



RPOSST: Testing an AI Agent for Deployment in the Real World




Game AI
December 5, 2023
Bleary-eyed engineers know the anxiety that comes with a deployment, and the importance of testing every aspect of a product before it goes to the “real world.” Will the response time be fast enough? Is there a combination of user clicks that will crash the system? However, if your product is a “black-box” deep neural network policy trained to drive simulated race cars in the Gran Turismo™ 7 (GT7) PlayStation® racing simulation game for the PS5™ console, how do you test hundreds of “good” policies and pick just one to deploy in a myriad of conditions against hundreds of thousands of users?
In February 2023, we faced this problem in the limited-time deployment of Gran Turismo Sophy™ (GT Sophy), our super-human racing agent in GT7. GT Sophy had already proven its mettle in exhibitions against world-class competition, but could we be sure it was ready for a worldwide player base? In GT7, every possible racing scenario is a potential test case — a basis for preferring one driving policy over another. Does GT Sophy drive fast enough through Turn 1 or Turn 2? Does it drive appropriately with another car ahead or behind? How does it respond to a nearby aggressive or timid opponent? Any combination of these situations could be observed in the wild. However, testing hundreds or thousands of policies under every conceivable condition is impossible.
Introducing the RPOSST Algorithm
To solve the challenge of testing countless policies in a myriad of conditions, our team at Sony AI has introduced new research in the paper, Composing Efficient, Robust Tests for Policy Selection. This research develops the Robust Population Optimization for a Small Set of Test-cases (RPOSST) algorithm to select a small set of test cases from a larger pool based on a relatively small number of sample evaluations. RPOSST “tests the test cases,” identifying groups of test cases that combine to form nearly the same sample test scores as the entire pool of test cases.
A complication of testing for a real deployment is that both the development and requirements of AI systems are iteratively improved. To track improvements across time, we need a stable test suite that can be reusable and informative across many development iterations. RPOSST fulfills this requirement by generating a static test that is robust to our uncertainty about what policies we will need to test in the future. In addition, RPOSST handles uncertainty over the relative importance of each test case in the pool. For example, imagining we could actually run each test case in the pool, would the performance around Turn 1 be weighted higher than that around Turn 2, or is passing proficiency on a straightaway more important than both? Or should performance on each of these test cases be equally weighted? The small set of test cases RPOSST selects will be robust to unlucky, or even worst-case, policy and test-case importance under our uncertainty.
Setting the Stage for RPOSST
To ground the problem, let’s assume we have some data on how five policies perform in five test cases, TC1-TC5, each a race against a different opponent type. As shown in Figure 1 with policies on the columns, test cases on the rows, and a numerical test case result at each intersection. What if we could only pick one test case? One might be tempted to pick TC5, since it is the most difficult case and differentiates the “A” student (policy 5) from all the rest. But remember, we have uncertainty over what policies we will need to test in the future (perhaps some of the “stronger” policies will be disqualified for some other reason). Therefore, we should pick a test that helps rank all the policies, separating the A’s from the B’s and the C’s. In this case, that means picking TC3 as the test case that separates the strongest and weakest policies. If we could pick two test cases, we would pick TC2 and TC4 to divide policies into three groups: weak, mediocre, and strong.
