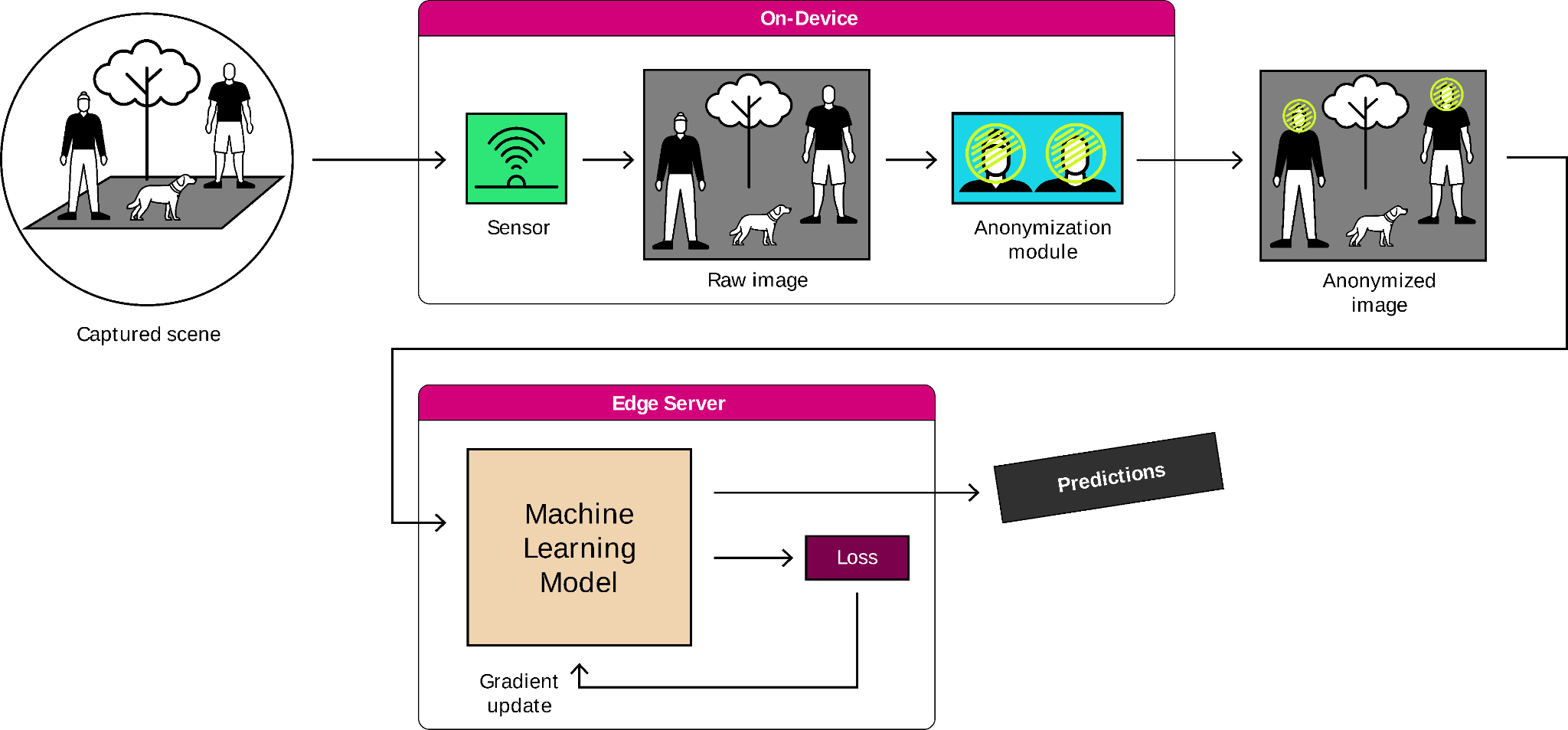
Figure 3: Illustration of the usage of on-device anonymization
Privacy Toolbox
Another tool we are developing is a Privacy Toolbox that can be used both on-device and on-cloud. It provides its users with privacy guarantees of their data and ML model at the different stages of an AI model's life cycle. To do so, practitioners can use the Privacy Toolbox to redact sensitive information from images to use the later anonymized data to train a provided model securely and test it to evaluate its performance and privacy guarantees.
Below is more detail on the elements of our toolbox.
1) The user can select the sensitive elements to remove, e.g., faces, bodies, license plates, text, and the anonymization technique to apply, e.g., masking, pixelating, blurring, and generation. After getting an anonymized version of the input dataset, the user can compute reconstructions or re-identification metrics to check the performance of the anonymization technique involved. Another important quantity provided is the quality assessment, using PSNR, SSIM or more modern metrics such as LPIPS, of the anonymized dataset and its utility by comparing the performance of pre-trained models on vanilla and anonymized versions of the data.
2) Then, anonymized data can be used to train a more private model. By using differentially-private training algorithms such as DP-SGD, the user ensures additional protection, for instance, against inversion or membership inference attacks.
