




Don’t Cross That Line! How Our AI Agent Learned Sportsmanship
Training GT Sophy to race aggressively…but not too aggressively



GT Sophy
Game AI
September 15, 2022
GT SOPHY TECHNICAL SERIES
Starting in 2020, the research and engineering team at Sony AI set out to do something that had never been done before: create an AI agent that could beat the best drivers in the world at the PlayStation® 4 game Gran Turismo™ Sport, the real driving simulator developed by Polyphony Digital. In 2021, we succeeded with Gran Turismo Sophy (GT Sophy). This series explores the technical accomplishments that made GT Sophy possible, pointing the way to future AI technologies capable of making continuous real-time decisions and embodying subjective concepts like sportsmanship.
Just over a week before the first event in which GT Sophy would go head-to-head with the best Gran Turismo racers in the world, we conducted an internal test with the latest versions of our agents against some of the best racers at Polyphony Digital (PDI). Our agents crashed into opponents to push them out of the way and engaged in overly aggressive blocking maneuvers when opponents attempted to pass. The feedback we received was that if we raced those agents in the actual event, they’d be thrown out for poor sportsmanship.
While causing collisions is never good, racers can’t completely eliminate the risk because there is always uncertainty about how opponents will behave. For example, if your opponent is ahead of you and brakes a fraction of a second earlier than you anticipate, you may be unable to avoid a collision with them. However, if you always cede ground to opponents to minimize the chance of a collision, you’ll never win. Similarly, for a racer to hold their position, some defense is required, but not in such a way that makes it impossible to be passed or that risks collisions.
A good racer strikes a balance between aggressiveness and fair play. If they are too aggressive, they are penalized in the race or, in extreme cases, disqualified. If they are too polite, they are easily beaten. Clearly, our agents were too combative.
In the week we had left before the event, we made changes to the algorithm hyperparameters, trained a new batch of agents, and ran them through rigorous tests to select the best ones. GT Sophy didn’t achieve the top team score in the July 2021 event, which was called Race Together (it would take another round of improvements to win the second Race Together event in October), but it did come close, and it certainly wasn’t disqualified for overly aggressive driving. Altogether, the agents incurred two collision infractions and one warning, while the human racers incurred one collision infraction.
While the story had a happy ending, the rapid improvements in behavior that were made in just one week illustrated just how thin the line is between an agent that wins at all costs and one that races competitively without violating racing etiquette. A key challenge in finding the right balance between competitiveness and etiquette was the fact that rules for sportsmanship norms are not precisely defined. For example, while our agent could detect when it made contact with another car, it couldn’t detect whether it was to blame for it, or if the contact was egregious enough to warrant a penalty. These rules are enforced by referees, known as stewards, who watch racing events and assign penalties for bad behavior. In addition, the competitive behavior an agent learns depends on multiple factors that interact with each other: how you define the reward function, how competent the agent is at contending with opponents, and which opponents you train the agent against.
In this blog post, we’ll break down how each of these dimensions affected the learned behavior, and how we ultimately trained agents to respect racing etiquette while remaining competitive.

At the July 2021 Race Together event, the AI agent GT Sophy faced off against some of the best human Gran Turismo players in the world.
Designing and refining the reward function In reinforcement learning (RL), a reward function numerically encodes how good an immediate outcome is from one instant to the next with a positive or negative “reward.” Positive rewards encourage behavior and negative rewards discourage behavior. Through trial and error, RL algorithms train agents to maximize the long-term accumulation of rewards. A simple way to discourage an RL agent from colliding with opponents is to penalize it with a negative reward whenever it is involved in a collision.
In our first tests against some of the best racers at PDI, we did just that: we raced agents trained with reward functions that penalized them for being involved in any collision. In these tests, we found that the agent was sometimes overly cautious around opponents. For example, it might conservatively brake around opponents, or give way when opponents approached. Such behavior could have proved disastrous in competition, especially if opponents learned how to exploit that aversion.
In early tests, the AI agent braked as it was passed (left). Later, it braked too cautiously as it tracked an opponent (right).
