Authors
- Miguel Vasco*
- Takuma Seno
- Kenta Kawamoto
- Kaushik Subramanian
- Pete Wurman
- Peter Stone
* External authors
Date
- 2024
Share



A Super-human Vision-based Reinforcement Learning Agent for Autonomous Racing in Gran Turismo
Miguel Vasco*
Takuma Seno
* External authors
2024






Reinforcement Learning Conference (RLC), 2024
*Equal Contribution, †Work done during his
internship at Tokyo Laboratory, Sony AI.
We contribute the first vision-based super-human car racing agent, able to outperform the best human drivers in time-trial races in Gran Turismo™ 7.
Abstract
Racing autonomous cars faster than the best human drivers has been a longstanding grand challenge for the fields of Artificial Intelligence and robotics. Recently, an end-to-end deep reinforcement learning agent met this challenge in a high-fidelity racing simulator, Gran Turismo. However, this agent relied on global features that require instrumentation external to the car. This paper introduces, to the best of our knowledge, the first super-human car racing agent whose sensor input is purely local to the car, namely pixels from an ego-centric camera view and quantities that can be sensed from on-board the car, such as the car's velocity. By leveraging global features only at training time, the learned agent is able to outperform the best human drivers in time trial (one car on the track at a time) races using only local input features. The resulting agent is evaluated in Gran Turismo 7 on multiple tracks and cars. Detailed ablation experiments demonstrate the agent's strong reliance on visual inputs, making it the first vision-based super-human car racing agent.
Designing a Super-Human Vision Racing Agent
Observations
We build multimodal observations of our racing agent with local and global features. For local features, we consider the image and propriocentric information (e.g., velocity and acceleration of the car). For global features we consider information related to the shape to the course.
Image
\(\mathbf{o}_t^I \in \mathbb{R}^{64 \times 64 \times 3}\)
Propriocentric
\(\mathbf{o}_t^g \in \mathbb{R}^{17}\)
Course Shape
\(\mathbf{o}_t^g \in \mathbb{R}^{531}\)
Actions
Our agent outputs a delta steering angle and a combined throttle and brake value. The gear shift of the vehicle is controlled by automatic transmission. We set the control frequency to 10 Hz and the game, running at 60 Hz, linearly interpolates the steering angle between steps.
Delta Steering Angle
\(\mathbf{a}_t^0 \in [-3^\circ, 3^\circ]\)
Throttle and Brake
\(\mathbf{a}_t^1 \in [-1, 1]\)
Reward Function
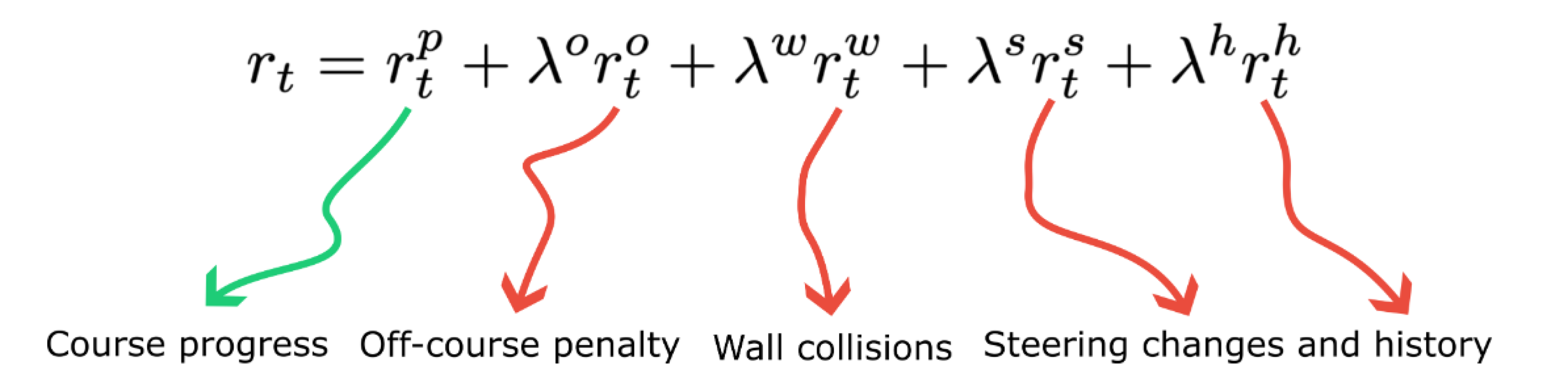
We designed a multi-component reward function for the agent that rewards track progression and penalizes collisions, off-track driving, and inconsistent driving.
