
Each of us carries a core set of experiences, events that stand out as particularly important and have shaped our lives more than an average day. However, this is often not the case for AI agents using deep reinforcement learning (RL) and artificial networks. These systems typically employ Experience Replay (ER), a vital element that stores previous experiences in an Experience Replay Buffer (ERB) and re-samples them in mini-batches to train the agent's networks. However, current ERB and sampling techniques lack the ability to recall and emphasize more “significant” past events, often resulting in slow convergence and unstable asymptotic behaviors.
The lack of focus on core experiences is not just a theoretical issue. For example, consider the challenge when Sony AI trained GT Sophy, the superhuman racing agent used in the PlayStation® Gran Turismo™ franchise. GT Sophy typically goes through thousands of steps to complete a lap, with crucial events such as passing another car or navigating a difficult turn, occurring in just a few of those steps. Random sampling from an ERB filled with lap data is unlikely to emphasize the importance of these critical events.
To address the limitations of existing ER methods, in Kompella et al. 2022 we introduced the use of Event Tables (ETs) to supplement the standard replay buffer. ETs, as shown in Figure 1 below, are partitions within the ERB dedicated to storing sub-trajectories leading to significant events. The tables not only store the important events that we want to emphasize, but also a truncated history of experience that led up to that event. By stitching the sub-trajectories together, the agent will have a “fast lane” for shaping behavior between events and the initial state.
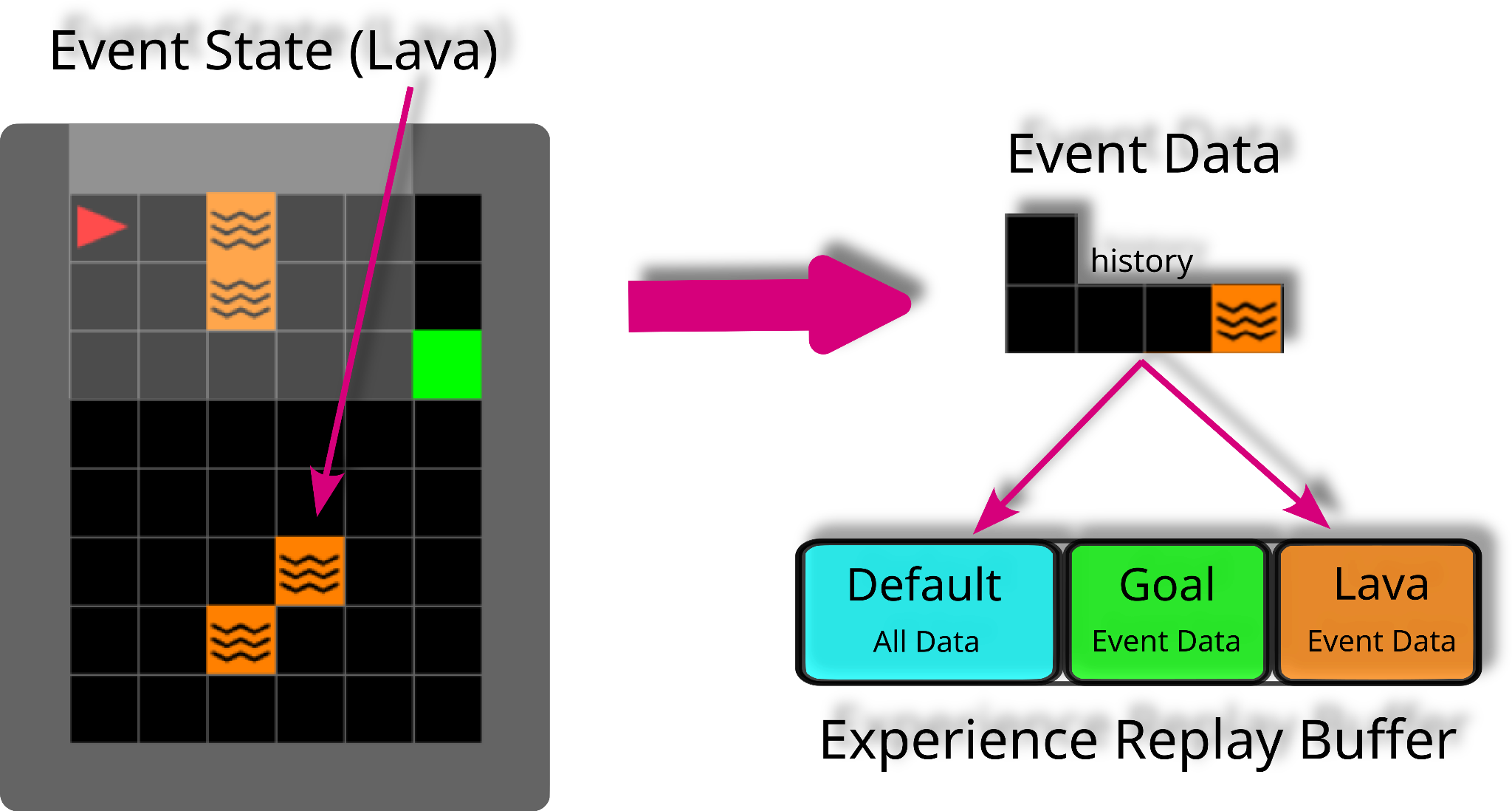
Figure 1 :Example usage of Event Tables in an environment with an agent (red triangle), goal (green square) and lava (orange squares). The buffer is partitioned into a default table and two smaller tables for keeping sub-trajectories that reached the goal or stepped in lava, respectively.
We also introduce a corresponding algorithm, Stratified Sampling from Event Tables (SSET), which guarantees the data used to train the RL agent contains significant samples from these tables. By independently sampling (i.i.d.) individual steps from each table and a default table that stores all-transitions, SSET ensures that the data associated with different events is consistent across samples.
Algorithm Illustration
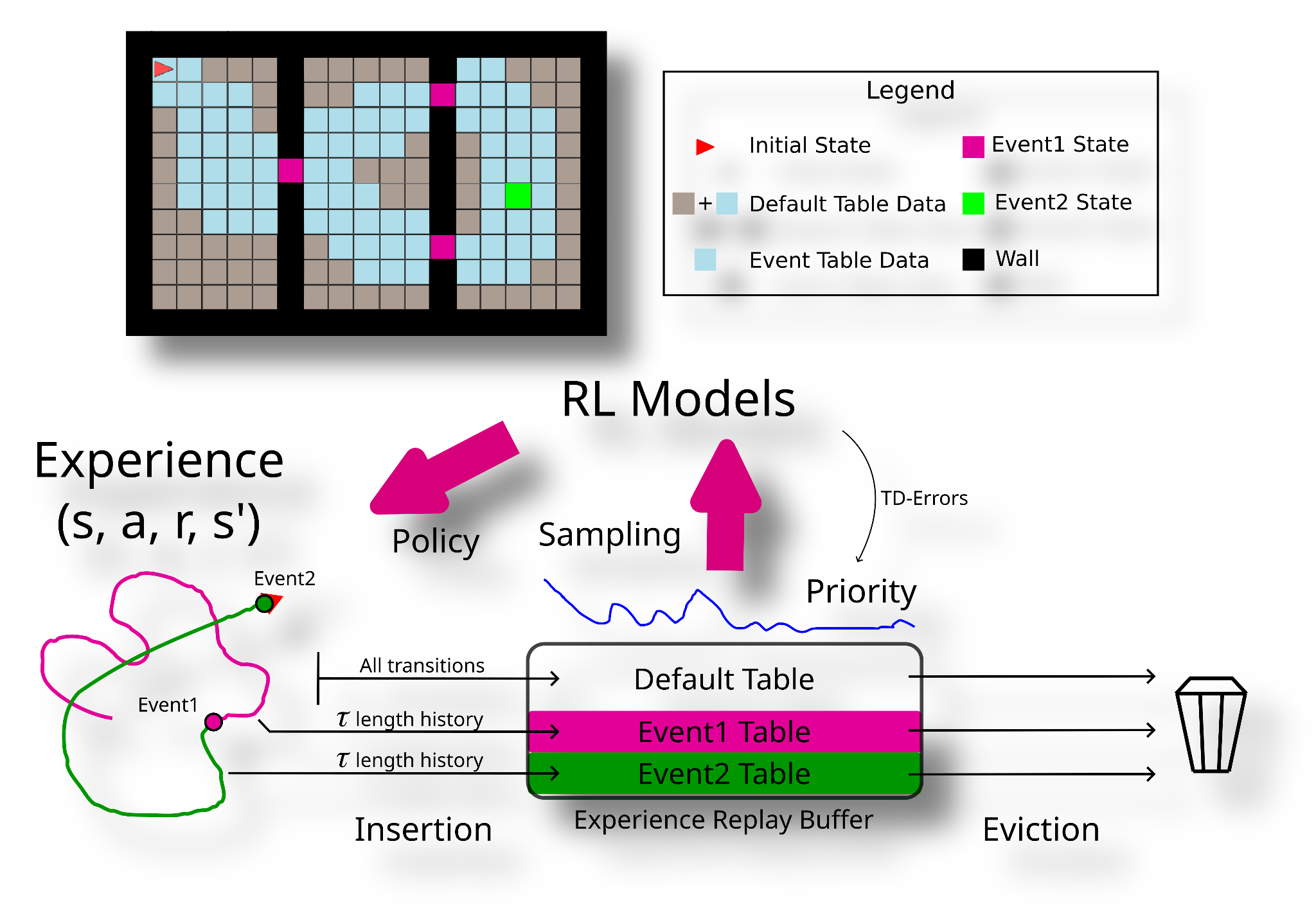
Figure 2 : Stratified Sampling using Event Tables (SSET)