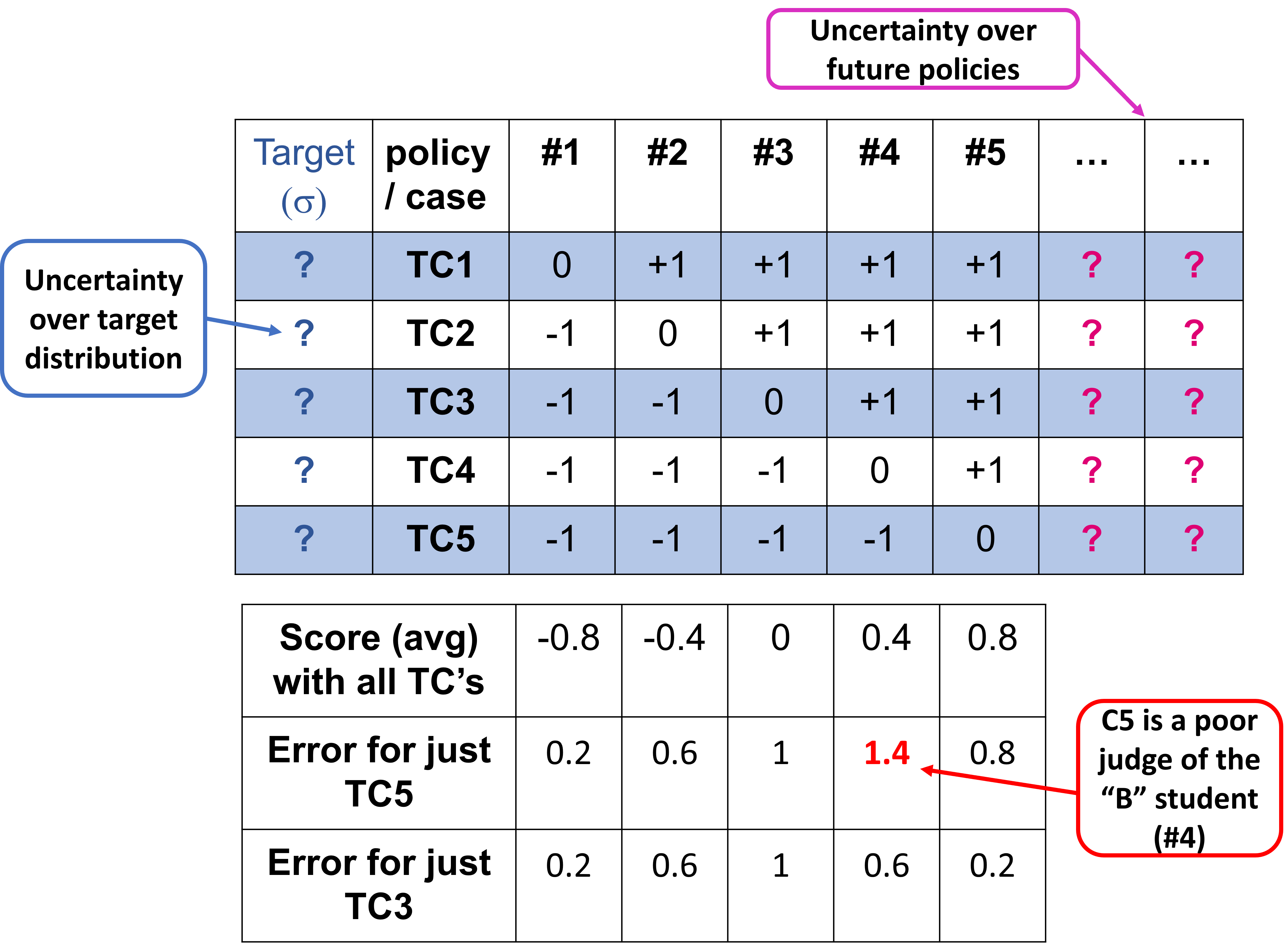
Figure 1: An example test construction problem with data from 5 policies (columns) evaluated in 5 test cases
Viewed in this light, the problem of constructing a test is actually a game played between a protagonist who constructs a test by picking rows and an antagonist who selects a policy to evaluate in an attempt to maximize the protagonist’s error. A test evaluates policies by assigning them a test score equal to a (weighted) average test case result across the selected rows. If the protagonist in the game above picks test case TC5, the antagonist can choose policy #3, which is assigned a score of -1 by TC5, but actually has an average score (under all test cases) of 0.4, leading to an error of 1.4. But if the protagonist chooses the informative TC3, now the best the antagonist can do is choose #2 or #4. Under TC3, #2 has a score of -1, while #4 has a score of +1, both leading to an error of 0.6 compared to the average scores -0.4 and +0.4, respectively. Decreasing the protagonist’s maximum error from 1.4 to 0.6 makes C3 a better choice than C5 if we can only run a single test case. That is the intuition that RPOSST exploits.
In this example, we compared the protagonist’s test scores to a uniform target distribution across all test cases, but we could have compared them against other distributions. RPOSST allows us to select test cases while being uncertain of the exact target distribution by allowing the adversary to additionally choose the target distribution.
Going Under the Hood of RPOSST
RPOSST formalizes this intuition as illustrated in Figure 2, starting with data from a small set of “tuning policies” that have been run on all the test cases we are considering. The goal for RPOSST is to find a small set of test cases (rows in the matrix) and weights on those rows, so that the test score computed from the smaller test-case set is as close as possible to the test score if we used all cases and knew the (unknown) true target distribution.
