



Recent Breakthroughs Tackle Challenges in Federated Learning


Machine Learning
June 8, 2023
Privacy-Preserving Machine Learning Blog Series
At Sony AI, the Privacy-Preserving Machine Learning (PPML) team focuses on fundamental and applied research in computer vision privacy and security. Their innovative research aims to apply these novel ideas to real-world AI applications. In this blog series, members of the PPLM team will share their latest work.
Why Federated Learning
Traditional machine learning training methods require centralizing a large amount of data from diverse sources to a single server. However, the growing concern over data privacy, particularly for applications that involve sensitive personal information (PI), is making this training paradigm a huge concern. Federated learning (FL) revolutionizes the traditional centralized training paradigm by enabling model training from decentralized data without any data sharing with the central server. In FL, multiple entities (clients) collaborate to conduct training, under the coordination of a server. As shown in Figure 1, the standard FL iterates four training steps until the stopping condition is met (e.g., convergence or high test accuracy): 1. The server sends a global model (initialized on the server in the 1st round) to the selected clients; 2. Clients conduct local training on their local data; 3. Clients upload the training updates of the model to the server; 4. The server aggregates the training updates to obtain a new global model.
In this first blog post in our series we will introduce some of the real scenarios where FL can have the biggest impact and share our extensive research across many of the current challenges with FL. The research has uncovered several solutions that address some of the barriers to entry in applying FL and new thinking on how to address issues such as heterogeneity and label deficiency.
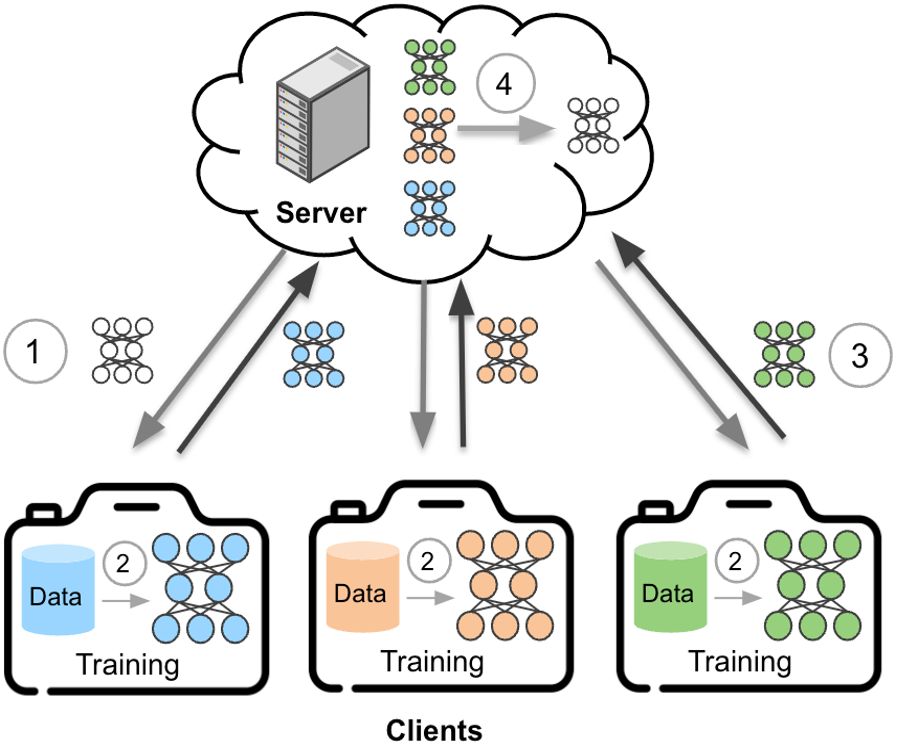
Figure 1. Federated learning training process
Real Scenarios Empowered by FL
FL can greatly benefit numerous application scenarios. For example, smart city applications can leverage FL to enhance the capabilities of edge vision sensors to address problems in big cities, such as traffic congestion and pedestrian safety. Unlike traditional methods that need to collect data to a central server to train deep neural networks for edge deployment, FL can reduce the cost of data collection and improve the life-cycle of machine learning models. This is achieved by collecting new data locally only for training and upgrading models, especially in dynamic environments that undergo continuous changes such as weather conditions and seasonal fluctuations. Specifically, a central server can coordinate multiple vision sensors to update models collaboratively through the federated learning process, by considering an edge vision sensor as an FL client. It enhances data privacy as raw image data is always kept locally on edge devices, without being uploaded to the server.
In addition to smart city applications, FL has the potential to benefit many other use cases like smart retail, smart manufacturing, healthcare, and the financial industry. It also can stimulate and empower collaboration across sectors. For example, vertical FL supports collaborative model building across organizations, where each organization owns part of the data. Additional privacy-preserving techniques (e.g., cryptographic techniques, differential privacy) can be added to further protect sensitive data. We believe that FL can unleash the potential of many business use cases.
Recent Research Aims to Overcome Challenges
FL can empower many real-world applications, and many companies are actively investigating how to integrate it into their technology stack to protect data privacy. Over previous years, our team has developed extensive experience in FL research and application development. We have published numerous papers in top-tier AI conferences (e.g., NeurIPS, ICLR, ICML, etc.) and journals (e.g., Nature Communications). The following are the challenges we are addressing, and opportunities we believe are the most crucial.
1. Communication Efficiency and Heterogeneity. Statistical and system heterogeneity are the most common challenges in FL. Statistical heterogeneity means that the data on FL clients are non-independent and identically distributed (non-i.i.d), e.g., edge vision sensors in different locations collect data with different distributions. These edge sensors could be attached to other edge devices with different computation and networking capabilities, which results in system heterogeneity. Additionally, FL needs multiple rounds of communication between the server and clients during the training process. Thus, improving the communication efficiency enhances the efficiency of the overall system. We have proposed two new methods to address statistical heterogeneity: calibrated federated adversarial training, and a new server aggregation strategy termed Federated Skip Aggregation. We also proposed a new framework that is inclusive for heterogeneous devices with different computation capabilities. Besides, we leveraged knowledge distillation for communication-efficient FL and elevated the communication efficiency by allowing FL with only one round of communication.