There are several factors that caused this behavior. One was that the agent was penalized both for collisions it caused and collisions that were caused by opponents. Naturally, this penalty incentivizes the agent to avoid opponents it might collide with, even when the opponent would likely be the one penalized by stewards.
To more clearly demonstrate this opponent avoidance effect, we trained an agent with very large penalties for collisions. When this agent was pitted against other human racers or the built-in game AI, it would pull off to the side of the road, wait for the other cars to pass, and then drive alone on the track.
Because our agent would need to be confident when driving wheel-to-wheel with the best human racers, we began exploring different ways to encode collision penalties. The goal was to only penalize the agent for collisions that it caused. If we succeeded, the agent wouldn’t be bullied off the road.
A key challenge in finding the right balance between competitiveness and etiquette was the fact that rules for sportsmanship norms are not precisely defined.
We considered a number of different ways to build these more selective rules. One direction we explored was to train a classifier on a labeled dataset of collisions with machine learning to predict which car (if any) is to blame for a collision. Unfortunately, we didn’t have enough labeled data to train such a classifier. Without sufficient data for machine learning, we handcrafted different penalty rules based on the limited data we did have as well as our conversations with stewards who judge sportsmanship in esports matches.
We explored a number of different rules to approximate the judgment of stewards when assigning fault, but all of the variations ultimately resulted in an agent that cleverly found loopholes in our reward function that allowed it to collide with an opponent without being penalized. This kind of loophole-finding is what ultimately proved to be the problem in our test race a week before the first Race Together event.
These videos show a version of the AI agent that has not yet learned to play well with others. It’s blocking aggressively and pushing opponents out of the way.
The primary change we made in that last week before the Race Together event was to use a reward function that had a small penalty for any collision and a greater penalty for especially egregious collisions. Specifically, we included three different collision penalties: the any collision penalty, the rear end penalty, and, for the race on the Circuit de la Sarthe track, the unsporting collision penalty. Each of these penalty terms were added together for a total collision penalty.
The any collision punished the agent whenever it made contact with another car. The rear end penalty penalized the agent with a value proportional to the relative (squared) speed between the agent car and the car it rear-ended. Finally, the unsporting collision penalty penalized collisions that were more likely caused by the agent’s behavior (rear-ending an opponent, sideswiping an opponent on a straightaway, or colliding in the middle of a turn).
The any collision penalty prevented GT Sophy from finding loopholes. The other two penalties were more selective, allowing us to further punish more clear-cut bad behavior without resulting in the opponent avoidance behavior that could result from enforcing a large any collision penalty.
An example of the AI agent’s improved etiquette from the second Race Together event. Sophy Verte first tries to make an outside pass, pulls back to avoid a possible collision, and later makes a clean pass.
It might seem surprising that including the any collision penalty in our final agent still produced a competitive racing agent, given that our very first tests indicated penalty-induced opponent avoidance. The reason we didn’t observe this behavior later was due to two other advances we made following our first tests: general driving competence around other cars, and a better set of opponents used to train GT Sophy.
Representing opponent cars Following our first test with PDI staff, GT Sophy’s driving competency around opponents improved in various ways. Key factors in our ability to improve the agent were the use of larger neural nets, better RL algorithms, mixed scenario training, and better opponent observation representations. With better driving competency, GT Sophy was able to safely drive closer to opponents.
We explored some of these topics in previous blog entries. Here we’ll talk about how we represented opponent cars in ways that allowed GT Sophy to safely navigate them. Opponent representation refers to how we numerically encode information about opponents and input it to a neural network.
To understand our final choice, it’s useful to discuss other representations we explored and what their limitations were. Over the course of the project, we explored three representations: a lidar-like representation, an opponent grid-cell representation centered around the agent, and a simple sorted list of opponents in front or behind, ordered by rank, closest to farthest from the agent.
Lidar-like opponent representation
The lidar-like representation was a simplified version of the real-world ranging systems used on many self-driving cars, and was provided by the game engine. From the agent’s car, a number of virtual rays were cast. Each ray measured the distance to the nearest opponent car it intersected or returned a maximum distance if it never intersected an opponent.