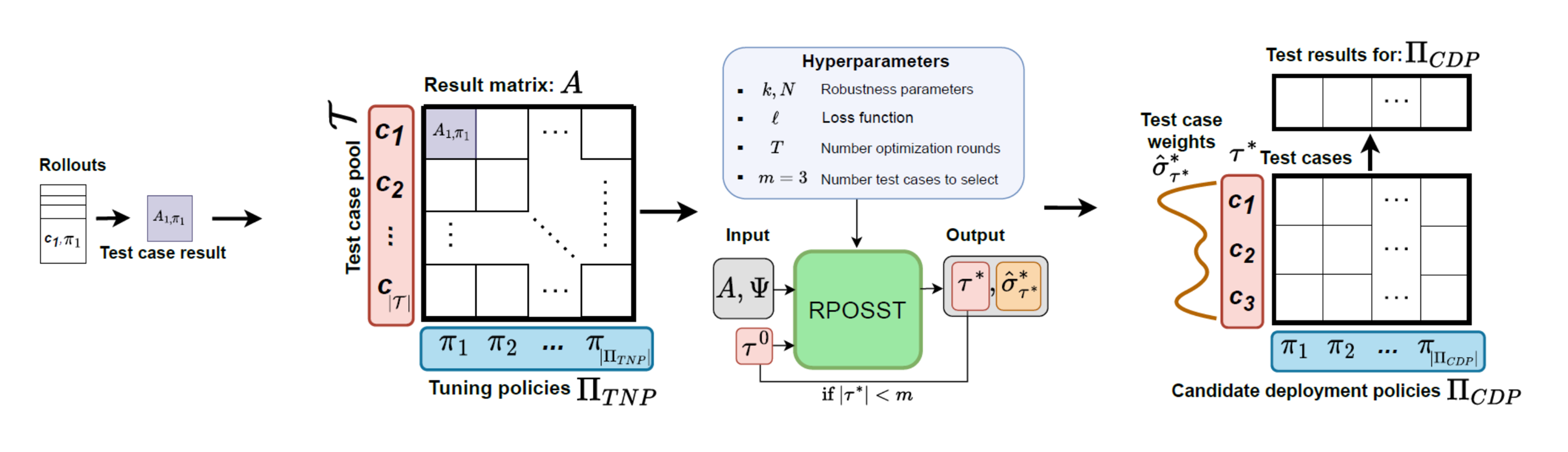
Figure 2: An overview of RPOSST
To accomplish this goal, RPOSST solves a two-player zero-sum game (Figure 3) against an adversary that picks the policies and target distribution used in each round. The protagonist starts by choosing a small set of test cases and a weight on each. The antagonist observes the test cases chosen and picks k pairs of tuning policies and target distributions from a random set of N pairs, attempting to maximize the protagonist’s error. This setup describes a k-of-N game. Before the game begins, we choose the values for k and N, which determines how much freedom the adversary has in making their choice (a large N and small k leads to a stronger adversary).
Formulating our problem as a game allows RPOSST to utilize practical algorithms for game solving and to construct tests with a formal robustness property. The resulting solution is a small test set that is robust to the worst k/N-fractile of outcomes (informally, “unlucky” outcomes) of future policies and the true target distribution. This characteristic is not shared by any existing heuristic test construction method in the literature.
