




Unlocking the Future of Video-to-Audio Synthesis: Inside the MMAudio Model
Sony AI
March 18, 2025
In a world increasingly driven by multimedia content, AI researchers have long struggled to generate high-quality, synchronized audio from video. Recently, audio generation models such as text-to-audio and video-to-audio have made significant strides.
We can think of AI audio models like a musician learning new songs. Up until now, these models can create sounds in two main ways: either by reading descriptions (like sheet music) or by watching videos (like watching another musician play). For example, you could type "waves crashing on the beach" and an AI model would create that sound, or show it a video of waves and it would add the matching ocean sounds.
But to learn effectively, AI models need a lot of examples where the sound, text description, and video all match perfectly. Unfortunately, there have always been limitations in making these perfect matches. Current state-of-the-art video-to-audio methods either train only on audio-visual data from scratch or train new “control modules” for pretrained text-to-audio models on audio-visual data. Text-audio pairs had not been considered for this task. The team discovered that a video-to-audio model trained with video-audio pairs was significantly improved by exploiting text-audio pairs usually only used to train text-to-audio models.
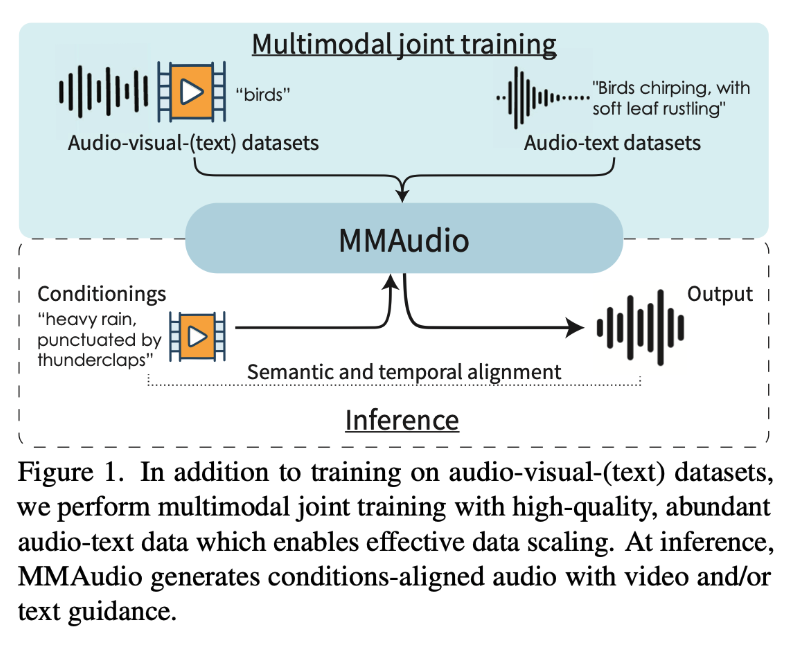
Use of multiple types of paired data such as using text and video simultaneously for training a single audio generation model was a largely untapped frontier, until now.
Enter MMAudio, An advanced video-to-audio synthesis model designed to convert visual content into immersive, contextually accurate audio. This model excels at producing high-quality sound that aligns seamlessly with the visual components, actions, and settings of source videos, all while preserving temporal coherence. The model utilizes a cutting-edge deep learning framework tailored for video-to-audio synthesis. By leveraging advanced neural networks and temporal processing, it analyzes visual data to create audio that seamlessly aligns with the content.
The training framework the Sony AI team created provides a new method for the alignment of text, images, audio, and video to correspond to the same content so that it accurately represents the same idea or information across different modalities. For example, we find that a model that takes as input both the words "splashing raindrops" and a video of such a scene is able to generate more accurate sounds than when given just one of those inputs. In addition there needs to be temporal alignment. Humans can perceive audio-visual misalignment as slight as 25 milliseconds therefore the relationship between different types of data needs to be preserved in real-time. MMAudio significantly improves audio quality and enables more precise audio-visual synchrony, already achieving new state-of-the-art performance in video-to-audio synthesis among public models.
This research was developed by the Sony AI team with a growing portfolio of breakthroughs in the areas of sound and audio. Distinguished engineer Yuki Mitsufuji, led the team that included Ho Kei Cheng, an intern and PhD candidate at the University of Illinois, along with Masato Ishii, Akio Hayakawa, Takashi Shibuya, Alexander Schwing. The paper has been accepted at CVPR 2025, the prestigious computer vision conference occurring in June, underscoring the significance of this work. Examples of the work can be found on the team’s website for the project.
Why MMAudio Matters
The significance of the MMAudio model lies in its ability to address two critical aspects of video-to-audio synthesis: semantic alignment and temporal synchronization. Traditional methods have relied solely on video-conditioned models or fine-tuned text-to-audio models, both of which suffer from inherent limitations.