Unlike physical lidars, which measure the distance to any intersecting object, this version of lidar measured only the distance to opponent cars—it would be unaffected by any other physical objects in its path. This representation is illustrated in the figure below, showing a red agent car with 15 rays cast. (In practice, as many as two dozen rays would be cast.) Two of the rays intersect an opponent car and return the distance, and the others intersect no opponents and return the maximum distance. Furthermore, we see there are two blind spots: one because the opponent is situated between the path of two rays, and the other because the ray that would intersect it intersects another car first.
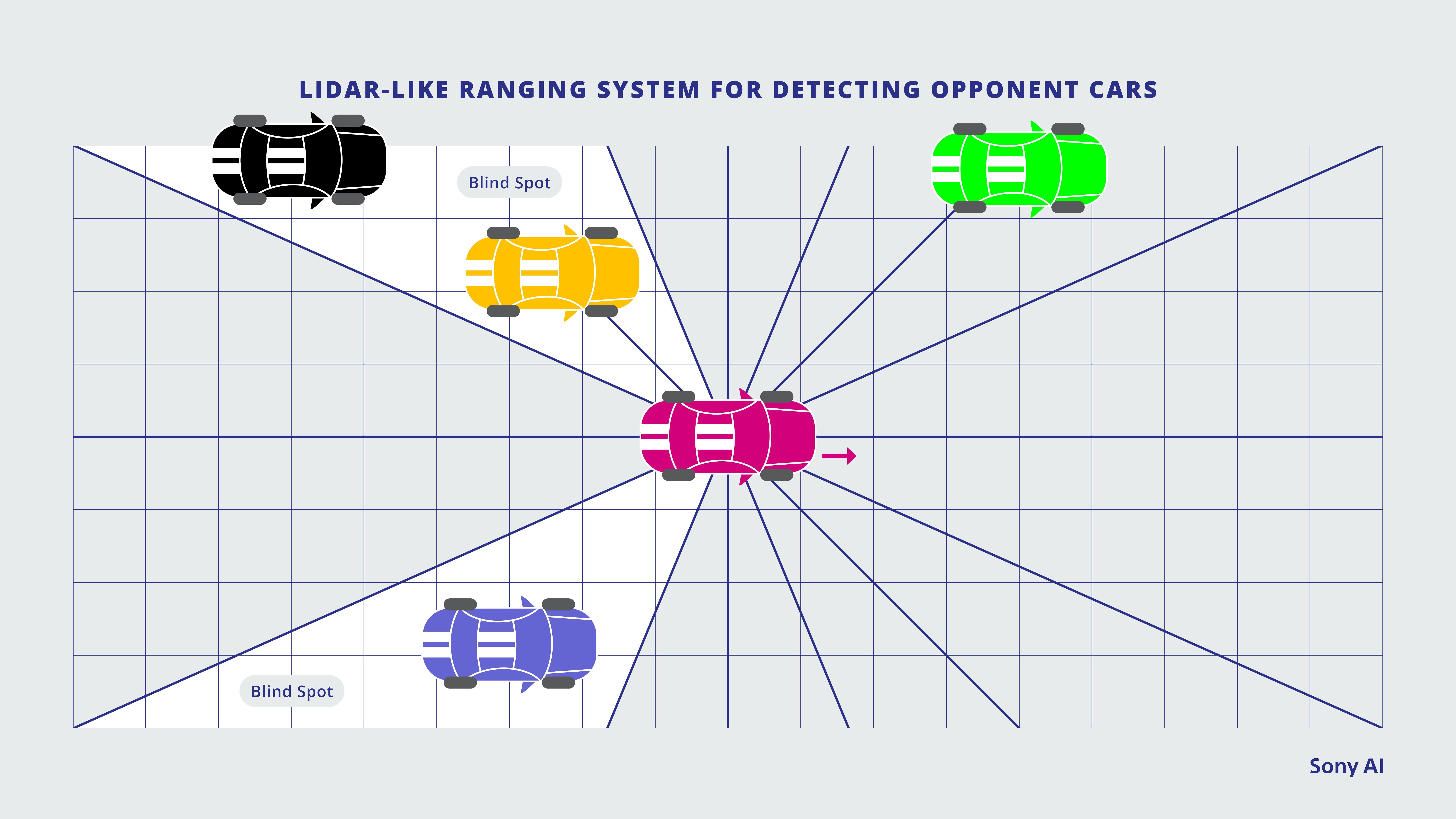
An illustration of the lidar-like opponent representation that Sony AI explored. A series of rays extend outward from the agent car, measuring the distance to opponent cars.