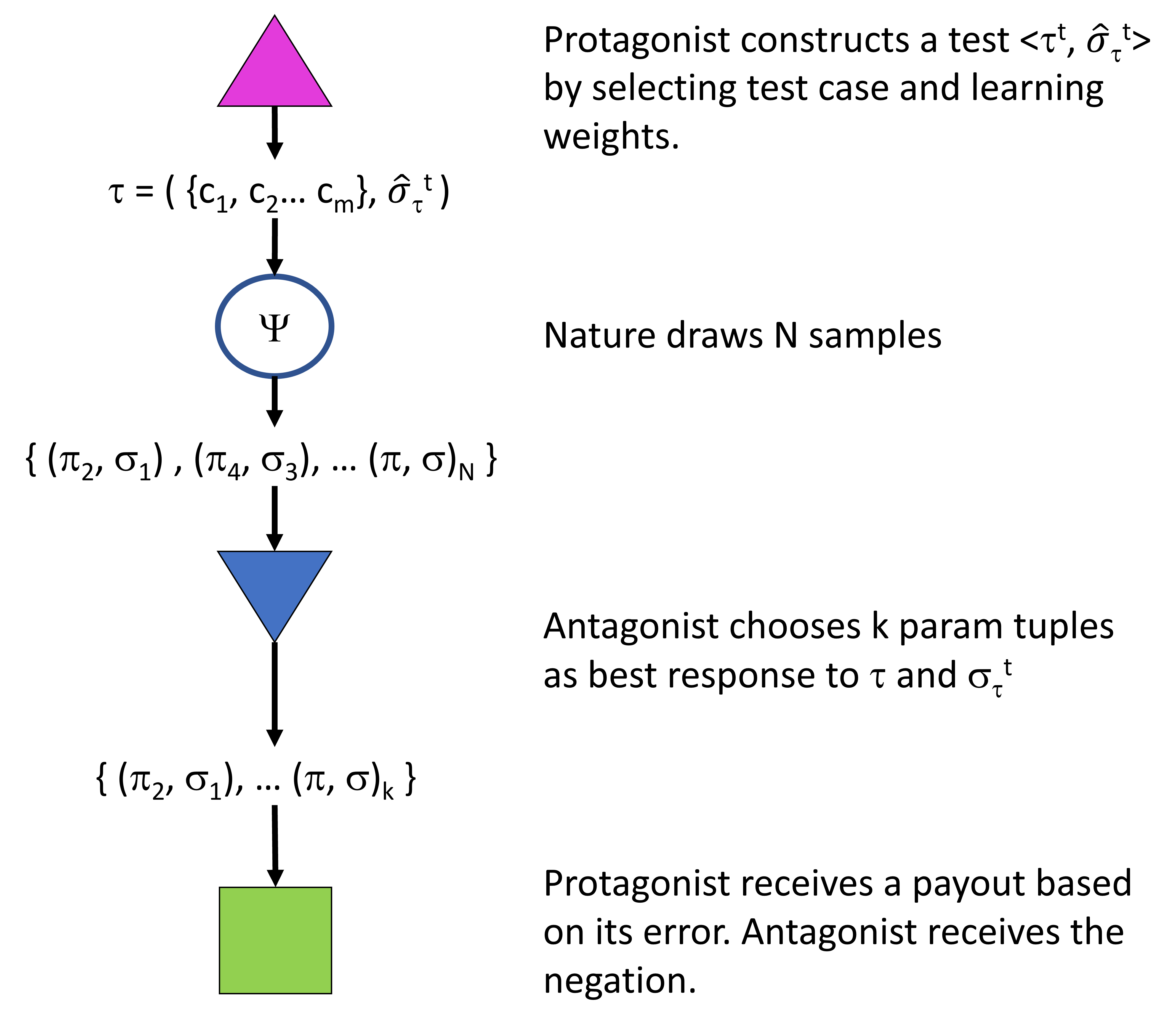
Figure 3: RPOSST test construction viewed as a two-player game.
To demonstrate RPOSST’s ability to compress tests (Figure 4), we took 46 policies trained in GT7 and raced them against each other in 20 races for each pairing. RPOSST identified rows 16 and 41 that represented the most informative combined test cases. The race against Opponent-41 (bottom row) is chosen because that policy wins and loses about half the time. Opponent-16 is a weaker policy in many ways (more blue in the top row), but it highlights the strongest policies since they perform significantly better against Opponent-16 than mediocre policies. Overall, the two test cases indicate policies 1 (a control that almost always wins), 29, and 43 (darkest blue columns) are the strongest for deployment, which agrees with the full test case data. But now future policies can be vetted with races against just two opponents instead of 46, a 23X reduction in testing time thanks to RPOSST, and without a loss of confidence from the deployment team.