In Figure 2, our SSET algorithm's operation is outlined. In a task where the agent aims to reach a green square, there are two event conditions: one for reaching the goal and one for encountering a gap in the walls. All agent experiences are stored in the default table. When either event occurs, recent transitions from the event's trajectory, determined by a history length parameter (𝝉), are stored in the corresponding event table. During each training step, we sample mini-batches from the three tables. We also give the option to set sampling priorities for customizing data drawn from the default table.
ETs and SSET have several desirable properties in a wide range of RL domains, which are described in the following sections.
Makes Use of Domain Knowledge
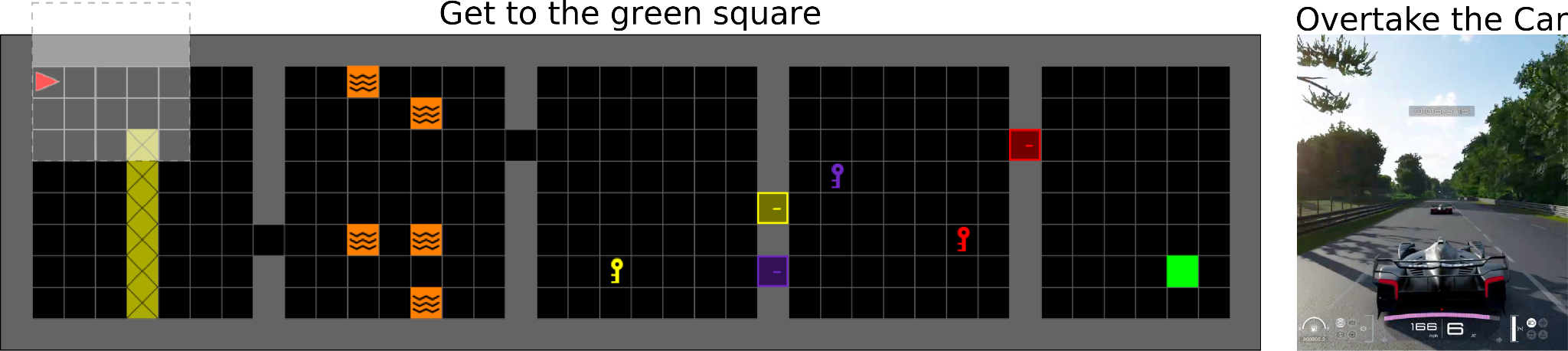
Environments often contain implicit information that can be very beneficial to expose to the neural networks (Dash et al. 2022). For tasks such as opening a door with a key or using the slipstream to overtake cars in a race, this knowledge can be critical. In RL, reward shaping is a common method for integrating this knowledge, but when used with neural nets it often changes the nature of the task. SSET offers a unique way to bring domain knowledge into RL by specifying event conditions and providing similar guarantees for preserving optimality. Our experiments demonstrate that SSET outperforms shaping alone, with the best results achieved by combining both approaches.