2. Label Deficiency. The majority of FL studies assume that there are data labels in clients. However, many real-world raw data do not come with labels when collected. For instance, images generated by cameras naturally do not have labels, and it is impractical to label all images generated by cameras in the first place. We proposed novel methods to enable federated self-supervised learning across decentralized clients without relying on any data labels. This method learns general visual representations that are beneficial for various downstream computer vision applications. We also studied federated unsupervised learning for a privacy-sensitive application: person re-identification. This technology has versatile applications, such as analyzing customer trajectories in smart retail settings and implementing security surveillance measures in smart cities. Further study can be conducted on federated semi-supervised learning to leverage available labeled data on the FL server or a small amount of labeled data on FL clients.
3. Security and Robustness. FL protects data privacy by transferring training updates (e.g., gradient or model parameters) instead of raw data. We have a comprehensive study on privacy and robustness in FL, including different attack and defense approaches. We further dove into the scenarios where the server or client could be malicious. A reconstruction attack assumes a malicious server tries to reconstruct information from clients, i.e., breaking clients' data privacy. Byzantine attack assumes that a fraction of malicious clients try to poison or bias the model learning process and lead to bias or bad performances. We have studied both reconstruction attack and Byzantine attack, and their corresponding defenses in FL. Besides, FL systems are vulnerable to adversarial attacks in real-world applications; thus, we further improved the robustness of FL with adversarial training techniques.
4. Federated Learning Platform and Operations. MLOps is a standard practice for managing and operating machine learning models in production. FL also needs a systematic platform to support the management and operation of FL processes. One of our team members has previously developed an easy-to-use FL platform, EasyFL. There are also numerous FL platforms, such as FedML and Flower. It is also important to develop FL platforms that contain a suite of FL algorithms for different application scenarios and MLOps functionalities to support real-world applications.
5. Federated Learning Applications. Most FL studies are based on relatively simple applications, such as image classification or next-world prediction. Real-world applications are far more complex and would require application-specific optimizations. We have experience in performance optimization for various privacy-sensitive computer vision applications, including person re-identification and face recognition. In the finance domain, graph neural networks have been used for credit rating and risk management, fraud detection, and money laundering detection. We have conducted an in-depth study on optimizing and providing privacy-preserving federated graph neural networks on horizontal FL (across edge devices) and vertical FL (across organizations). Real-world deployment requires specific optimizations for specific FL applications. We will continue conducting related research and bring high-impact outcomes to benefit Sony businesses and the research community.
Conclusion
Although federated learning is still in its infancy, it will continue to thrive and be an active and important area in the foreseeable future. As we move forward with our research in this area, we anticipate facing further challenges and opportunities, which we will explore in upcoming blog posts. We aim to push the boundaries of FL algorithms and systems, leveraging them to tackle practical business issues and delivering valuable outcomes to “unleash human imagination and creativity with AI.”
Latest Blog

July 8, 2025 | Sony AI
Sights on AI: Lingjuan Lyu Discusses Her Career in Privacy-Preserving AI and Sta…
The Sony AI team is a diverse group of individuals working to accomplish one common goal: accelerate the fundamental research and development of AI and enhance human imagination an…

July 7, 2025 | Scientific Discovery, Events
Scientific Discovery: How Sony AI Is Building Tools to Empower Scientists and Pe…
At this year’s AI4X 2025, Sony AI is presenting two research projects that show how intelligent systems can augment knowledge and creativity in complex scientific research. These t…

July 1, 2025 | Sony AI
Advancing AI: Highlights from June
June was a month of real-world progress across Sony AI. We brought new models to IJCNN, revisited SXSW’s human-robot creativity panel, celebrated Peter Stone’s AAAI webinar appeara…