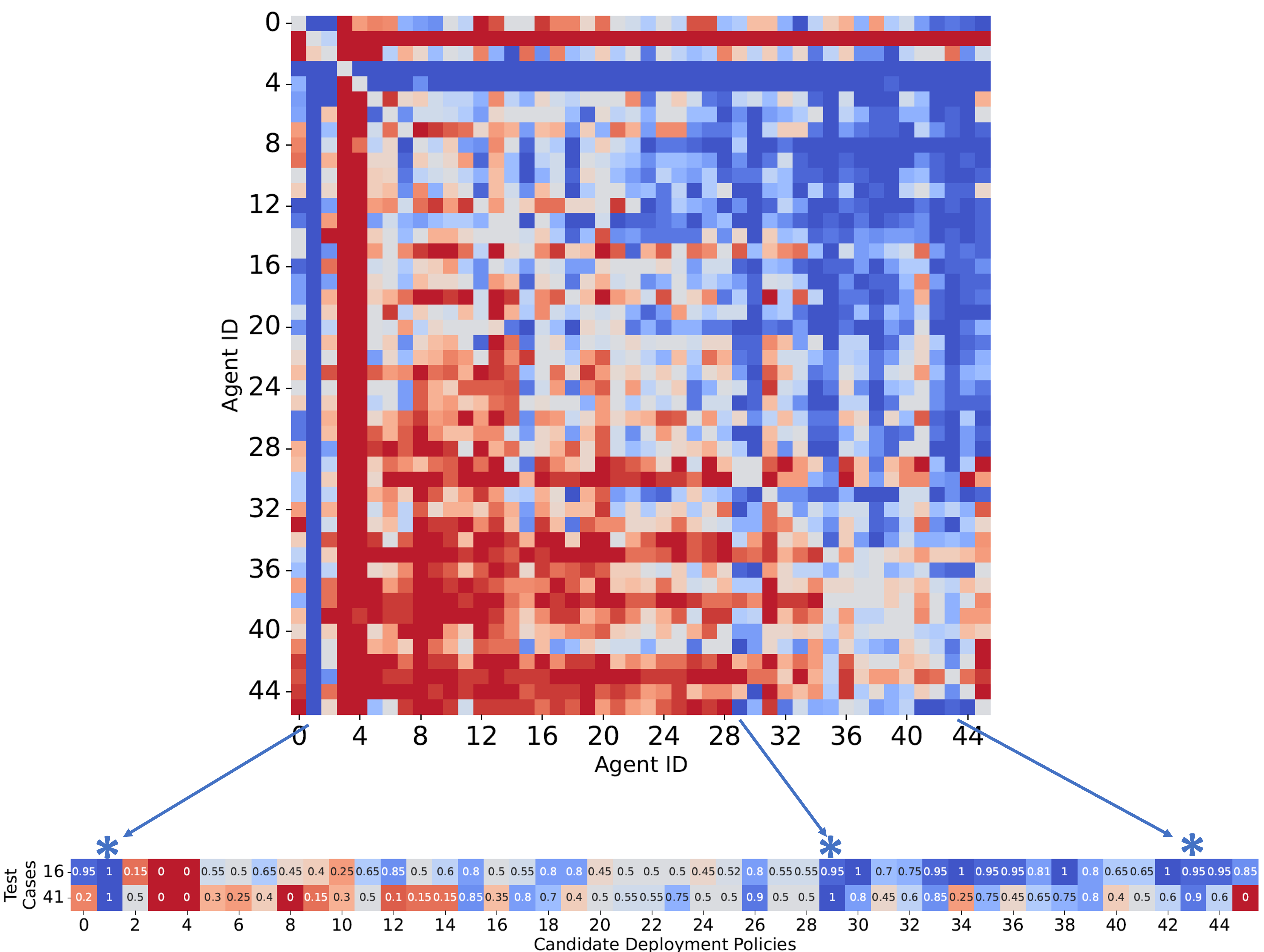
Figure 4: An example of test compression in GT where RPOSST selects 2 test cases (bottom set of rows) as a proxy for a full 46-case test.
Seeing the Future of RPOSST in Gaming and Beyond
While RPOSST can certainly help pick test cases for GT7 deployment, it has potential implications well beyond video games, for example, as a test construction algorithm picking diagnostic tests in medicine or constructing educational assessments. RPOSST’s theoretical guarantees also provide confidence that the test will be meaningful and informative even on unseen test-takers or policies, or if the deployment team changes its mind about what test cases are the most important. When you are thinking about deploying a black box into an environment with hundreds of thousands of users like GT7, that piece of mind is priceless.
For more details on RPOSST, read the full paper here: https://ai.sony/publications/Composing-Efficient-Robust-Tests-for-Policy-Selection/
Latest Blog

April 8, 2026 | Robotics, Machine Learning
Studying the Risks and Benefits of AI Companions: Researchers Discuss a New Fram…
AI systems are beginning to occupy a new role in people’s lives.For many users, conversational AI is no longer just a tool. It can behave like a friend, confidant, or romantic part…

April 1, 2026 | Sony AI
Advancing AI: Highlights from March
This month, Sony AI's work spans the foundations of generative models and the frontiers of audio and signal processing research. More than 10 papers have been accepted to ICASSP 20…

March 5, 2026 | Imaging & Sensing, Sony AI
On Writing The Principles of Diffusion Models, A Q&A With Sony AI Researcher, Je…
IntroductionDiffusion models have become a go-to approach for high-quality generation; however, the field can be challenging to navigate once the paper titles and acronyms begin to…