Improves Sample Complexity
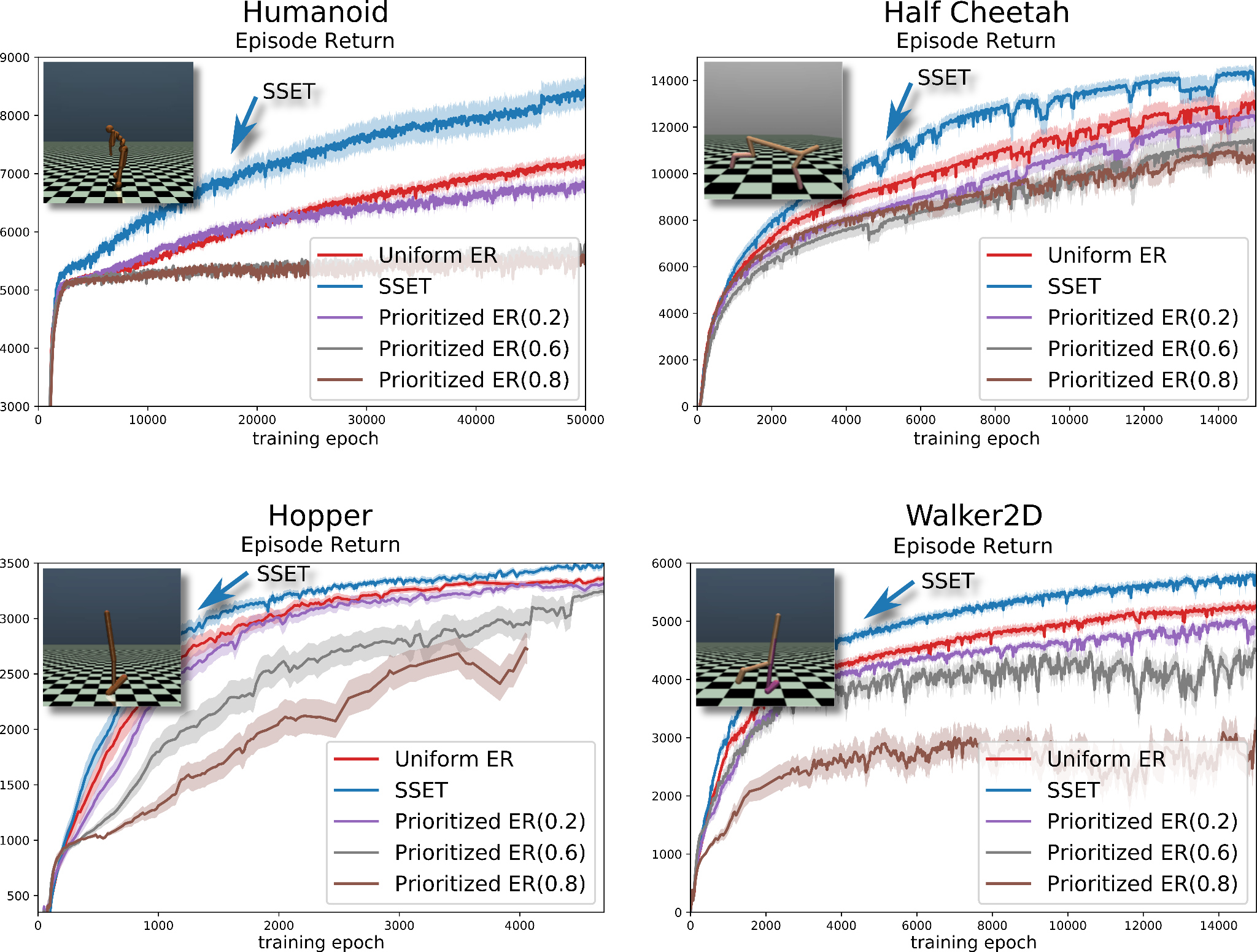
SSET outperforms various parameterizations of PER and Uniform sampling in common continuous RL benchmarks.