One of the nice properties of this lidar-like representation is that it works regardless of the number of opponents on the track. The disadvantage is that it requires a dense number of rays to avoid blind spots, and the features are very sparse: most rays won’t intersect another car. Furthermore, the distance information isn’t especially informative. For example, it doesn’t directly encode how fast opponents are moving, and being unable to determine whether an opponent is slowing down or speeding up could prove catastrophic. It also doesn’t distinguish between multiple cars. In the end, we found that the disadvantages outweighed the advantages.
Grid-cell opponent representation
The next representation we considered was a grid-like representation of opponent cars. As illustrated in the figure below, we created a spatial grid around the agent that extended a fixed distance in each direction. We varied the cell sizes to allow for more fine-grained regions. When the center of an opponent car fell inside a cell, features for that opponent were filled in with values associated with that cell. These opponent features included velocity, steering angle, relative position to the agent, etc. If no opponent was in the cell, all of its associated values would be zero. If there were more than one opponent in a cell, only the nearest of them would have their values represented.
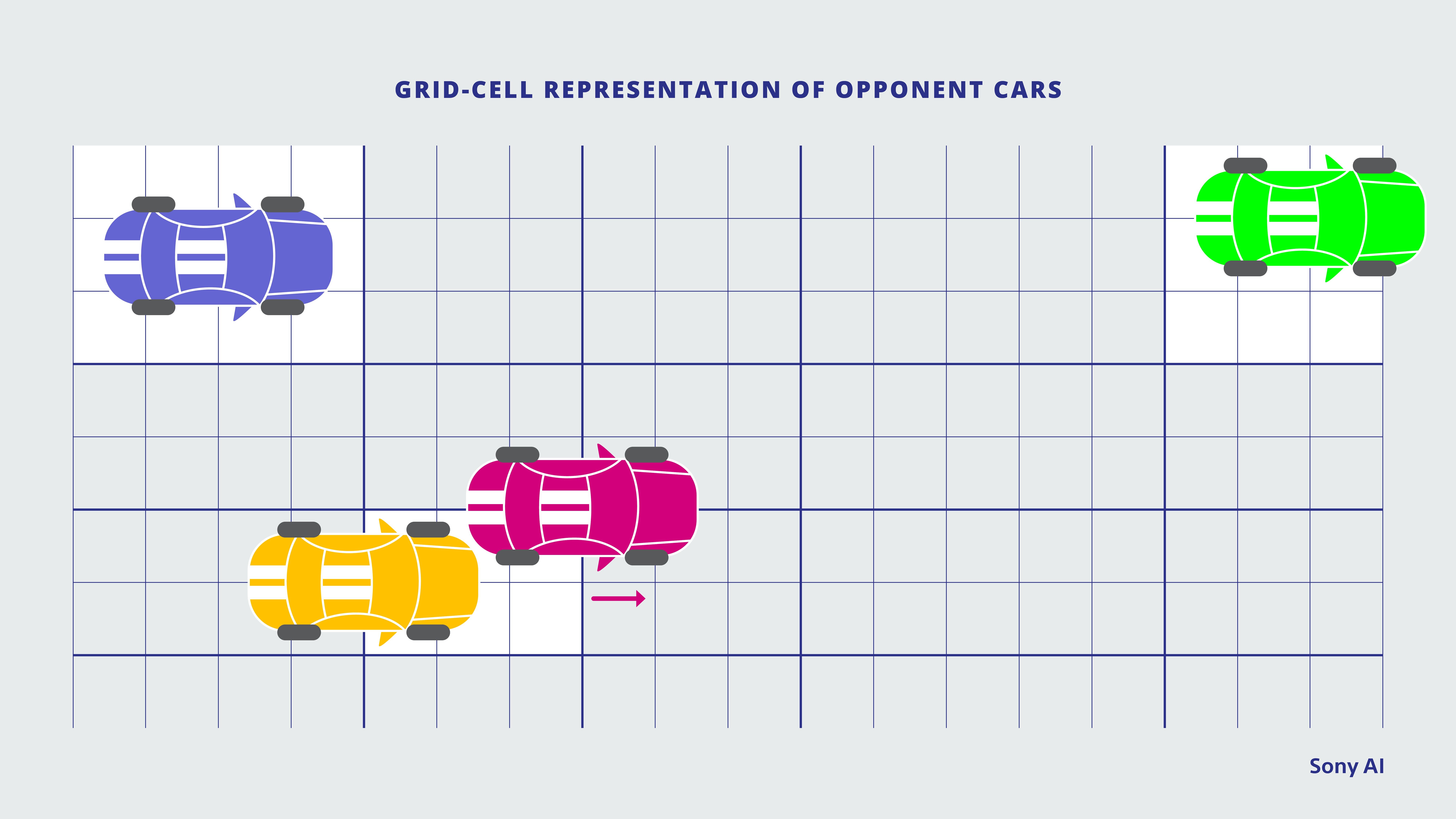
With grid-cell opponent representation, a spatial grid around the green agent car detects opponent cars when they fall within a certain grid square and relays information about them.