"Current state-of-the-art video-to-audio methods either train only on audio-visual data from scratch or train new 'control modules' for pretrained text-to-audio models on audio-visual data," the researchers note, "...the former is limited by the amount of available training data... The latter complicates the network architecture and limits the design space."
MMAudio circumvents these issues by adopting a multimodal joint training approach, which allows the model to be trained on large-scale text-audio datasets, enhancing both audio quality and alignment.
"Jointly training on large multimodal datasets enables a unified semantic space and exposes the model to more data for learning the distribution of natural audio," they explain.
This approach ensures that the generated audio is not only high quality but also deeply integrated with the video’s contextual elements.
The Challenges of Multimodal Joint Training
Developing a high-performing multimodal training model is no easy feat. The research team encountered significant hurdles in ensuring accurate temporal synchronization and maximizing training efficiency.
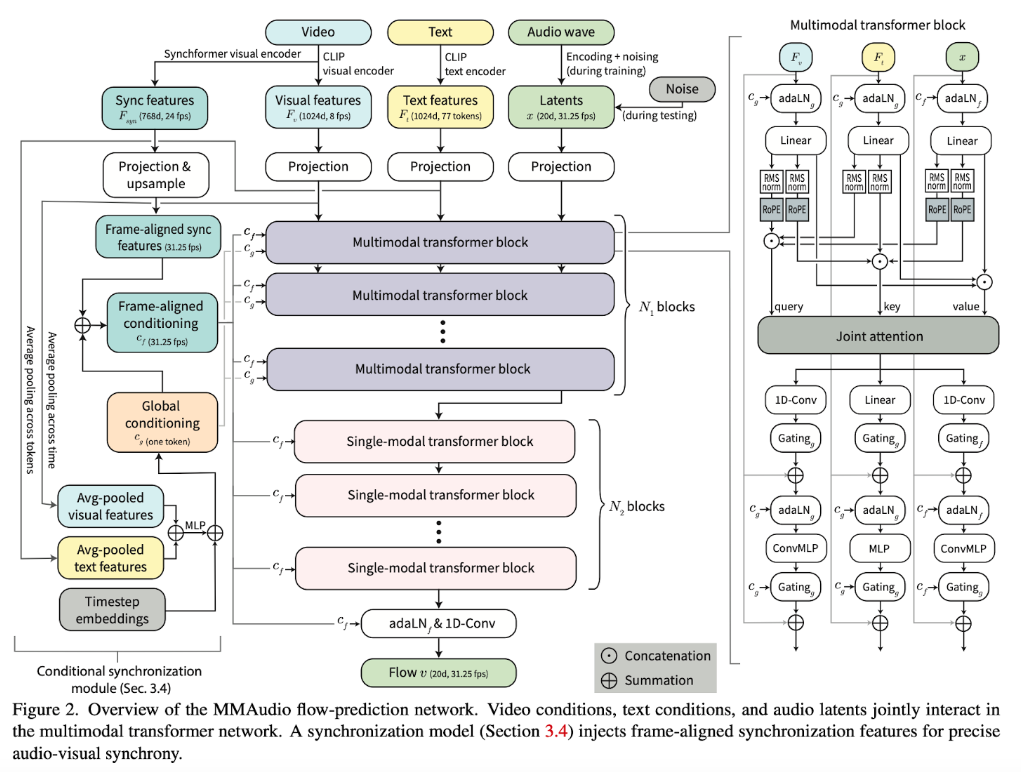
One of the key challenges was that, "...using attention layers only is ineffective at indicating precise timings in audio/visual signals."
This presented a major obstacle because human perception can detect audio-visual misalignment as small as 25 milliseconds. To address this, the team introduced a conditional synchronization module, which aligns video features with audio latents at the frame level.
"We introduce a conditional synchronization module that uses high frame-rate visual features (extracted from a self-supervised audio-visual desynchronization detector) and operates in the space of scales and biases of adaptive layer normalization (adaLN) layers, leading to accurate frame-level synchronization," they explain.
Another challenge was balancing the use of large datasets while maintaining low inference time and manageable model size.
"Trained with a flow matching objective, MMAudio achieves new video-to-audio state-of-the-art among public models in terms of audio quality, semantic alignment, and audio-visual synchronization, while having a low inference time (1.23s to generate an 8s clip) and just 157M parameters," the paper states.
This efficiency ensures the model can be deployed at scale without significant computational overhead.
Breaking New Ground: Key Results
The results of the MMAudio model demonstrate a significant leap forward in video-to-audio generation. Compared to previous models, MMAudio excels in distribution matching, audio quality, semantic alignment, and temporal alignment.
The study highlights that "...empirically, with joint training, we observe a significant relative improvement in audio quality (10% lower Fréchet Distance and 15% higher Inception Score), semantic alignment (4% higher ImageBind score), and temporal alignment (14% better synchronization score)."