Through the specification of events, SSET “shapes” or controls where the Bellman backups (Dai et al. 2007) are performed by focusing on transitions that are relevant to the task. In our recent publication, Kompella et al. 2022, we showed (in theory and through several experiments) how this makes RL more efficient compared to using other approaches, including previous non-uniform sampling techniques like Prioritized Experience Replay (Schaul et al. 2015). In continuous control domains like Lunarlander and MuJoCo, which are commonly used for testing RL agents, we've achieved remarkable sample efficiency by introducing domain-agnostic events, activating when the agent approaches the goal or receives substantial rewards.
Avoids Catastrophic Forgetting

In complex domains, RL agents often have to deal with shifting distributions during training, leading to the problem of forgetting knowledge they previously learned. For instance, in a racing task, an agent learns to stay on course by avoiding negative rewards for veering off track. Initially, it might struggle, but as it improves, off-course transitions become scarce, causing it to forget how to deal with deviations from its optimal cornering strategy. This makes the agent fragile. SSET offers a remedy by introducing an event condition triggered when the agent veers off course, enhancing the agent's ability to excel in staying on track.
Super Human Performance in Gran Turismo Sport Racing Game
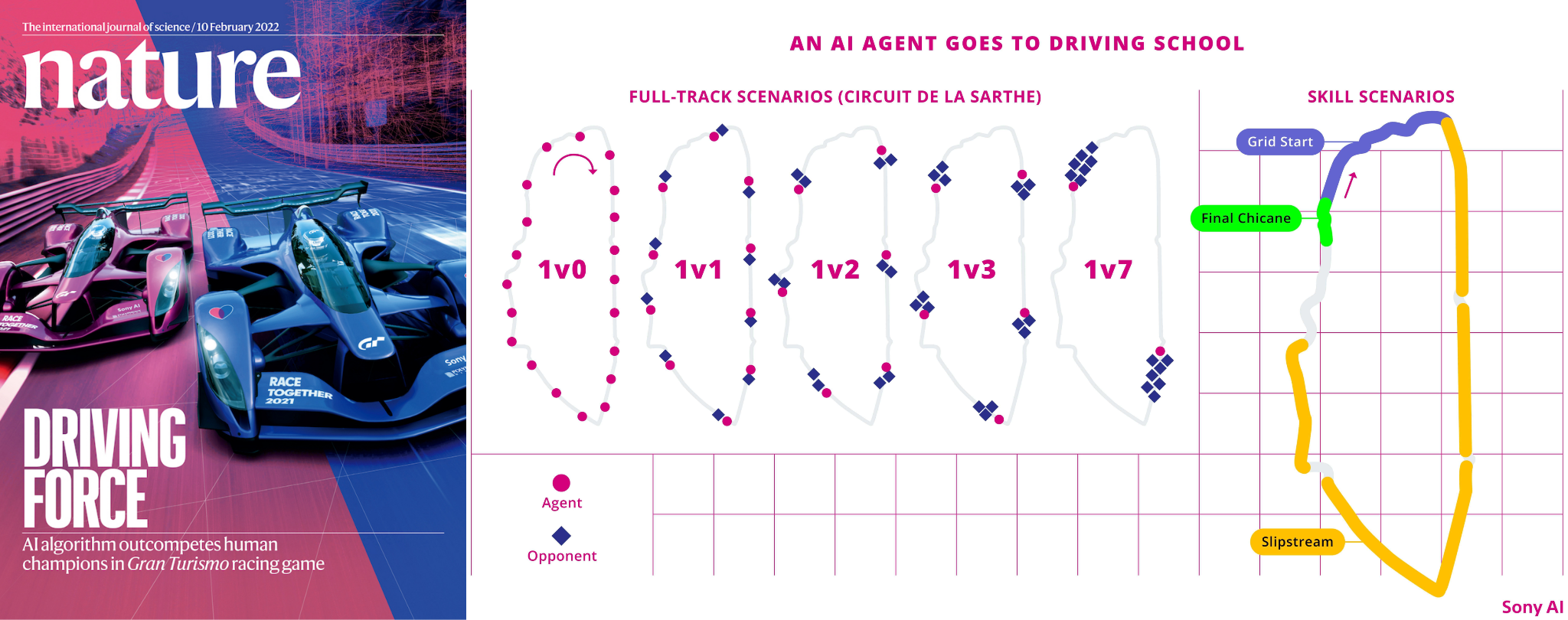
As discussed in our paper, we expanded our experiments beyond conventional RL benchmarks to PlayStation® 's high-fidelity car racing simulator, Gran Turismo™ (GT) Sport. Our RL system, employing tables for various opponent and track scenarios (ranging from 1v0 to 1v7, featuring starts, slipstream, and the final chicane), recently surpassed human esports champions (Wurman et al. 2022). The introduction of ETs played a crucial role in maintaining learning stability and safeguarding the retention of acquired skills throughout extended training periods spanning multiple days.