This representation provided a clearer way to communicate important opponent information to the agent. However, there were also some limitations to this approach. First, the agent was blind to some opponents when there was more than one opponent in a cell. Second, there were aliasing issues on the boundaries of a cell. That is, if we shifted an opponent’s position a small amount within a cell, we’d see a small change in the neural net’s prediction. However, if that same small shift to its position moved the opponent into a different cell, the output would change by a larger amount.
The aliasing issues could potentially be resolved by training with more data so the agent learns that there should not be large shifts in outputs across the boundary. However, in reinforcement learning, the agent trains on the data it naturally experiences. If the human opponents GT Sophy faced in the event drove differently than its training opponents, the aliasing effect may have remained. For these reasons, we eventually discarded this representation.
Sorted-list opponent representation
The opponent representation we ultimately used (shown in the figure below) maintained two sorted lists of opponents. The first was of opponent cars in front of the agent, and the second of opponent cars behind the agent. Both lists were sorted by opponent rank in the race, closest to farthest from the agent. To keep the agent focused, only cars within 60 meters in front of the agent or 20 meters behind the agent were included. (On the Sarthe track, the range was extended to within 75 meters in front.) Since we knew our races would consist of a maximum of eight cars, features for only seven opponents ahead or behind were allowed. If there were fewer than seven cars ahead or behind the agent, the feature values for the remaining opponent slots were filled with zeros.