Training Scheme
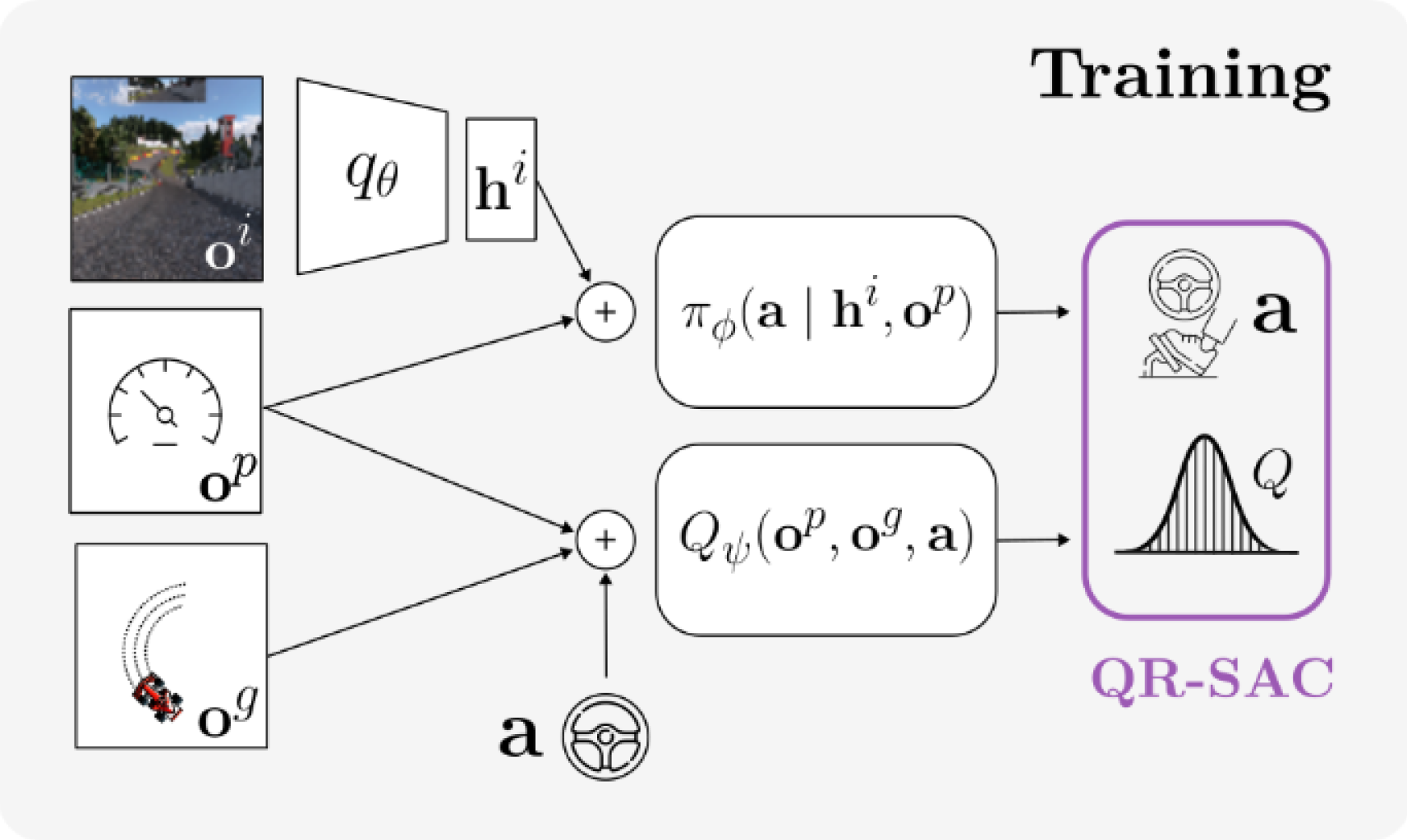
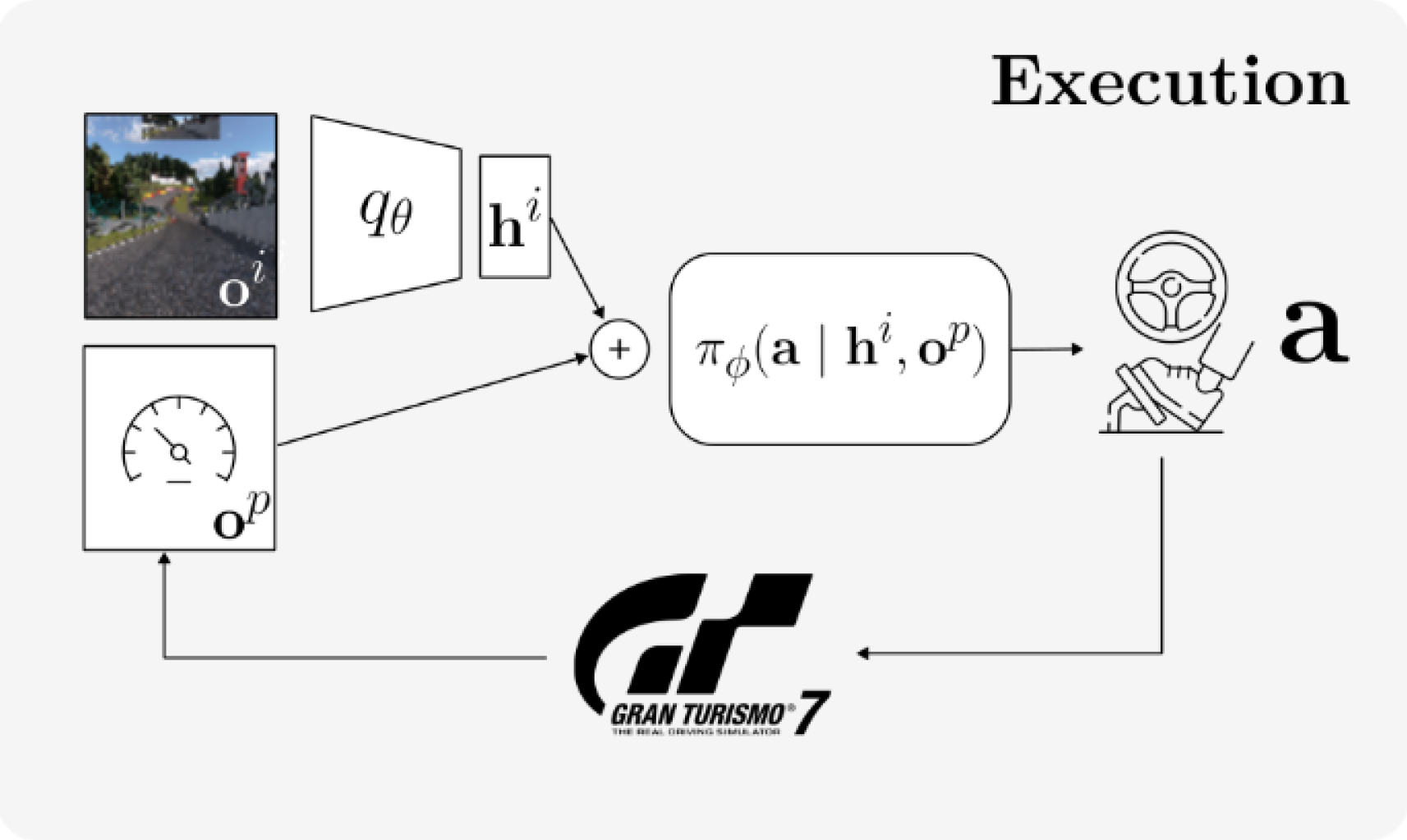
We exploit an asymmetric actor-critic architecture, in which the critic function uses different input modalities from those for the policy function, to train our agent: the policy network \(\pi_{\phi}\) is provided with proprioceptic information \(o^p\) and image features \(h^I\), encoded with a convolutional neural network \(q_{\theta}\), to output actions \(\mathbf{a}\). The critic network \(Q_{\psi}\) is provided with local proprioceptic observations and global observations \(o^g\) to predict quantiles of future returns. During execution, our agent only receives local features from the Gran Turismo™ 7 simulator.
Results
We evaluate our agent in time trial races, where the goal is to complete a lap across the track in the minimum time possible. We consider three scenarios in Gran Turismo™ 7 with different combinations of cars, tracks, and conditions (track time and weather): Monza, Tokyo, and Spa, modeled after real-world circuits and roads.

We compare our agent against over 130K human drivers in each scenario. In all three scenarios, our agent achieves super-human performance, with lap times that significantly surpass the performance of the best human player.