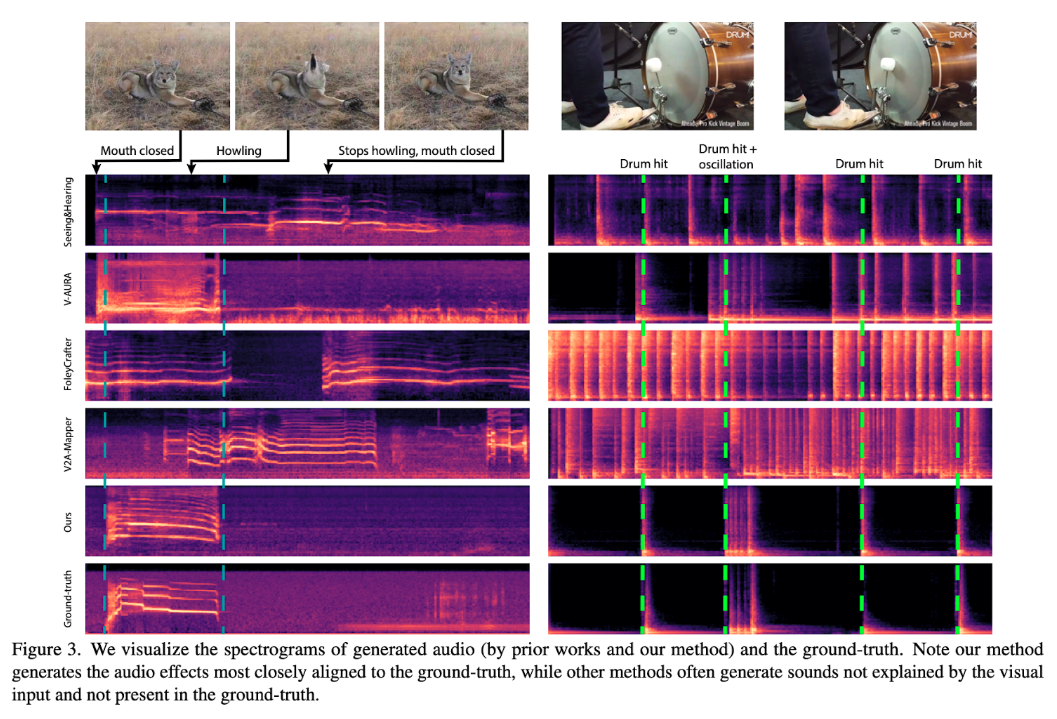
These improvements are particularly striking given the relatively compact size of the model. The MMAudio-S (smallest version) with just 157M parameters outperforms existing larger models that require over 600M parameters.
Furthermore, the research reveals an unexpected benefit: "Surprisingly, our multimodal approach also achieves competitive performance in text-to-audio generation compared to dedicated text-to-audio methods, showing that joint training does not hinder single-modality performance," the authors state.
This suggests that the underlying architecture could be adapted to a range of multimodal AI applications beyond its initial scope.
The Future of Multimodal AI
The introduction of MMAudio represents a step toward more sophisticated AI-generated multimedia experiences. Its ability to seamlessly blend text, video, and audio inputs in a unified training framework opens the door for future advancements in AI-driven content generation accessibility tools, and immersive digital experiences.
"We believe a multimodal formulation is key for the synthesis of data in any modality, and MMAudio lays the foundation in the audio-video-text space," the researchers conclude.
Like much of Sony AI's research, the code for MMAudio has been released under an MIT license, allowing the community to freely use, adapt, and improve upon the technology. This open-source approach underscores Sony AI's commitment to fostering innovation and making cutting-edge tools accessible to all. Demos of the solution are also available at the link above.
As AI-generated content continues to evolve, models like MMAudio will play a crucial role in bridging the gap between different sensory modalities, making digital experiences more natural and immersive than ever before.
Further Reading: Dive into more novel work from this diligent team
- Breaking New Ground in AI Image Generation Research: GenWarp and PaGoDA at NeurIPS 2024 – Sony AI
- Sights on AI: Yuki Mitsufuji Shares Inspiration for AI Research into Music and Sound
- Revolutionizing Creativity with CTM and SAN: Sony AI's Groundbreaking Advances in Generative AI for Creators
- Enhancing Semantic Communication with Deep Generative Models -- An ICASSP Special Session Overview – Sony AI
Latest Blog

March 5, 2026 | Imaging & Sensing, Sony AI
On Writing The Principles of Diffusion Models, A Q&A With Sony AI Researcher, Je…
IntroductionDiffusion models have become a go-to approach for high-quality generation; however, the field can be challenging to navigate once the paper titles and acronyms begin to…

March 2, 2026 | Sony AI
Advancing AI: Highlights from February
February at Sony AI was defined by momentum across global stages, research publications, and conversations about how AI moves from theory into practice.This month spanned responsib…

February 2, 2026 | Sony AI
Advancing AI: Highlights from January
January set the tone for the year ahead at Sony AI, with work that spans foundational research, scientific discovery, and global engagement with the research community.This month’s…