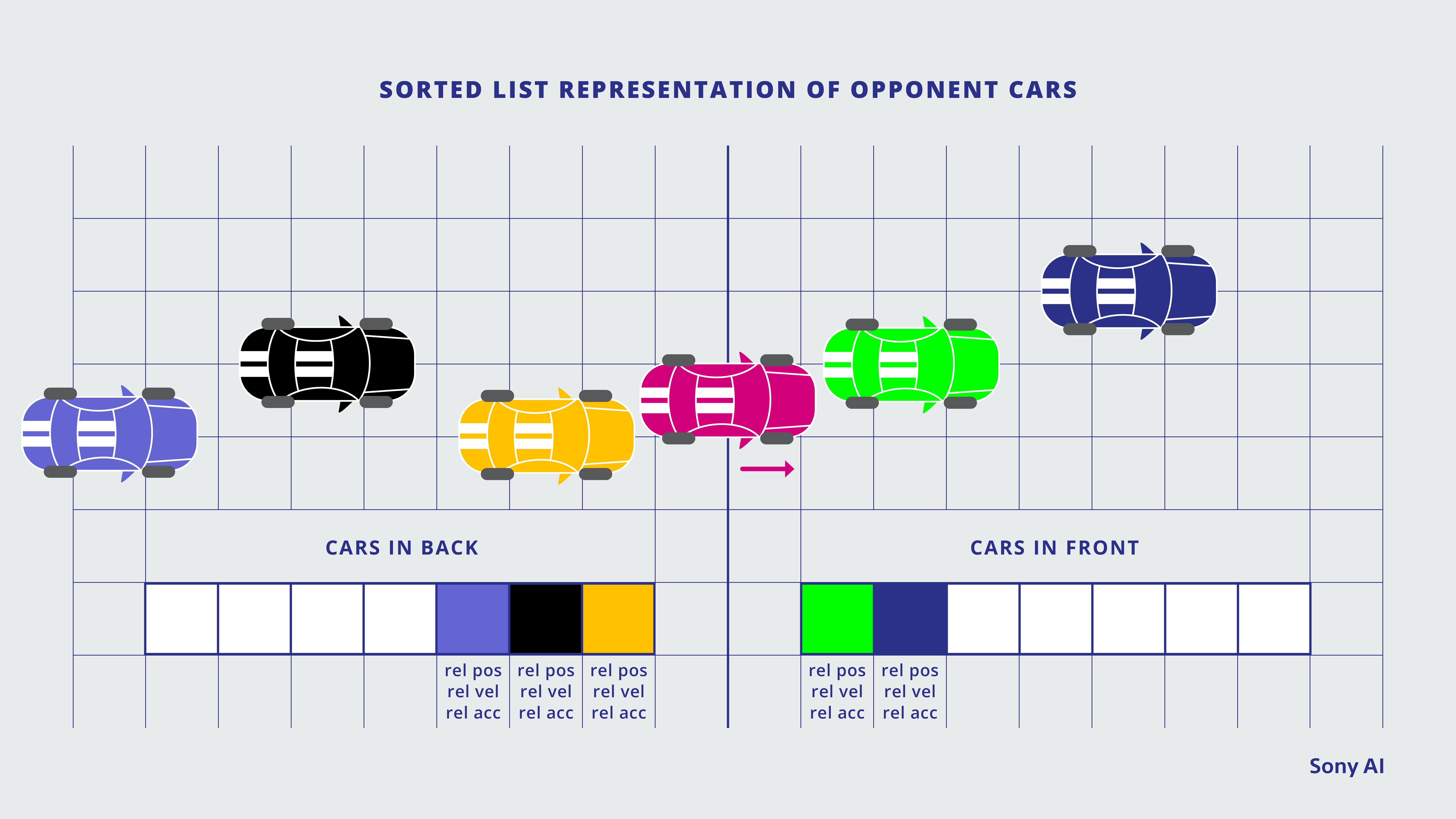
The Sony AI team ended up using a system that listed opponent cars sorted by factors like whether they were in front of or behind the agent car, their rank in the race, their distance from the agent car, etc.
This approach largely addressed the limitations of the previous representations. The agent wasn’t blind to any opponents that were close enough to interact with it, and there was limited aliasing because the rank of opponents relative to the agent, which determined the feature slots assigned to them, changed far less frequently than their spatial positions relative to the agent in the grid.
To illustrate how GT Sophy reasoned about opponents, we’ve included an interactive plot that shows how GT Sophy’s predictions change as you move the position of GT Sophy. In this example, we’ve chosen a snapshot of moments from the October Race Together event. The image on the right is a 2D representation of the position of the cars, with the pink car representing GT Sophy. The figure on the left shows the predicted Q-value for the 2D action space. Points to the left or right indicate actions to steer more to that direction, and points to the top or bottom indicate throttle and brake, respectively (with no throttle or brake in the middle). If you are not familiar with Q-values, they predict roughly how well the agent expects to do (in terms of future reward) if it takes the corresponding action. The brighter the color in the plot, the higher the Q-value and the more GT Sophy prefers that combination of actions. For example, a bright value at the top and center of the Q-value plot means GT Sophy expects to do well if it continues straight with full throttle.