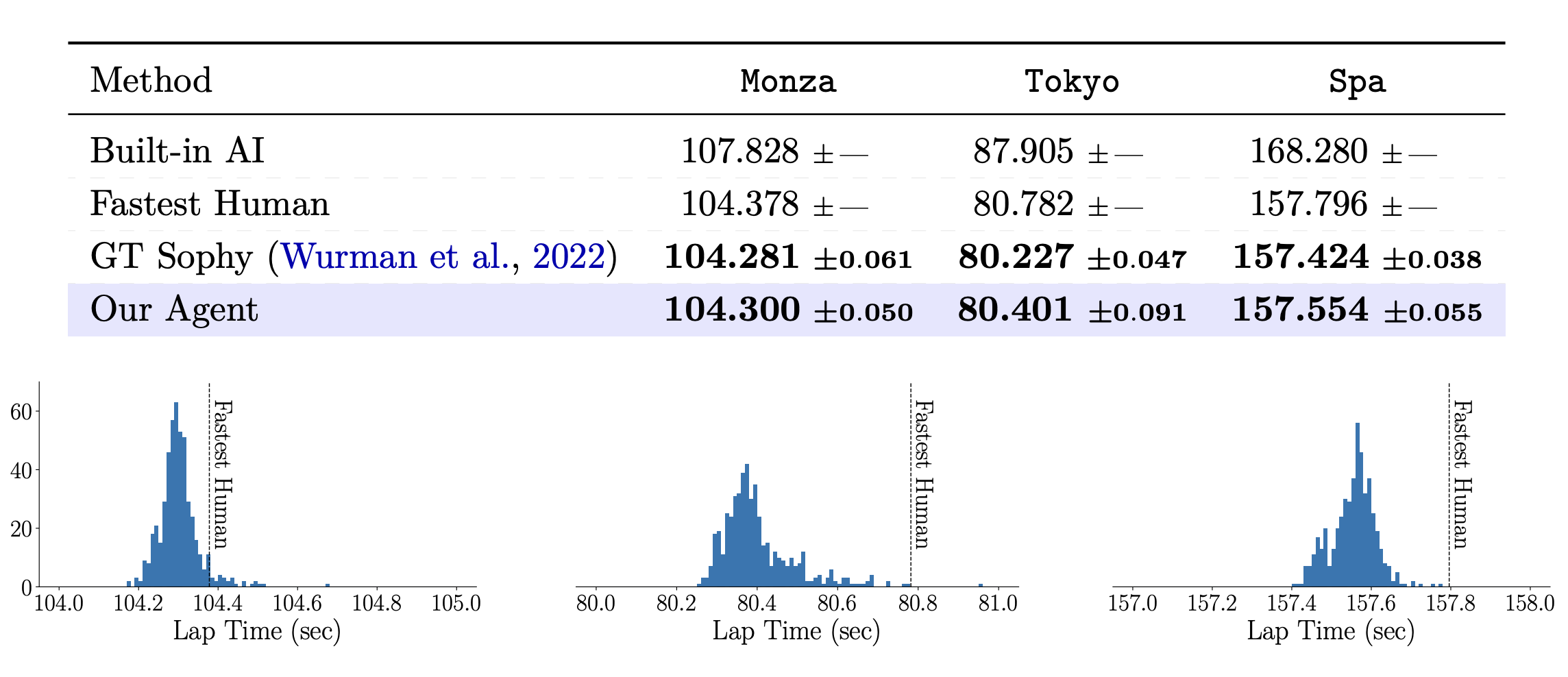
In the paper we additionally highlight: (i) the importance of the asymmetrical training scheme; (ii) novel driving behavior in comparison with the best human reference drivers, and (iii) the strong dependence on image features for the decision-making of our agent.
BibTeX
@InProceedings{RLC24-sophy,
author="Miguel Vasco and Takuma Seno and Kenta Kawamoto and Kaushik Subramanian and PeterR.\ Wurman and Peter Stone",
title="A Super-human Vision-based Reinforcement Learning Agent for Autonomous Racing in {G}ran {T}urismo",
booktitle="Reinforcement Learning Conference (RLC)",
month="August",
year="2024",
location="Amherst, MA, USA",
abstract={Racing autonomous cars faster than the best human drivers
has been a longstanding grand challenge for the fields of
Artificial Intelligence and robotics. Recently, an
end-to-end deep reinforcement learning agent met this
challenge in a high-fidelity racing simulator, Gran
Turismo. However, this agent relied on global features
that require instrumentation external to the car. This
paper introduces, to the best of our knowledge, the first
super-human car racing agent whose sensor input is purely
local to the car, namely pixels from an ego-centric camera
view and quantities that can be sensed from on-board the
car, such as the car's velocity. By leveraging global
features only at training time, the learned agent is able
to outperform the best human drivers in time trial (one
car on the track at a time) races using only local input
features. The resulting agent is evaluated in Gran Turismo
7 on multiple tracks and cars. Detailed ablation
experiments demonstrate the agent's strong reliance on
visual inputs, making it the first vision-based
super-human car racing agent.}
},
Related Publications
The purpose of continual reinforcement learning is to train an agent on a sequence of tasks such that it learns the ones that appear later in the sequence while retaining theability to perform the tasks that appeared earlier. Experience replay is a popular method used to mak…
When designing reinforcement learning (RL) agents, a designer communicates the desired agent behavior through the definition of reward functions - numerical feedback given to the agent as reward or punishment for its actions. However, mapping desired behaviors to reward func…
Having explored an environment, intelligent agents should be able to transfer their knowledge to most downstream tasks within that environment. Referred to as ``zero-shot learning," this ability remains elusive for general-purpose reinforcement learning algorithms. While rec…
JOIN US
Shape the Future of AI with Sony AI
We want to hear from those of you who have a strong desire
to shape the future of AI.