3) Finally, the toolbox allows us to evaluate the performance of the secure model trained on anonymized data and its resistance to modern attacks, such as MIA, model inversion, gradient inversion, etc.
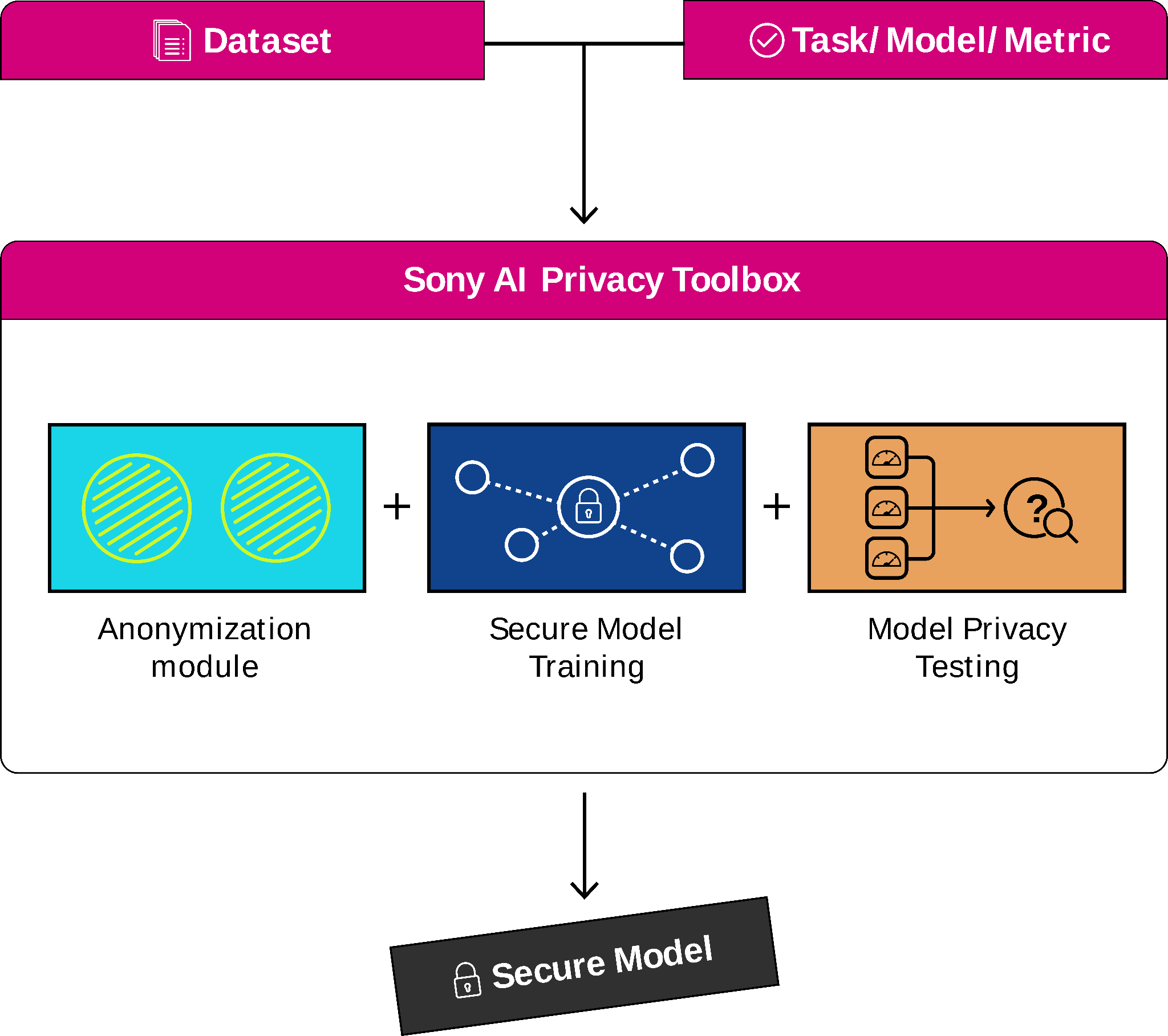
Figure 4: Overview of the Sony AI Privacy Toolbox
Conclusion
Protecting privacy in the age of AI is essential to maintaining trust between users and AI systems. Regulations such as CCPA, HIPAA, and GDPR highlight the importance of data privacy and encourage companies to comply with the regulations and anticipate future ones related to AI systems. Our PPML team at Sony AI is dedicated to developing and implementing effective privacy-preserving techniques, and with the right approach, we can achieve the goal of privacy by design. By prioritizing privacy in the development of AI systems, we can build trust with users and ensure that AI is used responsibly.
References:
Robustness, Security, Attacks
[1] [TNNLS’22] Privacy and Robustness in Federated Learning: Attacks and Defenses.
[2] Chapter 8, https://edpb.europa.eu/sites/default/files/consultation/edpb_guidelines_201903_videosurveillance.pdf