In the example, we have an opponent racing side-by-side with GT Sophy in a straightaway. You will notice that if you drag the agent closer to the opponent, the agent will continue to want to drive straight. That is, GT Sophy is not acting overly averse to being close to an opponent. However, you’ll also see a stark boundary where the value would drop significantly for turning into the opponent to reflect its aversion to causing a collision.
This interactive graph demonstrates how the position of opponent cars changes the incentives of the AI agent car. Brighter colors on the “Q-value” reflect higher anticipated rewards for certain actions.
Training opponents The final element that had a significant impact on the resulting sportsmanship of the agent was the opponents used in training. In the figure below, we show how agents fared when they trained with one of three different opponent populations in a team 4v4 match against the October GT Sophy agent on Sarthe. The “built-in AI only” agents were trained with opponents controlled by the game’s built-in AI.
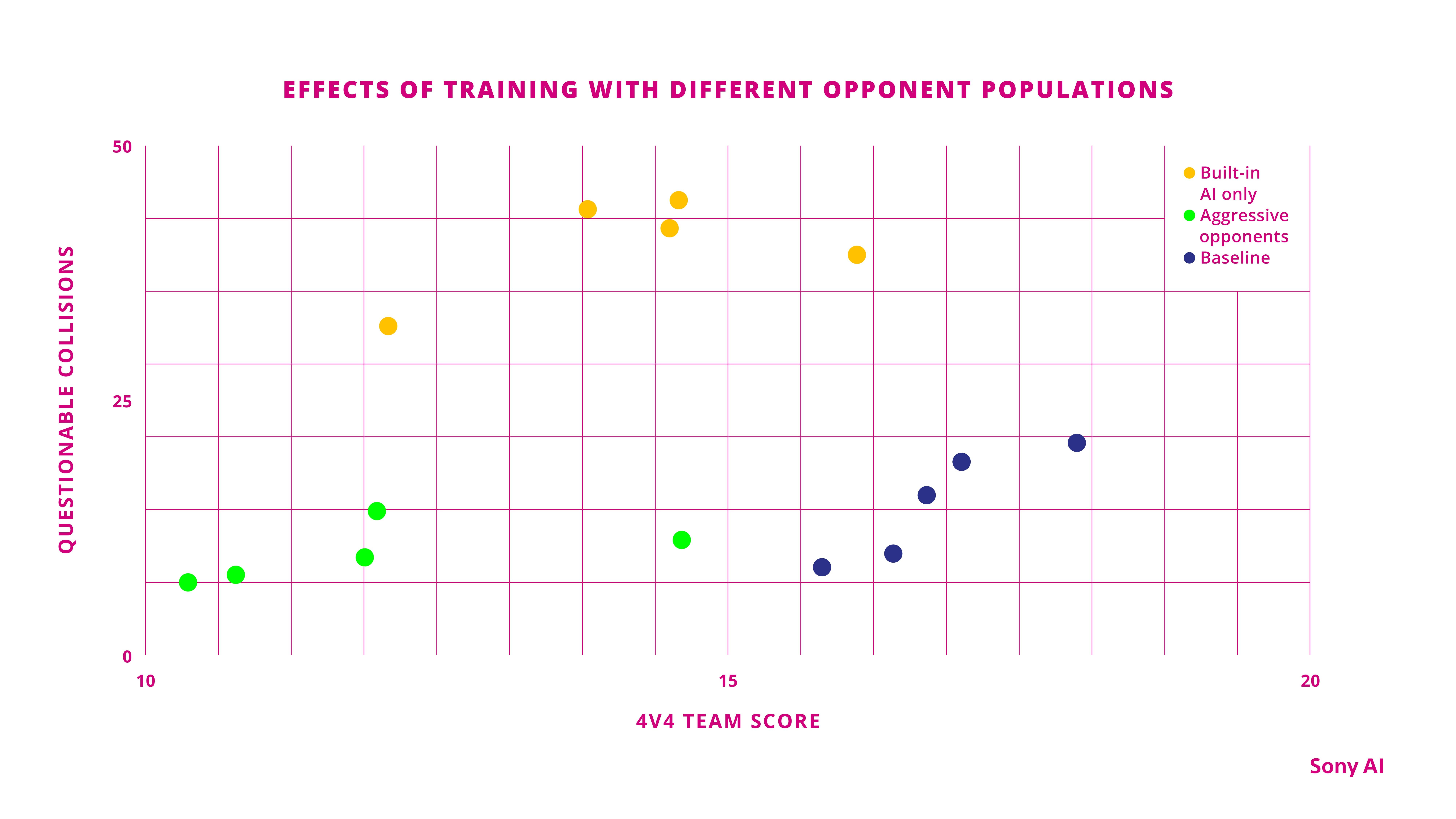
This chart shows how the AI agent fared against three different types of opponents: those using the built-in AI of Gran Turismo itself (yellow), those that were trained to race aggressively (green), and those that utilized a mixture of the built-in game AI and trained agents that were relatively well behaved (blue).