The Future for Event Tables
ETs and SSET provide a new way to utilize domain knowledge in AI, giving agents a way of distinguishing and learning more from their core (and more “memorable”) experiences. ETs are especially helpful in sparse reward settings where rare events, like making a pass on a racetrack, are highly correlated with good behavior. SSET provides fast learning that avoids catastrophic forgetting without adding new reward terms to already complex tasks. Looking to the future, we’re investigating ways to better automate and streamline ETs and bring the notion of memorable events to even more complex domains.
Extra Reading Material
- Link to our peer-reviewed publication: https://openreview.net/pdf?id=XejzjAjKjv
- Link to our poster: CoLLAs_Poster.pdf
- A link to a short teaser presentation: https://www.youtube.com/watch?v=knwd4zeQnxs
References
- Barto, Andrew G., Steven J. Bradtke, and Satinder P. Singh. "Learning to act using real-time dynamic programming." Artificial intelligence 72.1-2 (1995): 81-138.
- Dai, Peng, and Eric A. Hansen. "Prioritizing Bellman Backups without a Priority Queue." ICAPS. 2007.
- Dash, Tirtharaj, et al. "A review of some techniques for inclusion of domain-knowledge into deep neural networks." Scientific Reports 12.1 (2022): 1040.
- Kompella, V. R., Walsh, T., Barrett, S., Wurman, P. R., & Stone, P. (2022). Event Tables for Efficient Experience Replay. Transactions on Machine Learning Research.
- Schaul, Tom, et al. "Prioritized experience replay." arXiv preprint arXiv:1511.05952 (2015).
- Wurman, Peter R., et al. "Outracing champion Gran Turismo drivers with deep reinforcement learning." Nature 602.7896 (2022): 223-228.