The “built-in AI only” agents were trained with opponents controlled by the game’s built-in AI. The “aggressive opponents” agents were trained with previously trained agents that were prone to cause accidents. The “baseline” agents were trained with the same diverse opponent distribution as the October GT Sophy agent (a mixture of the game’s built-in AI and other previously trained, well-behaved agents), but we used the final learned policy rather than hand-selecting the best agent, as we did for the event.
We trained five different agents from scratch for each of these three kinds of opponents, and measured their performance in terms of their team score against the October GT Sophy agent (the x-axis of the figure—a score of 19.5 would tie with the GT Sophy team), and how many collisions they may have caused (the y-axis of the figure). From a high-level perspective, we see that the baseline agents did the best against the October GT Sophy agent, both in dimensions of competitiveness and unsporting collisions. However, what’s more interesting is the way agents that trained with the other two opponent classes failed.
When we trained agents against only the game’s built-in AI, there simply wasn’t enough diversity in opponent behavior for the agents to learn how to appropriately navigate any other kind of opponent. As a consequence, the agents had middling team scores and were responsible for many collisions when they raced against the October GT Sophy agent.
When the agents were trained against aggressive opponents, they seemed to develop a kind of “learned helplessness.” That is, the agents learned from the aggressive opponents that collisions were likely when near an opponent, making it better to avoid opponents. As a result, these agents weren’t very competitive.
Due to this sensitivity to opponent populations, we manually curated the opponent populations used for training. In the future, it may be possible to make opponent selection more automatic.
Conclusion We found that in order to let GT Sophy learn to race at the pinnacle of competitiveness, we had to design a reward function that encouraged it to be assertive without being too aggressive, to make sure that it had the information it needed to anticipate and safely drive around opponents, and that it practiced against appropriate opponents.
Although our findings are framed in terms of racing etiquette, we believe that building agents that respect “soft” rules will be crucial in deploying them to environments with human interaction. For example, as it becomes more common for mobile robots to occupy the same physical spaces as people, it is crucial for them to be able to act according to the soft rules of social navigation—just as people make subtle adjustments in direction to make way for each other as they cross paths. GT Sophy is an important step in understanding how to design such agents.
Latest Blog

July 8, 2025 | Sony AI
Sights on AI: Lingjuan Lyu Discusses Her Career in Privacy-Preserving AI and Sta…
The Sony AI team is a diverse group of individuals working to accomplish one common goal: accelerate the fundamental research and development of AI and enhance human imagination an…

July 7, 2025 | Scientific Discovery, Events
Scientific Discovery: How Sony AI Is Building Tools to Empower Scientists and Pe…
At this year’s AI4X 2025, Sony AI is presenting two research projects that show how intelligent systems can augment knowledge and creativity in complex scientific research. These t…

July 1, 2025 | Sony AI
Advancing AI: Highlights from June
June was a month of real-world progress across Sony AI. We brought new models to IJCNN, revisited SXSW’s human-robot creativity panel, celebrated Peter Stone’s AAAI webinar appeara…

